 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding In-Context Learning of LLMs through Quality Estimation for Machine Translation
Jun 12, 2024The quality of output from large language models (LLMs), particularly in machine translation (MT), is closely tied to the quality of in-context examples (ICEs) provided along with the query, i.e., the text to translate. The effectiveness of these ICEs is influenced by various factors, such as the domain of the source text, the order in which the ICEs are presented, the number of these examples, and the prompt templates used. Naturally, selecting the most impactful ICEs depends on understanding how these affect the resulting translation quality, which ultimately relies on translation references or human judgment. This paper presents a novel methodology for in-context learning (ICL) that relies on a search algorithm guided by domain-specific quality estimation (QE). Leveraging the XGLM model, our methodology estimates the resulting translation quality without the need for translation references, selecting effective ICEs for MT to maximize translation quality. Our results demonstrate significant improvements over existing ICL methods and higher translation performance compared to fine-tuning a pre-trained language model (PLM), specifically mBART-50.
Tailoring Domain Adaptation for Machine Translation Quality Estimation
Apr 18, 2023While quality estimation (QE) can play an important role in the translation process, its effectiveness relies on the availability and quality of training data. For QE in particular, high-quality labeled data is often lacking due to the high-cost and effort associated with labeling such data. Aside from the data scarcity challenge, QE models should also be generalizable, i.e., they should be able to handle data from different domains, both generic and specific. To alleviate these two main issues -- data scarcity and domain mismatch -- this paper combines domain adaptation and data augmentation within a robust QE system. Our method is to first train a generic QE model and then fine-tune it on a specific domain while retaining generic knowledge. Our results show a significant improvement for all the language pairs investigated, better cross-lingual inference, and a superior performance in zero-shot learning scenarios as compared to state-of-the-art baselines.
Selecting Parallel In-domain Sentences for Neural Machine Translation Using Monolingual Texts
Dec 20, 2021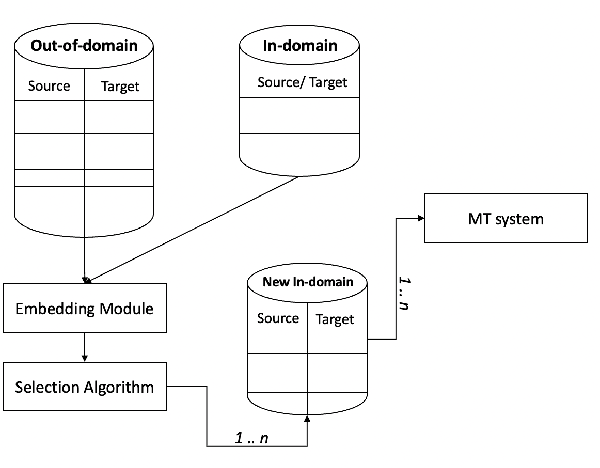

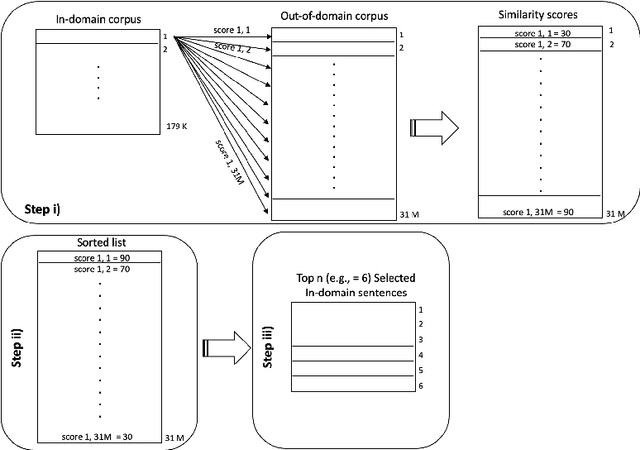

Continuously-growing data volumes lead to larger generic models. Specific use-cases are usually left out, since generic models tend to perform poorly in domain-specific cases. Our work addresses this gap with a method for selecting in-domain data from generic-domain (parallel text) corpora, for the task of machine translation. The proposed method ranks sentences in parallel general-domain data according to their cosine similarity with a monolingual domain-specific data set. We then select the top K sentences with the highest similarity score to train a new machine translation system tuned to the specific in-domain data. Our experimental results show that models trained on this in-domain data outperform models trained on generic or a mixture of generic and domain data. That is, our method selects high-quality domain-specific training instances at low computational cost and data size.
Applications of Artificial Intelligence in Live Action Role-Playing Games
Aug 25, 2020
Live Action Role-Playing (LARP) games and similar experiences are becoming a popular game genre. Here, we discuss how artificial intelligence techniques, particularly those commonly used in AI for Games, could be applied to LARP. We discuss the specific properties of LARP that make it a surprisingly suitable application field, and provide a brief overview of some existing approaches. We then outline several directions where utilizing AI seems beneficial, by both making LARPs easier to organize, and by enhancing the player experience with elements not possible without AI.