 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying Pokémon Red via Deep Reinforcement Learning
Feb 27, 2025Pok\'emon Red, a classic Game Boy JRPG, presents significant challenges as a testbed for agents, including multi-tasking, long horizons of tens of thousands of steps, hard exploration, and a vast array of potential policies. We introduce a simplistic environment and a Deep Reinforcement Learning (DRL) training methodology, demonstrating a baseline agent that completes an initial segment of the game up to completing Cerulean City. Our experiments include various ablations that reveal vulnerabilities in reward shaping, where agents exploit specific reward signals. We also discuss limitations and argue that games like Pok\'emon hold strong potential for future research on Large Language Model agents, hierarchical training algorithms, and advanced exploration methods. Source Code: https://github.com/MarcoMeter/neroRL/tree/poke_red
Memory Gym: Partially Observable Challenges to Memory-Based Agents in Endless Episodes
Sep 29, 2023Memory Gym introduces a unique benchmark designed to test Deep Reinforcement Learning agents, specifically comparing Gated Recurrent Unit (GRU) against Transformer-XL (TrXL), on their ability to memorize long sequences, withstand noise, and generalize. It features partially observable 2D environments with discrete controls, namely Mortar Mayhem, Mystery Path, and Searing Spotlights. These originally finite environments are extrapolated to novel endless tasks that act as an automatic curriculum, drawing inspiration from the car game ``I packed my bag". These endless tasks are not only beneficial for evaluating efficiency but also intriguingly valuable for assessing the effectiveness of approaches in memory-based agents. Given the scarcity of publicly available memory baselines, we contribute an implementation driven by TrXL and Proximal Policy Optimization. This implementation leverages TrXL as episodic memory using a sliding window approach. In our experiments on the finite environments, TrXL demonstrates superior sample efficiency in Mystery Path and outperforms in Mortar Mayhem. However, GRU is more efficient on Searing Spotlights. Most notably, in all endless tasks, GRU makes a remarkable resurgence, consistently outperforming TrXL by significant margins.
Improving Bidding and Playing Strategies in the Trick-Taking game Wizard using Deep Q-Networks
May 27, 2022
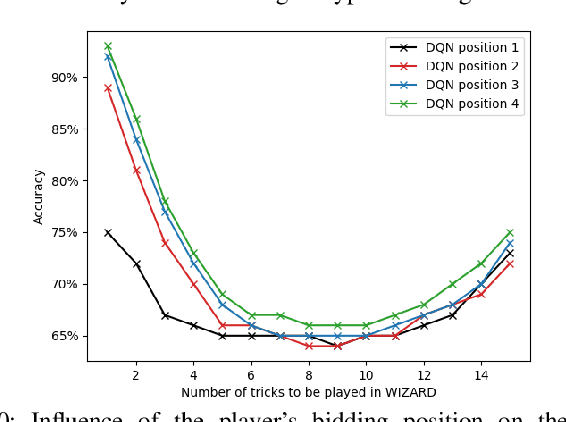
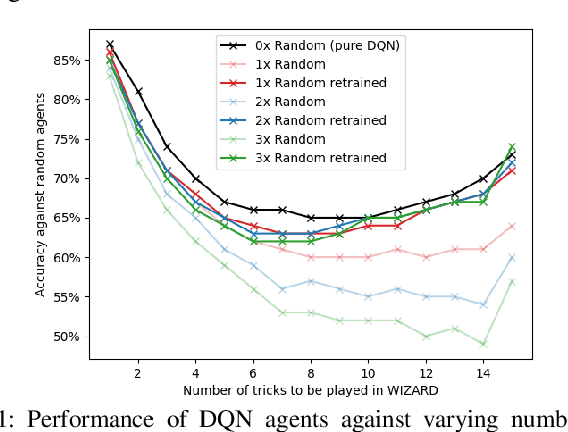
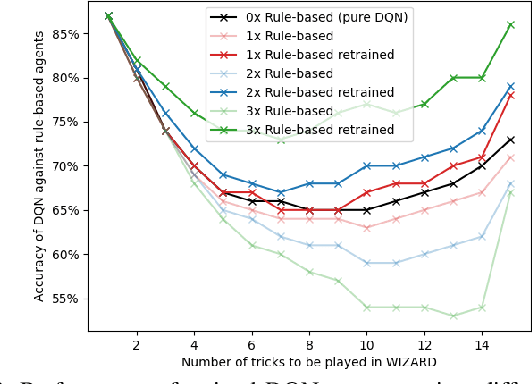
In this work, the trick-taking game Wizard with a separate bidding and playing phase is modeled by two interleaved partially observable Markov decision processes (POMDP). Deep Q-Networks (DQN) are used to empower self-improving agents, which are capable of tackling the challenges of a highly non-stationary environment. To compare algorithms between each other, the accuracy between bid and trick count is monitored, which strongly correlates with the actual rewards and provides a well-defined upper and lower performance bound. The trained DQN agents achieve accuracies between 66% and 87% in self-play, leaving behind both a random baseline and a rule-based heuristic. The conducted analysis also reveals a strong information asymmetry concerning player positions during bidding. To overcome the missing Markov property of imperfect-information games, a long short-term memory (LSTM) network is implemented to integrate historic information into the decision-making process. Additionally, a forward-directed tree search is conducted by sampling a state of the environment and thereby turning the game into a perfect information setting. To our surprise, both approaches do not surpass the performance of the basic DQN agent.
On the Verge of Solving Rocket League using Deep Reinforcement Learning and Sim-to-sim Transfer
May 24, 2022
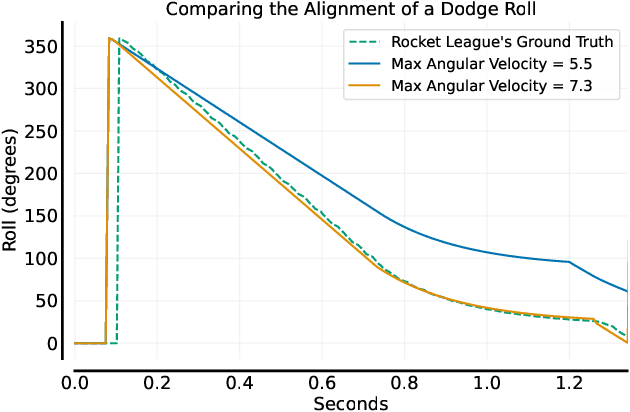
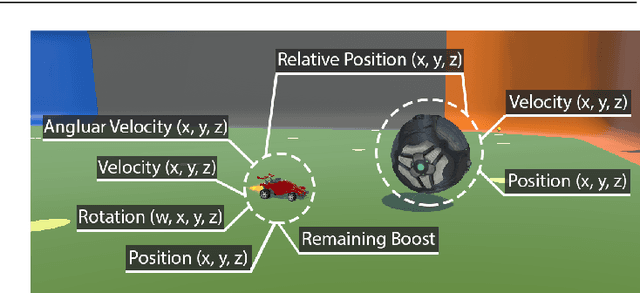
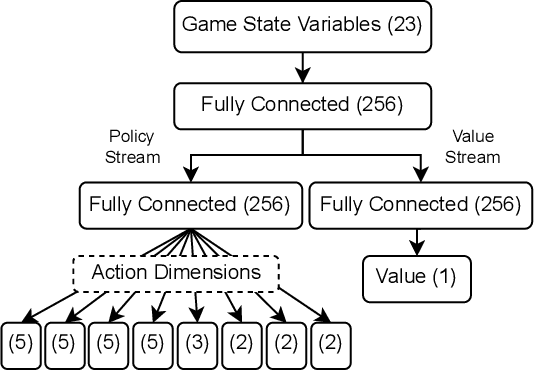
Autonomously trained agents that are supposed to play video games reasonably well rely either on fast simulation speeds or heavy parallelization across thousands of machines running concurrently. This work explores a third way that is established in robotics, namely sim-to-real transfer, or if the game is considered a simulation itself, sim-to-sim transfer. In the case of Rocket League, we demonstrate that single behaviors of goalies and strikers can be successfully learned using Deep Reinforcement Learning in the simulation environment and transferred back to the original game. Although the implemented training simulation is to some extent inaccurate, the goalkeeping agent saves nearly 100% of its faced shots once transferred, while the striking agent scores in about 75% of cases. Therefore, the trained agent is robust enough and able to generalize to the target domain of Rocket League.
Generalization, Mayhems and Limits in Recurrent Proximal Policy Optimization
May 23, 2022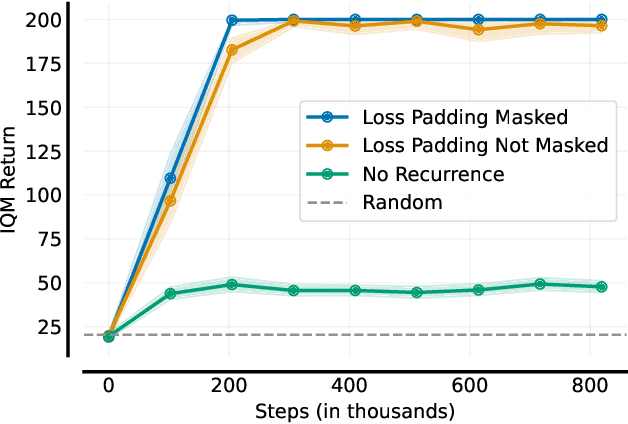
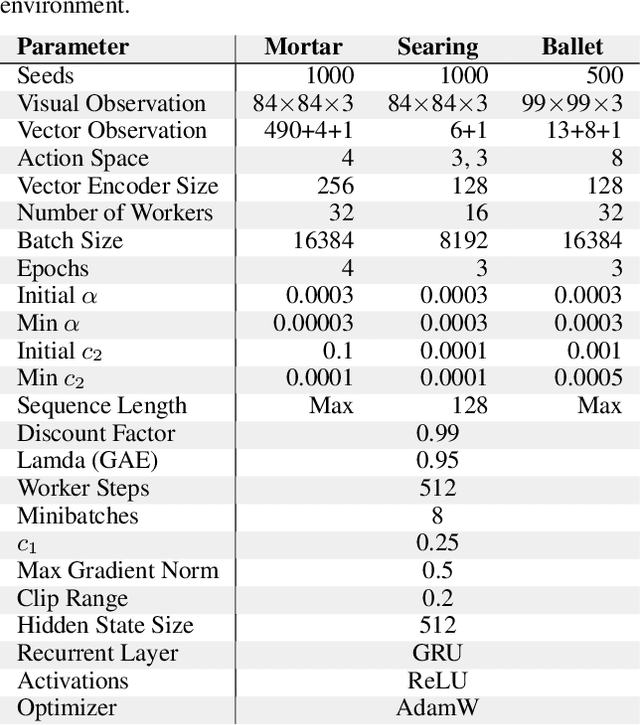
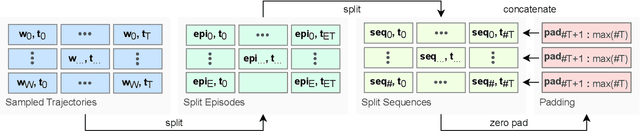
At first sight it may seem straightforward to use recurrent layers in Deep Reinforcement Learning algorithms to enable agents to make use of memory in the setting of partially observable environments. Starting from widely used Proximal Policy Optimization (PPO), we highlight vital details that one must get right when adding recurrence to achieve a correct and efficient implementation, namely: properly shaping the neural net's forward pass, arranging the training data, correspondingly selecting hidden states for sequence beginnings and masking paddings for loss computation. We further explore the limitations of recurrent PPO by benchmarking the contributed novel environments Mortar Mayhem and Searing Spotlights that challenge the agent's memory beyond solely capacity and distraction tasks. Remarkably, we can demonstrate a transition to strong generalization in Mortar Mayhem when scaling the number of training seeds, while the agent does not succeed on Searing Spotlights, which seems to be a tough challenge for memory-based agents.
Obstacle Tower Without Human Demonstrations: How Far a Deep Feed-Forward Network Goes with Reinforcement Learning
Apr 01, 2020
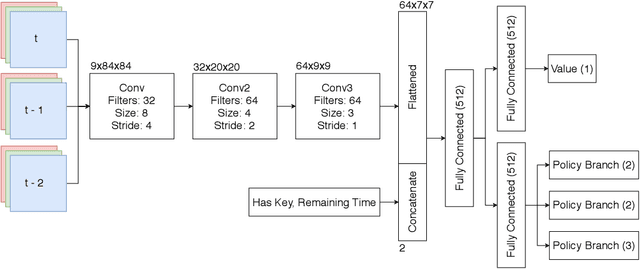

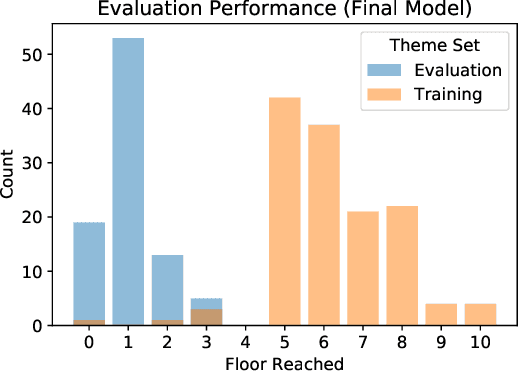
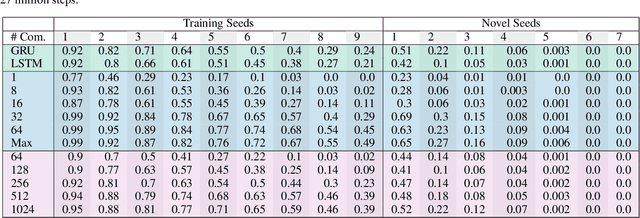
The Obstacle Tower Challenge is the task to master a procedurally generated chain of levels that subsequently get harder to complete. Whereas the top 6 performing entries of last year's competition all used human demonstrations to learn how to cope with the challenge, we present an approach that performed competitively (placed 7th) but starts completely from scratch by means of Deep Reinforcement Learning with a relatively simple feed-forward deep network structure. We especially look at the generalization performance of the taken approach concerning different seeds and various visual themes that have become available after the competition, and investigate where the agent fails and why. Note that our approach does not possess a short-term memory like employing recurrent hidden states. With this work, we hope to contribute to a better understanding of what is possible with a relatively simple, flexible solution that can be applied to learning in environments featuring complex 3D visual input where the abstract task structure itself is still fairly simple.