 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Parallel In-domain Sentences for Neural Machine Translation Using Monolingual Texts
Paper and Code
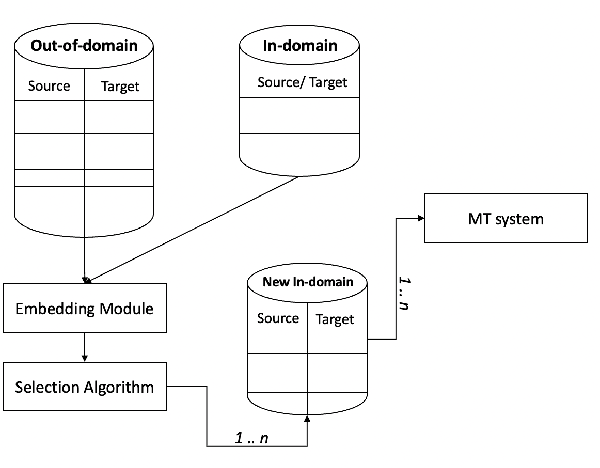

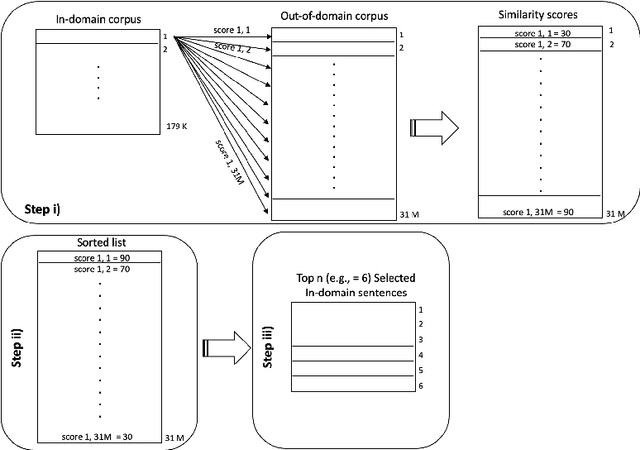

Continuously-growing data volumes lead to larger generic models. Specific use-cases are usually left out, since generic models tend to perform poorly in domain-specific cases. Our work addresses this gap with a method for selecting in-domain data from generic-domain (parallel text) corpora, for the task of machine translation. The proposed method ranks sentences in parallel general-domain data according to their cosine similarity with a monolingual domain-specific data set. We then select the top K sentences with the highest similarity score to train a new machine translation system tuned to the specific in-domain data. Our experimental results show that models trained on this in-domain data outperform models trained on generic or a mixture of generic and domain data. That is, our method selects high-quality domain-specific training instances at low computational cost and data size.