 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObstacle Tower Without Human Demonstrations: How Far a Deep Feed-Forward Network Goes with Reinforcement Learning
Paper and Code

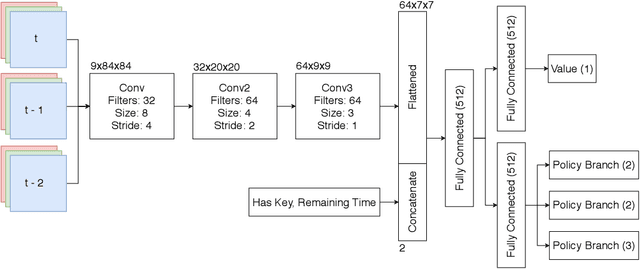

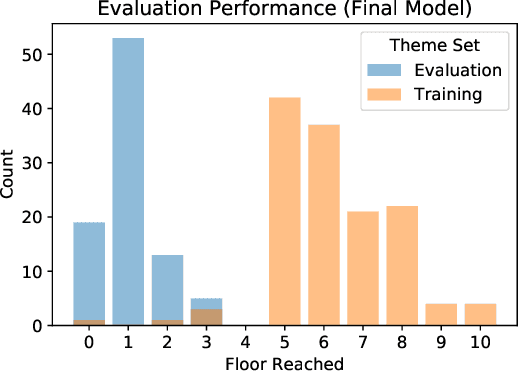
The Obstacle Tower Challenge is the task to master a procedurally generated chain of levels that subsequently get harder to complete. Whereas the top 6 performing entries of last year's competition all used human demonstrations to learn how to cope with the challenge, we present an approach that performed competitively (placed 7th) but starts completely from scratch by means of Deep Reinforcement Learning with a relatively simple feed-forward deep network structure. We especially look at the generalization performance of the taken approach concerning different seeds and various visual themes that have become available after the competition, and investigate where the agent fails and why. Note that our approach does not possess a short-term memory like employing recurrent hidden states. With this work, we hope to contribute to a better understanding of what is possible with a relatively simple, flexible solution that can be applied to learning in environments featuring complex 3D visual input where the abstract task structure itself is still fairly simple.