 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-creation for Sign Language Processing and Machine Translation
Mar 03, 2025Sign language machine translation (SLMT) -- the task of automatically translating between sign and spoken languages or between sign languages -- is a complex task within the field of NLP. Its multi-modal and non-linear nature require the joint efforts of sign language (SL) linguists, technical experts and SL users. Effective user involvement is a challenge that can be addressed through co-creation. Co-creation has been formally defined in many fields, e.g. business, marketing, educational and others, however in NLP and in particular in SLMT there is no formal, widely accepted definition. Starting from the inception and evolution of co-creation across various fields over time, we develop a relationship typology to address the collaboration between deaf, Hard of Hearing and hearing researchers and the co-creation with SL-users. We compare this new typology to the guiding principles of participatory design for NLP. We, then, assess 110 articles from the perspective of involvement of SL users and highlight the lack of involvement of the sign language community or users in decision-making processes required for effective co-creation. Finally, we derive formal guidelines for co-creation for SLMT which take the dynamic nature of co-creation throughout the life cycle of a research project into account.
AI in Support of Diversity and Inclusion
Jan 16, 2025

In this paper, we elaborate on how AI can support diversity and inclusion and exemplify research projects conducted in that direction. We start by looking at the challenges and progress in making large language models (LLMs) more transparent, inclusive, and aware of social biases. Even though LLMs like ChatGPT have impressive abilities, they struggle to understand different cultural contexts and engage in meaningful, human like conversations. A key issue is that biases in language processing, especially in machine translation, can reinforce inequality. Tackling these biases requires a multidisciplinary approach to ensure AI promotes diversity, fairness, and inclusion. We also highlight AI's role in identifying biased content in media, which is important for improving representation. By detecting unequal portrayals of social groups, AI can help challenge stereotypes and create more inclusive technologies. Transparent AI algorithms, which clearly explain their decisions, are essential for building trust and reducing bias in AI systems. We also stress AI systems need diverse and inclusive training data. Projects like the Child Growth Monitor show how using a wide range of data can help address real world problems like malnutrition and poverty. We present a project that demonstrates how AI can be applied to monitor the role of search engines in spreading disinformation about the LGBTQ+ community. Moreover, we discuss the SignON project as an example of how technology can bridge communication gaps between hearing and deaf people, emphasizing the importance of collaboration and mutual trust in developing inclusive AI. Overall, with this paper, we advocate for AI systems that are not only effective but also socially responsible, promoting fair and inclusive interactions between humans and machines.
Guiding In-Context Learning of LLMs through Quality Estimation for Machine Translation
Jun 12, 2024The quality of output from large language models (LLMs), particularly in machine translation (MT), is closely tied to the quality of in-context examples (ICEs) provided along with the query, i.e., the text to translate. The effectiveness of these ICEs is influenced by various factors, such as the domain of the source text, the order in which the ICEs are presented, the number of these examples, and the prompt templates used. Naturally, selecting the most impactful ICEs depends on understanding how these affect the resulting translation quality, which ultimately relies on translation references or human judgment. This paper presents a novel methodology for in-context learning (ICL) that relies on a search algorithm guided by domain-specific quality estimation (QE). Leveraging the XGLM model, our methodology estimates the resulting translation quality without the need for translation references, selecting effective ICEs for MT to maximize translation quality. Our results demonstrate significant improvements over existing ICL methods and higher translation performance compared to fine-tuning a pre-trained language model (PLM), specifically mBART-50.
Tailoring Domain Adaptation for Machine Translation Quality Estimation
Apr 18, 2023
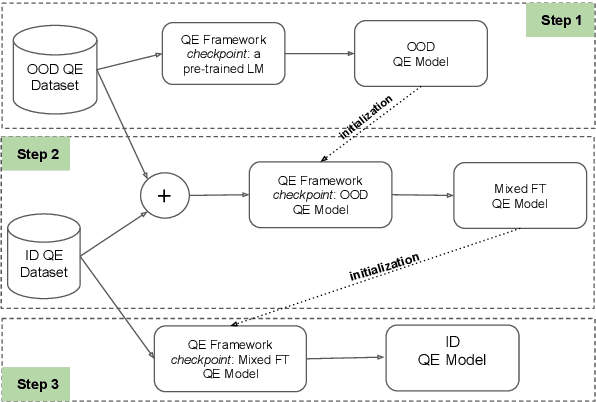


While quality estimation (QE) can play an important role in the translation process, its effectiveness relies on the availability and quality of training data. For QE in particular, high-quality labeled data is often lacking due to the high-cost and effort associated with labeling such data. Aside from the data scarcity challenge, QE models should also be generalizable, i.e., they should be able to handle data from different domains, both generic and specific. To alleviate these two main issues -- data scarcity and domain mismatch -- this paper combines domain adaptation and data augmentation within a robust QE system. Our method is to first train a generic QE model and then fine-tune it on a specific domain while retaining generic knowledge. Our results show a significant improvement for all the language pairs investigated, better cross-lingual inference, and a superior performance in zero-shot learning scenarios as compared to state-of-the-art baselines.
Evaluating the Effectiveness of Pre-trained Language Models in Predicting the Helpfulness of Online Product Reviews
Feb 19, 2023Businesses and customers can gain valuable information from product reviews. The sheer number of reviews often necessitates ranking them based on their potential helpfulness. However, only a few reviews ever receive any helpfulness votes on online marketplaces. Sorting all reviews based on the few existing votes can cause helpful reviews to go unnoticed because of the limited attention span of readers. The problem of review helpfulness prediction is even more important for higher review volumes, and newly written reviews or launched products. In this work we compare the use of RoBERTa and XLM-R language models to predict the helpfulness of online product reviews. The contributions of our work in relation to literature include extensively investigating the efficacy of state-of-the-art language models -- both monolingual and multilingual -- against a robust baseline, taking ranking metrics into account when assessing these approaches, and assessing multilingual models for the first time. We employ the Amazon review dataset for our experiments. According to our study on several product categories, multilingual and monolingual pre-trained language models outperform the baseline that utilizes random forest with handcrafted features as much as 23% in RMSE. Pre-trained language models reduce the need for complex text feature engineering. However, our results suggest that pre-trained multilingual models may not be used for fine-tuning only one language. We assess the performance of language models with and without additional features. Our results show that including additional features like product rating by the reviewer can further help the predictive methods.
Machine Translation from Signed to Spoken Languages: State of the Art and Challenges
Feb 07, 2022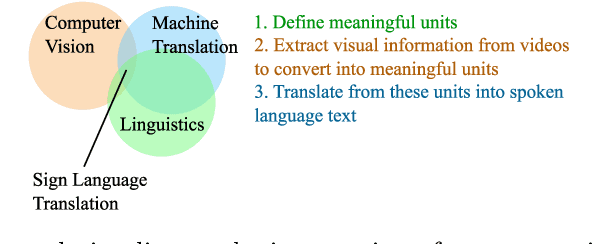
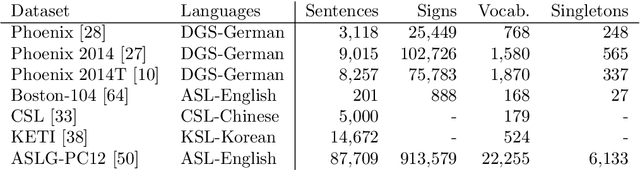

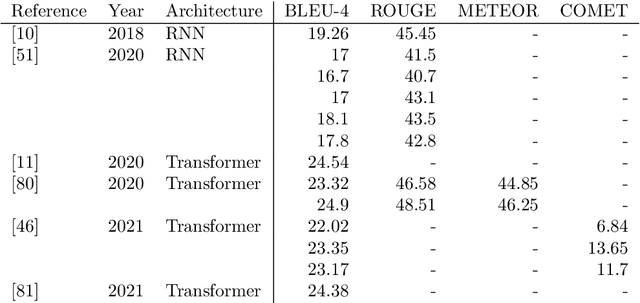
Automatic translation from signed to spoken languages is an interdisciplinary research domain, lying on the intersection of computer vision, machine translation and linguistics. Nevertheless, research in this domain is performed mostly by computer scientists in isolation. As the domain is becoming increasingly popular - the majority of scientific papers on the topic of sign language translation have been published in the past three years - we provide an overview of the state of the art as well as some required background in the different related disciplines. We give a high-level introduction to sign language linguistics and machine translation to illustrate the requirements of automatic sign language translation. We present a systematic literature review to illustrate the state of the art in the domain and then, harking back to the requirements, lay out several challenges for future research. We find that significant advances have been made on the shoulders of spoken language machine translation research. However, current approaches are often not linguistically motivated or are not adapted to the different input modality of sign languages. We explore challenges related to the representation of sign language data, the collection of datasets, the need for interdisciplinary research and requirements for moving beyond research, towards applications. Based on our findings, we advocate for interdisciplinary research and to base future research on linguistic analysis of sign languages. Furthermore, the inclusion of deaf and hearing end users of sign language translation applications in use case identification, data collection and evaluation is of the utmost importance in the creation of useful sign language translation models. We recommend iterative, human-in-the-loop, design and development of sign language translation models.
Selecting Parallel In-domain Sentences for Neural Machine Translation Using Monolingual Texts
Dec 20, 2021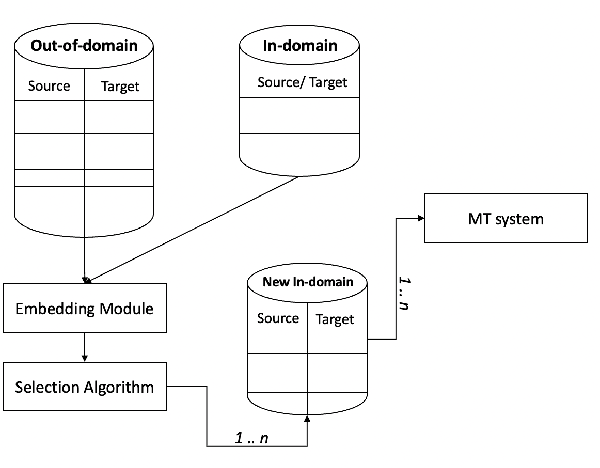

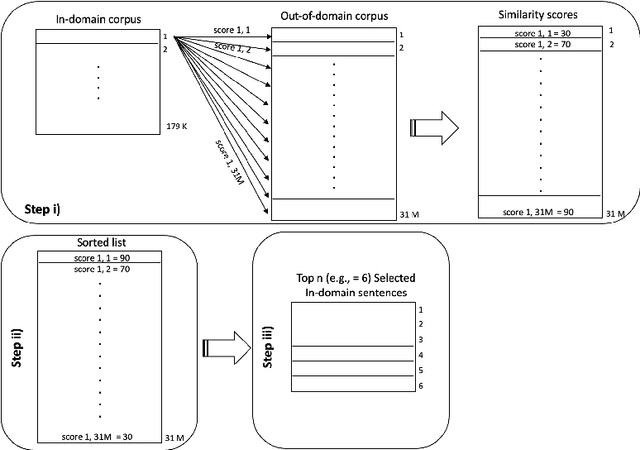

Continuously-growing data volumes lead to larger generic models. Specific use-cases are usually left out, since generic models tend to perform poorly in domain-specific cases. Our work addresses this gap with a method for selecting in-domain data from generic-domain (parallel text) corpora, for the task of machine translation. The proposed method ranks sentences in parallel general-domain data according to their cosine similarity with a monolingual domain-specific data set. We then select the top K sentences with the highest similarity score to train a new machine translation system tuned to the specific in-domain data. Our experimental results show that models trained on this in-domain data outperform models trained on generic or a mixture of generic and domain data. That is, our method selects high-quality domain-specific training instances at low computational cost and data size.
NeuTral Rewriter: A Rule-Based and Neural Approach to Automatic Rewriting into Gender-Neutral Alternatives
Sep 13, 2021
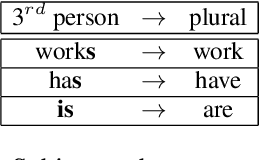


Recent years have seen an increasing need for gender-neutral and inclusive language. Within the field of NLP, there are various mono- and bilingual use cases where gender inclusive language is appropriate, if not preferred due to ambiguity or uncertainty in terms of the gender of referents. In this work, we present a rule-based and a neural approach to gender-neutral rewriting for English along with manually curated synthetic data (WinoBias+) and natural data (OpenSubtitles and Reddit) benchmarks. A detailed manual and automatic evaluation highlights how our NeuTral Rewriter, trained on data generated by the rule-based approach, obtains word error rates (WER) below 0.18% on synthetic, in-domain and out-domain test sets.
Machine Translationese: Effects of Algorithmic Bias on Linguistic Complexity in Machine Translation
Jan 30, 2021
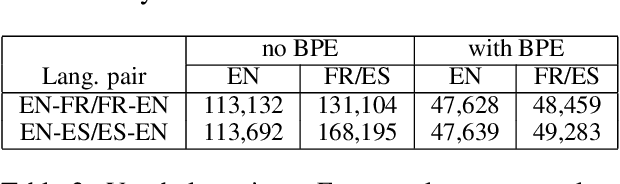
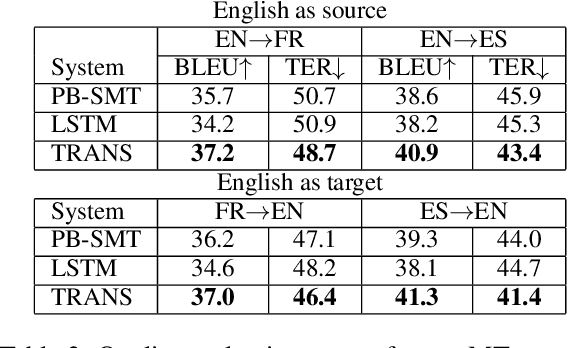
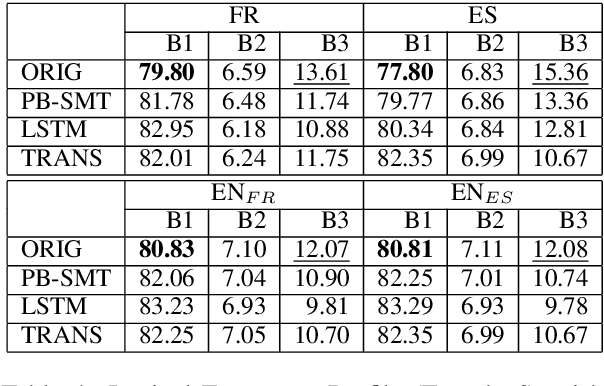
Recent studies in the field of Machine Translation (MT) and Natural Language Processing (NLP) have shown that existing models amplify biases observed in the training data. The amplification of biases in language technology has mainly been examined with respect to specific phenomena, such as gender bias. In this work, we go beyond the study of gender in MT and investigate how bias amplification might affect language in a broader sense. We hypothesize that the 'algorithmic bias', i.e. an exacerbation of frequently observed patterns in combination with a loss of less frequent ones, not only exacerbates societal biases present in current datasets but could also lead to an artificially impoverished language: 'machine translationese'. We assess the linguistic richness (on a lexical and morphological level) of translations created by different data-driven MT paradigms - phrase-based statistical (PB-SMT) and neural MT (NMT). Our experiments show that there is a loss of lexical and morphological richness in the translations produced by all investigated MT paradigms for two language pairs (EN<=>FR and EN<=>ES).
Selecting Backtranslated Data from Multiple Sources for Improved Neural Machine Translation
May 01, 2020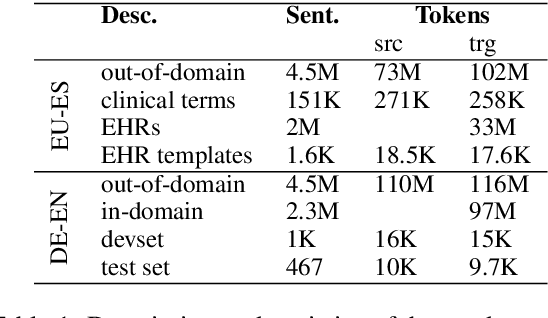
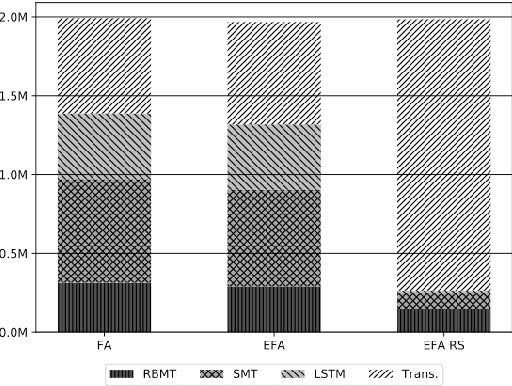

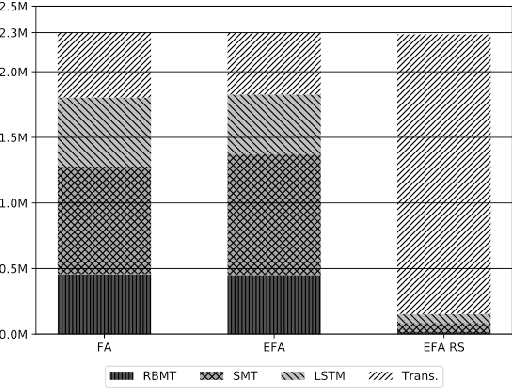
Machine translation (MT) has benefited from using synthetic training data originating from translating monolingual corpora, a technique known as backtranslation. Combining backtranslated data from different sources has led to better results than when using such data in isolation. In this work we analyse the impact that data translated with rule-based, phrase-based statistical and neural MT systems has on new MT systems. We use a real-world low-resource use-case (Basque-to-Spanish in the clinical domain) as well as a high-resource language pair (German-to-English) to test different scenarios with backtranslation and employ data selection to optimise the synthetic corpora. We exploit different data selection strategies in order to reduce the amount of data used, while at the same time maintaining high-quality MT systems. We further tune the data selection method by taking into account the quality of the MT systems used for backtranslation and lexical diversity of the resulting corpora. Our experiments show that incorporating backtranslated data from different sources can be beneficial, and that availing of data selection can yield improved performance.