 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Open-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison
Sep 10, 2025We introduce open-sci-ref, a family of dense transformer models trained as research baselines across multiple model (0.13B to 1.7B parameters) and token scales (up to 1T) on 8 recent open reference datasets. Evaluating the models on various standardized benchmarks, our training runs set establishes reference points that enable researchers to assess the sanity and quality of alternative training approaches across scales and datasets. Intermediate checkpoints allow comparison and studying of the training dynamics. The established reference baselines allow training procedures to be compared through their scaling trends, aligning them on a common compute axis. Comparison of open reference datasets reveals that training on NemoTron-CC HQ consistently outperforms other reference datasets, followed by DCLM-baseline and FineWeb-Edu. In addition to intermediate training checkpoints, the release includes logs, code, and downstream evaluations to simplify reproduction, standardize comparison, and facilitate future research.
A Good CREPE needs more than just Sugar: Investigating Biases in Compositional Vision-Language Benchmarks
Jun 09, 2025



We investigate 17 benchmarks (e.g. SugarCREPE, VALSE) commonly used for measuring compositional understanding capabilities of vision-language models (VLMs). We scrutinize design choices in their construction, including data source (e.g. MS-COCO) and curation procedures (e.g. constructing negative images/captions), uncovering several inherent biases across most benchmarks. We find that blind heuristics (e.g. token-length, log-likelihood under a language model) perform on par with CLIP models, indicating that these benchmarks do not effectively measure compositional understanding. We demonstrate that the underlying factor is a distribution asymmetry between positive and negative images/captions, induced by the benchmark construction procedures. To mitigate these issues, we provide a few key recommendations for constructing more robust vision-language compositional understanding benchmarks, that would be less prone to such simple attacks.
Scaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets
Jun 05, 2025



In studies of transferable learning, scaling laws are obtained for various important foundation models to predict their properties and performance at larger scales. We show here how scaling law derivation can also be used for model and dataset comparison, allowing to decide which procedure is to be preferred for pre-training. For the first time, full scaling laws based on dense measurements across a wide span of model and samples seen scales are derived for two important language-vision learning procedures, CLIP and MaMMUT, that use either contrastive only or contrastive and captioning text generative loss. Ensuring sufficient prediction accuracy for held out points, we use derived scaling laws to compare both models, obtaining evidence for MaMMUT's stronger improvement with scale and better sample efficiency than standard CLIP. To strengthen validity of the comparison, we show scaling laws for various downstream tasks, classification, retrieval, and segmentation, and for different open datasets, DataComp, DFN and Re-LAION, observing consistently the same trends. We show that comparison can also be performed when deriving scaling laws with a constant learning rate schedule, reducing compute cost. Accurate derivation of scaling laws provides thus means to perform model and dataset comparison across scale spans, avoiding misleading conclusions based on measurements from single reference scales only, paving the road for systematic comparison and improvement of open foundation models and datasets for their creation. We release all the pre-trained models with their intermediate checkpoints, including openMaMMUT-L/14, which achieves $80.3\%$ zero-shot ImageNet-1k accuracy, trained on 12.8B samples from DataComp-1.4B. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/scaling-laws-for-comparison.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Learning in Compact Spaces with Approximately Normalized Transformers
May 28, 2025In deep learning, regularization and normalization are common solutions for challenges such as overfitting, numerical instabilities, and the increasing variance in the residual stream. An alternative approach is to force all parameters and representations to lie on a hypersphere. This removes the need for regularization and increases convergence speed, but comes with additional costs. In this work, we propose a more holistic but approximate normalization (anTransformer). Our approach constrains the norm of parameters and normalizes all representations via scalar multiplications motivated by the tight concentration of the norms of high-dimensional random vectors. When applied to GPT training, we observe a 40% faster convergence compared to models with QK normalization, with less than 3% additional runtime. Deriving scaling laws for anGPT, we found our method enables training with larger batch sizes and fewer hyperparameters, while matching the favorable scaling characteristics of classic GPT architectures.
Project Alexandria: Towards Freeing Scientific Knowledge from Copyright Burdens via LLMs
Feb 26, 2025

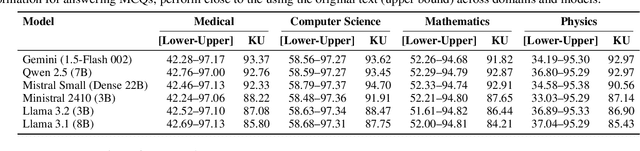

Paywalls, licenses and copyright rules often restrict the broad dissemination and reuse of scientific knowledge. We take the position that it is both legally and technically feasible to extract the scientific knowledge in scholarly texts. Current methods, like text embeddings, fail to reliably preserve factual content, and simple paraphrasing may not be legally sound. We urge the community to adopt a new idea: convert scholarly documents into Knowledge Units using LLMs. These units use structured data capturing entities, attributes and relationships without stylistic content. We provide evidence that Knowledge Units: (1) form a legally defensible framework for sharing knowledge from copyrighted research texts, based on legal analyses of German copyright law and U.S. Fair Use doctrine, and (2) preserve most (~95%) factual knowledge from original text, measured by MCQ performance on facts from the original copyrighted text across four research domains. Freeing scientific knowledge from copyright promises transformative benefits for scientific research and education by allowing language models to reuse important facts from copyrighted text. To support this, we share open-source tools for converting research documents into Knowledge Units. Overall, our work posits the feasibility of democratizing access to scientific knowledge while respecting copyright.
Inverse Deep Learning Ray Tracing for Heliostat Surface Prediction
Aug 20, 2024Concentrating Solar Power (CSP) plants play a crucial role in the global transition towards sustainable energy. A key factor in ensuring the safe and efficient operation of CSP plants is the distribution of concentrated flux density on the receiver. However, the non-ideal flux density generated by individual heliostats can undermine the safety and efficiency of the power plant. The flux density from each heliostat is influenced by its precise surface profile, which includes factors such as canting and mirror errors. Accurately measuring these surface profiles for a large number of heliostats in operation is a formidable challenge. Consequently, control systems often rely on the assumption of ideal surface conditions, which compromises both safety and operational efficiency. In this study, we introduce inverse Deep Learning Ray Tracing (iDLR), an innovative method designed to predict heliostat surfaces based solely on target images obtained during heliostat calibration. Our simulation-based investigation demonstrates that sufficient information regarding the heliostat surface is retained in the flux density distribution of a single heliostat, enabling deep learning models to accurately predict the underlying surface with deflectometry-like precision for the majority of heliostats. Additionally, we assess the limitations of this method, particularly in relation to surface accuracy and resultant flux density predictions. Furthermore, we are presenting a new comprehensive heliostat model using Non-Uniform Rational B-Spline (NURBS) that has the potential to become the new State of the Art for heliostat surface parameterization. Our findings reveal that iDLR has significant potential to enhance CSP plant operations, potentially increasing the overall efficiency and energy output of the power plants.
Resolving Discrepancies in Compute-Optimal Scaling of Language Models
Jun 27, 2024



Kaplan et al. and Hoffmann et al. developed influential scaling laws for the optimal model size as a function of the compute budget, but these laws yield substantially different predictions. We explain the discrepancy by reproducing the Kaplan scaling law on two datasets (OpenWebText2 and RefinedWeb) and identifying three factors causing the difference: last layer computational cost, warmup duration, and scale-dependent optimizer tuning. With these factors corrected, we obtain excellent agreement with the Hoffmann et al. (i.e., "Chinchilla") scaling law. Counter to a hypothesis of Hoffmann et al., we find that careful learning rate decay is not essential for the validity of their scaling law. As a secondary result, we derive scaling laws for the optimal learning rate and batch size, finding that tuning the AdamW $\beta_2$ parameter is essential at lower batch sizes.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.