 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models
Jun 04, 2024



Large Language Models (LLMs) are often described as being instances of foundation models - that is, models that transfer strongly across various tasks and conditions in few-show or zero-shot manner, while exhibiting scaling laws that predict function improvement when increasing the pre-training scale. These claims of excelling in different functions and tasks rely on measurements taken across various sets of standardized benchmarks showing high scores for such models. We demonstrate here a dramatic breakdown of function and reasoning capabilities of state-of-the-art models trained at the largest available scales which claim strong function, using a simple, short, conventional common sense problem formulated in concise natural language, easily solvable by humans. The breakdown is dramatic, as models also express strong overconfidence in their wrong solutions, while providing often non-sensical "reasoning"-like explanations akin to confabulations to justify and backup the validity of their clearly failed responses, making them sound plausible. Various standard interventions in an attempt to get the right solution, like various type of enhanced prompting, or urging the models to reconsider the wrong solutions again by multi step re-evaluation, fail. We take these initial observations to the scientific and technological community to stimulate urgent re-assessment of the claimed capabilities of current generation of LLMs, Such re-assessment also requires common action to create standardized benchmarks that would allow proper detection of such basic reasoning deficits that obviously manage to remain undiscovered by current state-of-the-art evaluation procedures and benchmarks. Code for reproducing experiments in the paper and raw experiments data can be found at https://github.com/LAION-AI/AIW
Markovian Embeddings for Coalitional Bargaining Games
Jun 19, 2023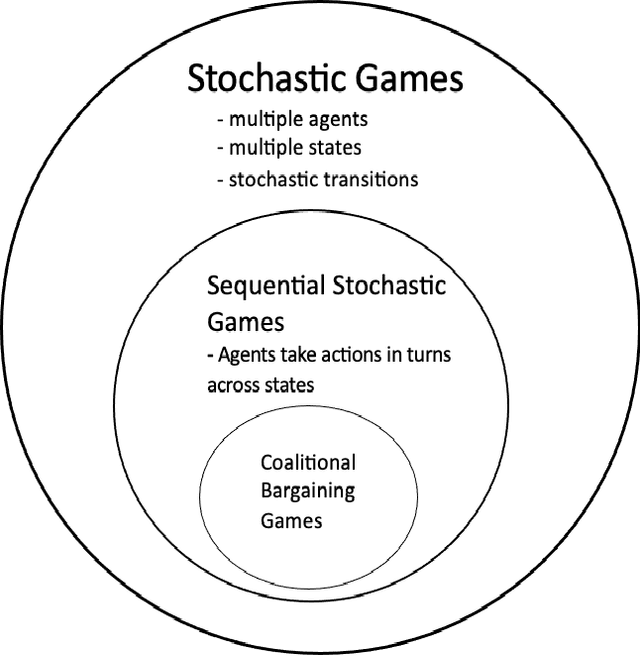
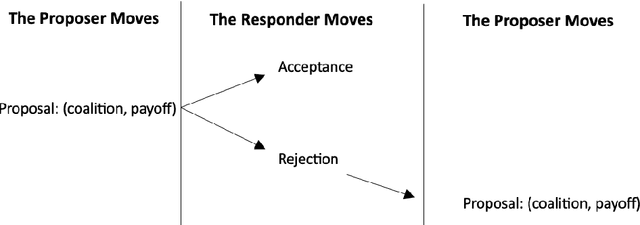
We examine the Markovian properties of coalition bargaining games, in particular, the case where past rejected proposals cannot be repeated. We propose a Markovian embedding with filtrations to render the sates Markovian and thus, fit into the framework of stochastic games.
Comparison of CoModGANs, LaMa and GLIDE for Art Inpainting- Completing M.C Escher's Print Gallery
May 03, 2022
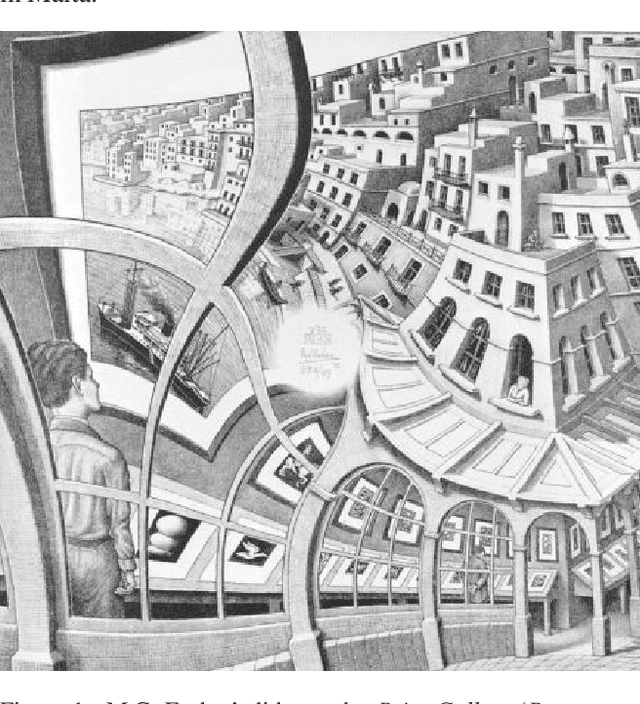


Digital art restoration has benefited from inpainting models to correct the degradation or missing sections of a painting. This work compares three current state-of-the art models for inpainting of large missing regions. We provide qualitative and quantitative comparison of the performance by CoModGANs, LaMa and GLIDE in inpainting of blurry and missing sections of images. We use Escher's incomplete painting Print Gallery as our test study since it presents several of the challenges commonly present in restorative inpainting.
Image In painting Applied to Art Completing Escher's Print Gallery
Sep 06, 2021
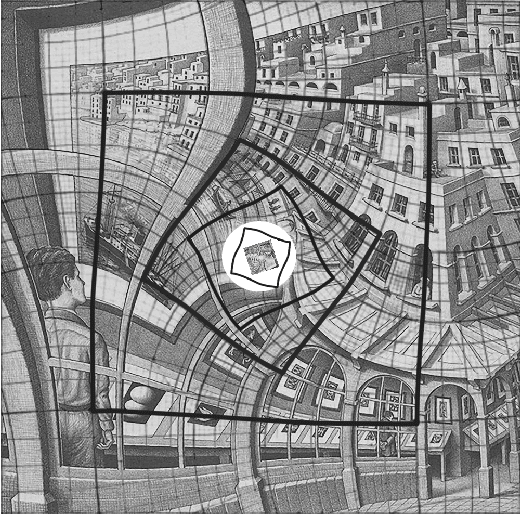


This extended abstract presents the first stages of a research on in-painting suited for art reconstruction. We introduce M.C Eschers Print Gallery lithography as a use case example. This artwork presents a void on its center and additionally, it follows a challenging mathematical structure that needs to be preserved by the in-painting method. We present our work so far and our future line of research.
* Abstract submitted to LatinX workshop on ICML 2021