 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Backtranslation in Neural Machine Translation
Paper and Code
Apr 17, 2018


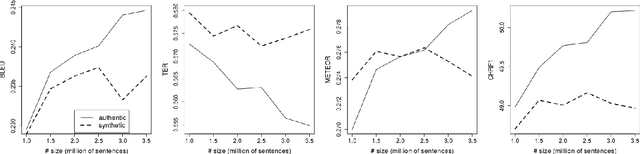
A prerequisite for training corpus-based machine translation (MT) systems -- either Statistical MT (SMT) or Neural MT (NMT) -- is the availability of high-quality parallel data. This is arguably more important today than ever before, as NMT has been shown in many studies to outperform SMT, but mostly when large parallel corpora are available; in cases where data is limited, SMT can still outperform NMT. Recently researchers have shown that back-translating monolingual data can be used to create synthetic parallel corpora, which in turn can be used in combination with authentic parallel data to train a high-quality NMT system. Given that large collections of new parallel text become available only quite rarely, backtranslation has become the norm when building state-of-the-art NMT systems, especially in resource-poor scenarios. However, we assert that there are many unknown factors regarding the actual effects of back-translated data on the translation capabilities of an NMT model. Accordingly, in this work we investigate how using back-translated data as a training corpus -- both as a separate standalone dataset as well as combined with human-generated parallel data -- affects the performance of an NMT model. We use incrementally larger amounts of back-translated data to train a range of NMT systems for German-to-English, and analyse the resulting translation performance.