 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Trust We Survive: Emergent Trust Learning
Mar 18, 2026We introduce Emergent Trust Learning (ETL), a lightweight, trust-based control algorithm that can be plugged into existing AI agents. It enables these to reach cooperation in competitive game environments under shared resources. Each agent maintains a compact internal trust state, which modulates memory, exploration, and action selection. ETL requires only individual rewards and local observations and incurs negligible computational and communication overhead. We evaluate ETL in three environments: In a grid-based resource world, trust-based agents reduce conflicts and prevent long-term resource depletion while achieving competitive individual returns. In a hierarchical Tower environment with strong social dilemmas and randomised floor assignments, ETL sustains high survival rates and recovers cooperation even after extended phases of enforced greed. In the Iterated Prisoner's Dilemma, the algorithm generalises to a strategic meta-game, maintaining cooperation with reciprocal opponents while avoiding long-term exploitation by defectors. Code will be released upon publication.
Agentic Large Language Models, a survey
Mar 29, 2025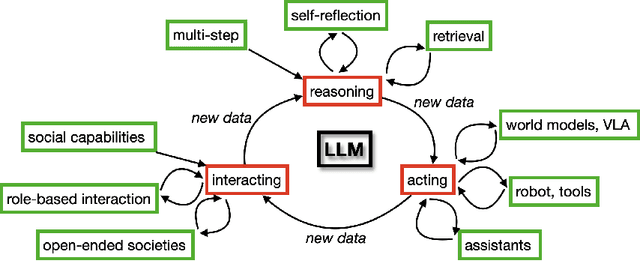

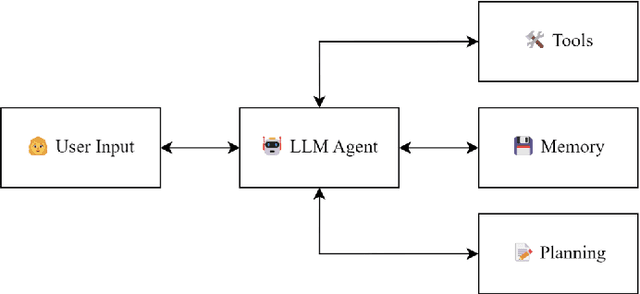
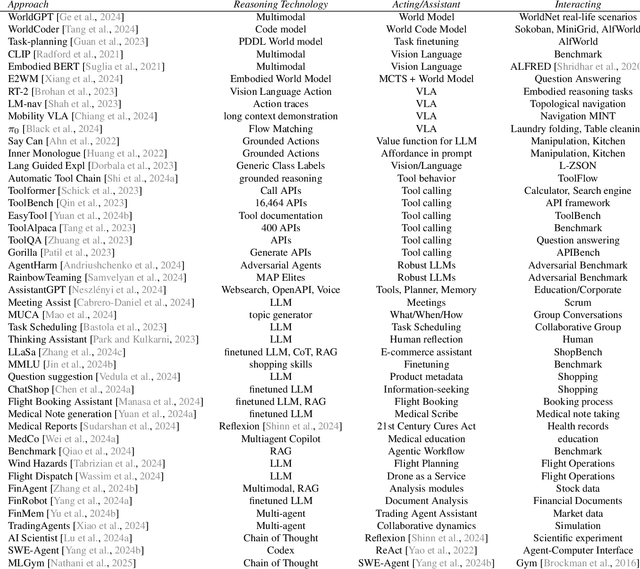
There is great interest in agentic LLMs, large language models that act as agents. We review the growing body of work in this area and provide a research agenda. Agentic LLMs are LLMs that (1) reason, (2) act, and (3) interact. We organize the literature according to these three categories. The research in the first category focuses on reasoning, reflection, and retrieval, aiming to improve decision making; the second category focuses on action models, robots, and tools, aiming for agents that act as useful assistants; the third category focuses on multi-agent systems, aiming for collaborative task solving and simulating interaction to study emergent social behavior. We find that works mutually benefit from results in other categories: retrieval enables tool use, reflection improves multi-agent collaboration, and reasoning benefits all categories. We discuss applications of agentic LLMs and provide an agenda for further research. Important applications are in medical diagnosis, logistics and financial market analysis. Meanwhile, self-reflective agents playing roles and interacting with one another augment the process of scientific research itself. Further, agentic LLMs may provide a solution for the problem of LLMs running out of training data: inference-time behavior generates new training states, such that LLMs can keep learning without needing ever larger datasets. We note that there is risk associated with LLM assistants taking action in the real world, while agentic LLMs are also likely to benefit society.
Playing Pokémon Red via Deep Reinforcement Learning
Feb 27, 2025

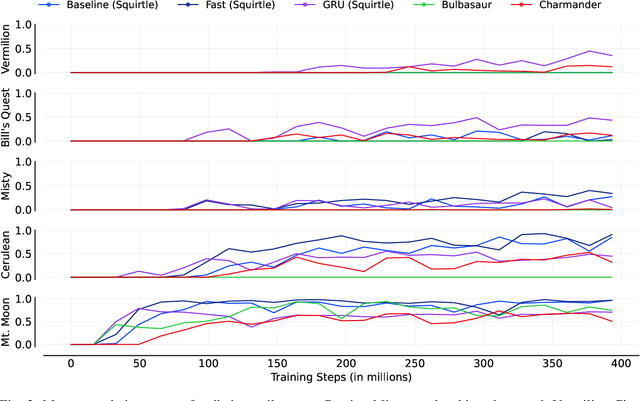

Pok\'emon Red, a classic Game Boy JRPG, presents significant challenges as a testbed for agents, including multi-tasking, long horizons of tens of thousands of steps, hard exploration, and a vast array of potential policies. We introduce a simplistic environment and a Deep Reinforcement Learning (DRL) training methodology, demonstrating a baseline agent that completes an initial segment of the game up to completing Cerulean City. Our experiments include various ablations that reveal vulnerabilities in reward shaping, where agents exploit specific reward signals. We also discuss limitations and argue that games like Pok\'emon hold strong potential for future research on Large Language Model agents, hierarchical training algorithms, and advanced exploration methods. Source Code: https://github.com/MarcoMeter/neroRL/tree/poke_red
Cascading CMA-ES Instances for Generating Input-diverse Solution Batches
Feb 19, 2025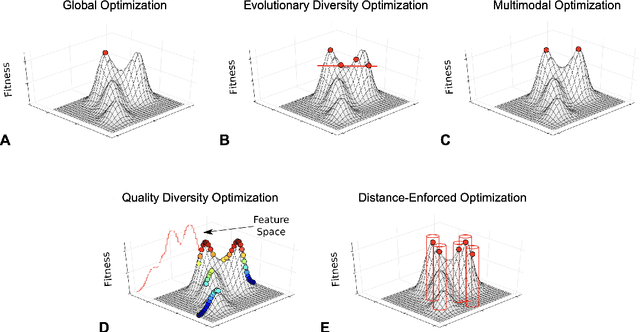
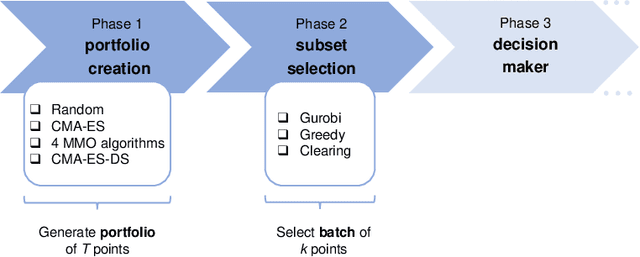
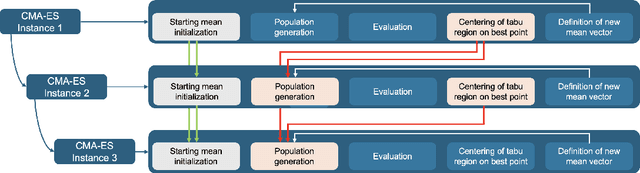
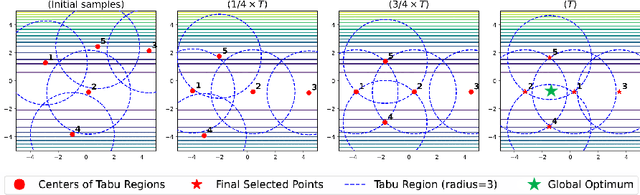
Rather than obtaining a single good solution for a given optimization problem, users often seek alternative design choices, because the best-found solution may perform poorly with respect to additional objectives or constraints that are difficult to capture into the modeling process. Aiming for batches of diverse solutions of high quality is often desirable, as it provides flexibility to accommodate post-hoc user preferences. At the same time, it is crucial that the quality of the best solution found is not compromised. One particular problem setting balancing high quality and diversity is fixing the required minimum distance between solutions while simultaneously obtaining the best possible fitness. Recent work by Santoni et al. [arXiv 2024] revealed that this setting is not well addressed by state-of-the-art algorithms, performing in par or worse than pure random sampling. Driven by this important limitation, we propose a new approach, where parallel runs of the covariance matrix adaptation evolution strategy (CMA-ES) inherit tabu regions in a cascading fashion. We empirically demonstrate that our CMA-ES-Diversity Search (CMA-ES-DS) algorithm generates trajectories that allow to extract high-quality solution batches that respect a given minimum distance requirement, clearly outperforming those obtained from off-the-shelf random sampling, multi-modal optimization algorithms, and standard CMA-ES.
Illuminating the Diversity-Fitness Trade-Off in Black-Box Optimization
Aug 29, 2024



In real-world applications, users often favor structurally diverse design choices over one high-quality solution. It is hence important to consider more solutions that decision-makers can compare and further explore based on additional criteria. Alongside the existing approaches of evolutionary diversity optimization, quality diversity, and multimodal optimization, this paper presents a fresh perspective on this challenge by considering the problem of identifying a fixed number of solutions with a pairwise distance above a specified threshold while maximizing their average quality. We obtain first insight into these objectives by performing a subset selection on the search trajectories of different well-established search heuristics, whether specifically designed with diversity in mind or not. We emphasize that the main goal of our work is not to present a new algorithm but to look at the problem in a more fundamental and theoretically tractable way by asking the question: What trade-off exists between the minimum distance within batches of solutions and the average quality of their fitness? These insights also provide us with a way of making general claims concerning the properties of optimization problems that shall be useful in turn for benchmarking algorithms of the approaches enumerated above. A possibly surprising outcome of our empirical study is the observation that naive uniform random sampling establishes a very strong baseline for our problem, hardly ever outperformed by the search trajectories of the considered heuristics. We interpret these results as a motivation to develop algorithms tailored to produce diverse solutions of high average quality.
World Models Increase Autonomy in Reinforcement Learning
Aug 20, 2024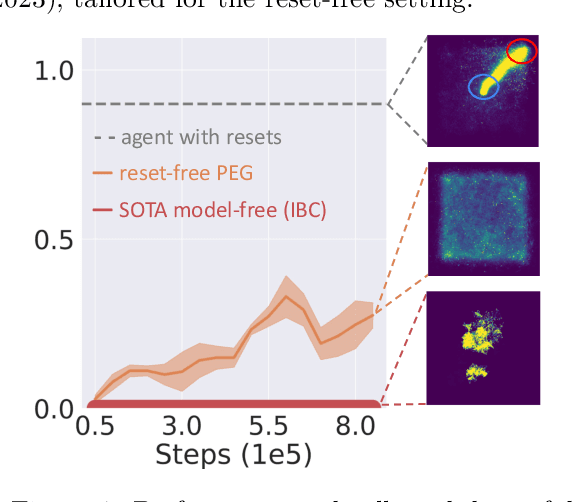
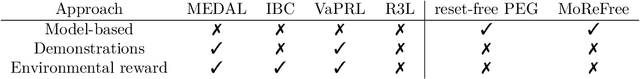
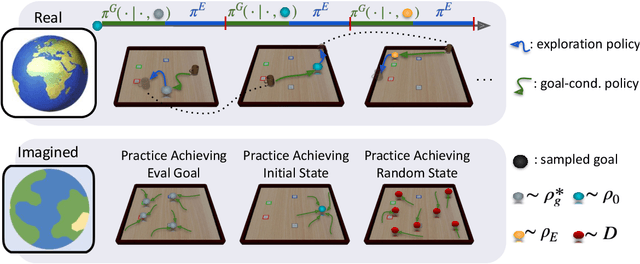

Reinforcement learning (RL) is an appealing paradigm for training intelligent agents, enabling policy acquisition from the agent's own autonomously acquired experience. However, the training process of RL is far from automatic, requiring extensive human effort to reset the agent and environments. To tackle the challenging reset-free setting, we first demonstrate the superiority of model-based (MB) RL methods in such setting, showing that a straightforward adaptation of MBRL can outperform all the prior state-of-the-art methods while requiring less supervision. We then identify limitations inherent to this direct extension and propose a solution called model-based reset-free (MoReFree) agent, which further enhances the performance. MoReFree adapts two key mechanisms, exploration and policy learning, to handle reset-free tasks by prioritizing task-relevant states. It exhibits superior data-efficiency across various reset-free tasks without access to environmental reward or demonstrations while significantly outperforming privileged baselines that require supervision. Our findings suggest model-based methods hold significant promise for reducing human effort in RL. Website: https://sites.google.com/view/morefree
Memory Gym: Partially Observable Challenges to Memory-Based Agents in Endless Episodes
Sep 29, 2023Memory Gym introduces a unique benchmark designed to test Deep Reinforcement Learning agents, specifically comparing Gated Recurrent Unit (GRU) against Transformer-XL (TrXL), on their ability to memorize long sequences, withstand noise, and generalize. It features partially observable 2D environments with discrete controls, namely Mortar Mayhem, Mystery Path, and Searing Spotlights. These originally finite environments are extrapolated to novel endless tasks that act as an automatic curriculum, drawing inspiration from the car game ``I packed my bag". These endless tasks are not only beneficial for evaluating efficiency but also intriguingly valuable for assessing the effectiveness of approaches in memory-based agents. Given the scarcity of publicly available memory baselines, we contribute an implementation driven by TrXL and Proximal Policy Optimization. This implementation leverages TrXL as episodic memory using a sliding window approach. In our experiments on the finite environments, TrXL demonstrates superior sample efficiency in Mystery Path and outperforms in Mortar Mayhem. However, GRU is more efficient on Searing Spotlights. Most notably, in all endless tasks, GRU makes a remarkable resurgence, consistently outperforming TrXL by significant margins.
Believable Minecraft Settlements by Means of Decentralised Iterative Planning
Sep 19, 2023



Procedural city generation that focuses on believability and adaptability to random terrain is a difficult challenge in the field of Procedural Content Generation (PCG). Dozens of researchers compete for a realistic approach in challenges such as the Generative Settlement Design in Minecraft (GDMC), in which our method has won the 2022 competition. This was achieved through a decentralised, iterative planning process that is transferable to similar generation processes that aims to produce "organic" content procedurally.
Models Matter: The Impact of Single-Step Retrosynthesis on Synthesis Planning
Aug 10, 2023



Retrosynthesis consists of breaking down a chemical compound recursively step-by-step into molecular precursors until a set of commercially available molecules is found with the goal to provide a synthesis route. Its two primary research directions, single-step retrosynthesis prediction, which models the chemical reaction logic, and multi-step synthesis planning, which tries to find the correct sequence of reactions, are inherently intertwined. Still, this connection is not reflected in contemporary research. In this work, we combine these two major research directions by applying multiple single-step retrosynthesis models within multi-step synthesis planning and analyzing their impact using public and proprietary reaction data. We find a disconnection between high single-step performance and potential route-finding success, suggesting that single-step models must be evaluated within synthesis planning in the future. Furthermore, we show that the commonly used single-step retrosynthesis benchmark dataset USPTO-50k is insufficient as this evaluation task does not represent model performance and scalability on larger and more diverse datasets. For multi-step synthesis planning, we show that the choice of the single-step model can improve the overall success rate of synthesis planning by up to +28% compared to the commonly used baseline model. Finally, we show that each single-step model finds unique synthesis routes, and differs in aspects such as route-finding success, the number of found synthesis routes, and chemical validity, making the combination of single-step retrosynthesis prediction and multi-step synthesis planning a crucial aspect when developing future methods.
Two-Memory Reinforcement Learning
Apr 23, 2023



While deep reinforcement learning has shown important empirical success, it tends to learn relatively slow due to slow propagation of rewards information and slow update of parametric neural networks. Non-parametric episodic memory, on the other hand, provides a faster learning alternative that does not require representation learning and uses maximum episodic return as state-action values for action selection. Episodic memory and reinforcement learning both have their own strengths and weaknesses. Notably, humans can leverage multiple memory systems concurrently during learning and benefit from all of them. In this work, we propose a method called Two-Memory reinforcement learning agent (2M) that combines episodic memory and reinforcement learning to distill both of their strengths. The 2M agent exploits the speed of the episodic memory part and the optimality and the generalization capacity of the reinforcement learning part to complement each other. Our experiments demonstrate that the 2M agent is more data efficient and outperforms both pure episodic memory and pure reinforcement learning, as well as a state-of-the-art memory-augmented RL agent. Moreover, the proposed approach provides a general framework that can be used to combine any episodic memory agent with other off-policy reinforcement learning algorithms.