 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Fully Autonomous Programming using Iterative Multi-Agent Debugging with Large Language Models
Mar 10, 2025Program synthesis with Large Language Models (LLMs) suffers from a "near-miss syndrome": the generated code closely resembles a correct solution but fails unit tests due to minor errors. We address this with a multi-agent framework called Synthesize, Execute, Instruct, Debug, and Repair (SEIDR). Effectively applying SEIDR to instruction-tuned LLMs requires determining (a) optimal prompts for LLMs, (b) what ranking algorithm selects the best programs in debugging rounds, and (c) balancing the repair of unsuccessful programs with the generation of new ones. We empirically explore these trade-offs by comparing replace-focused, repair-focused, and hybrid debug strategies. We also evaluate lexicase and tournament selection to rank candidates in each generation. On Program Synthesis Benchmark 2 (PSB2), our framework outperforms both conventional use of OpenAI Codex without a repair phase and traditional genetic programming approaches. SEIDR outperforms the use of an LLM alone, solving 18 problems in C++ and 20 in Python on PSB2 at least once across experiments. To assess generalizability, we employ GPT-3.5 and Llama 3 on the PSB2 and HumanEval-X benchmarks. Although SEIDR with these models does not surpass current state-of-the-art methods on the Python benchmarks, the results on HumanEval-C++ are promising. SEIDR with Llama 3-8B achieves an average pass@100 of 84.2%. Across all SEIDR runs, 163 of 164 problems are solved at least once with GPT-3.5 in HumanEval-C++, and 162 of 164 with the smaller Llama 3-8B. We conclude that SEIDR effectively overcomes the near-miss syndrome in program synthesis with LLMs.
A Novel Approach for Automatic Program Repair using Round-Trip Translation with Large Language Models
Jan 15, 2024Research shows that grammatical mistakes in a sentence can be corrected by translating it to another language and back using neural machine translation with language models. We investigate whether this correction capability of Large Language Models (LLMs) extends to Automatic Program Repair (APR). Current generative models for APR are pre-trained on source code and fine-tuned for repair. This paper proposes bypassing the fine-tuning step and using Round-Trip Translation (RTT): translation of code from one programming language to another programming or natural language, and back. We hypothesize that RTT with LLMs restores the most commonly seen patterns in code during pre-training, i.e., performs a regression toward the mean, which removes bugs as they are a form of noise w.r.t. the more frequent, natural, bug-free code in the training data. To test this hypothesis, we employ eight recent LLMs pre-trained on code, including the latest GPT versions, and four common program repair benchmarks in Java. We find that RTT with English as an intermediate language repaired 101 of 164 bugs with GPT-4 on the HumanEval-Java dataset. Moreover, 46 of these are unique bugs that are not repaired by other LLMs fine-tuned for APR. Our findings highlight the viability of round-trip translation with LLMs as a technique for automated program repair and its potential for research in software engineering. Keywords: automated program repair, large language model, machine translation
An Exploratory Literature Study on Sharing and Energy Use of Language Models for Source Code
Jul 05, 2023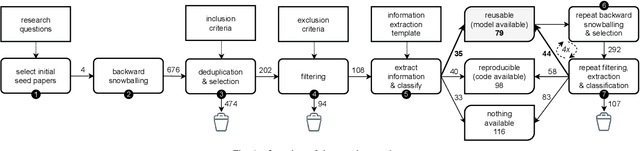

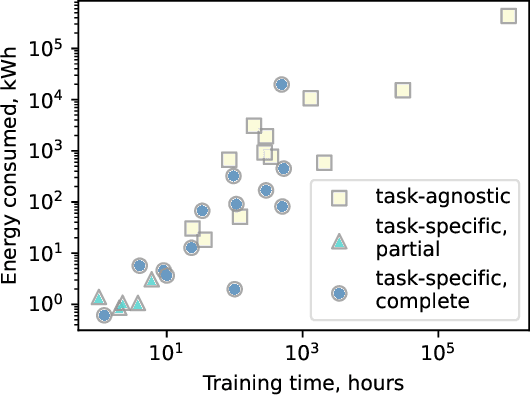

Large language models trained on source code can support a variety of software development tasks, such as code recommendation and program repair. Large amounts of data for training such models benefit the models' performance. However, the size of the data and models results in long training times and high energy consumption. While publishing source code allows for replicability, users need to repeat the expensive training process if models are not shared. The main goal of the study is to investigate if publications that trained language models for software engineering (SE) tasks share source code and trained artifacts. The second goal is to analyze the transparency on training energy usage. We perform a snowballing-based literature search to find publications on language models for source code, and analyze their reusability from a sustainability standpoint. From 494 unique publications, we identified 293 relevant publications that use language models to address code-related tasks. Among them, 27% (79 out of 293) make artifacts available for reuse. This can be in the form of tools or IDE plugins designed for specific tasks or task-agnostic models that can be fine-tuned for a variety of downstream tasks. Moreover, we collect insights on the hardware used for model training, as well as training time, which together determine the energy consumption of the development process. We find that there are deficiencies in the sharing of information and artifacts for current studies on source code models for software engineering tasks, with 40% of the surveyed papers not sharing source code or trained artifacts. We recommend the sharing of source code as well as trained artifacts, to enable sustainable reproducibility. Moreover, comprehensive information on training times and hardware configurations should be shared for transparency on a model's carbon footprint.
The EarlyBIRD Catches the Bug: On Exploiting Early Layers of Encoder Models for More Efficient Code Classification
May 08, 2023



The use of modern Natural Language Processing (NLP) techniques has shown to be beneficial for software engineering tasks, such as vulnerability detection and type inference. However, training deep NLP models requires significant computational resources. This paper explores techniques that aim at achieving the best usage of resources and available information in these models. We propose a generic approach, EarlyBIRD, to build composite representations of code from the early layers of a pre-trained transformer model. We empirically investigate the viability of this approach on the CodeBERT model by comparing the performance of 12 strategies for creating composite representations with the standard practice of only using the last encoder layer. Our evaluation on four datasets shows that several early layer combinations yield better performance on defect detection, and some combinations improve multi-class classification. More specifically, we obtain a +2 average improvement of detection accuracy on Devign with only 3 out of 12 layers of CodeBERT and a 3.3x speed-up of fine-tuning. These findings show that early layers can be used to obtain better results using the same resources, as well as to reduce resource usage during fine-tuning and inference.
Fully Autonomous Programming with Large Language Models
Apr 20, 2023



Current approaches to program synthesis with Large Language Models (LLMs) exhibit a "near miss syndrome": they tend to generate programs that semantically resemble the correct answer (as measured by text similarity metrics or human evaluation), but achieve a low or even zero accuracy as measured by unit tests due to small imperfections, such as the wrong input or output format. This calls for an approach known as Synthesize, Execute, Debug (SED), whereby a draft of the solution is generated first, followed by a program repair phase addressing the failed tests. To effectively apply this approach to instruction-driven LLMs, one needs to determine which prompts perform best as instructions for LLMs, as well as strike a balance between repairing unsuccessful programs and replacing them with newly generated ones. We explore these trade-offs empirically, comparing replace-focused, repair-focused, and hybrid debug strategies, as well as different template-based and model-based prompt-generation techniques. We use OpenAI Codex as the LLM and Program Synthesis Benchmark 2 as a database of problem descriptions and tests for evaluation. The resulting framework outperforms both conventional usage of Codex without the repair phase and traditional genetic programming approaches.
Enabling Automatic Repair of Source Code Vulnerabilities Using Data-Driven Methods
Feb 07, 2022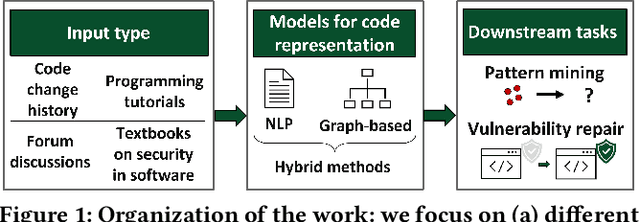
Users around the world rely on software-intensive systems in their day-to-day activities. These systems regularly contain bugs and security vulnerabilities. To facilitate bug fixing, data-driven models of automatic program repair use pairs of buggy and fixed code to learn transformations that fix errors in code. However, automatic repair of security vulnerabilities remains under-explored. In this work, we propose ways to improve code representations for vulnerability repair from three perspectives: input data type, data-driven models, and downstream tasks. The expected results of this work are improved code representations for automatic program repair and, specifically, fixing security vulnerabilities.