 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Speech Emotion Recognition via Fine-Tuning Pre-Trained Models and Hyper-Parameter Optimisation
Oct 08, 2025



We propose a workflow for speech emotion recognition (SER) that combines pre-trained representations with automated hyperparameter optimisation (HPO). Using SpeechBrain wav2vec2-base model fine-tuned on IEMOCAP as the encoder, we compare two HPO strategies, Gaussian Process Bayesian Optimisation (GP-BO) and Tree-structured Parzen Estimators (TPE), under an identical four-dimensional search space and 15-trial budget, with balanced class accuracy (BCA) on the German EmoDB corpus as the objective. All experiments run on 8 CPU cores with 32 GB RAM. GP-BO achieves 0.96 BCA in 11 minutes, and TPE (Hyperopt implementation) attains 0.97 in 15 minutes. In contrast, grid search requires 143 trials and 1,680 minutes to exceed 0.9 BCA, and the best AutoSpeech 2020 baseline reports only 0.85 in 30 minutes on GPU. For cross-lingual generalisation, an EmoDB-trained HPO-tuned model improves zero-shot accuracy by 0.25 on CREMA-D and 0.26 on RAVDESS. Results show that efficient HPO with pre-trained encoders delivers competitive SER on commodity CPUs. Source code to this work is available at: https://github.com/youngaryan/speechbrain-emotion-hpo.
Interpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives
Apr 04, 2025In cancer therapeutics, protein-metal binding mechanisms critically govern drug pharmacokinetics and targeting efficacy, thereby fundamentally shaping the rational design of anticancer metallodrugs. While conventional laboratory methods used to study such mechanisms are often costly, low throughput, and limited in capturing dynamic biological processes, machine learning (ML) has emerged as a promising alternative. Despite increasing efforts to develop protein-metal binding datasets and ML algorithms, the application of ML in tumor protein-metal binding remains limited. Key challenges include a shortage of high-quality, tumor-specific datasets, insufficient consideration of multiple data modalities, and the complexity of interpreting results due to the ''black box'' nature of complex ML models. This paper summarizes recent progress and ongoing challenges in using ML to predict tumor protein-metal binding, focusing on data, modeling, and interpretability. We present multimodal protein-metal binding datasets and outline strategies for acquiring, curating, and preprocessing them for training ML models. Moreover, we explore the complementary value provided by different data modalities and examine methods for their integration. We also review approaches for improving model interpretability to support more trustworthy decisions in cancer research. Finally, we offer our perspective on research opportunities and propose strategies to address the scarcity of tumor protein data and the limited number of predictive models for tumor protein-metal binding. We also highlight two promising directions for effective metal-based drug design: integrating protein-protein interaction data to provide structural insights into metal-binding events and predicting structural changes in tumor proteins after metal binding.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Classifying the Stoichiometry of Virus-like Particles with Interpretable Machine Learning
Feb 17, 2025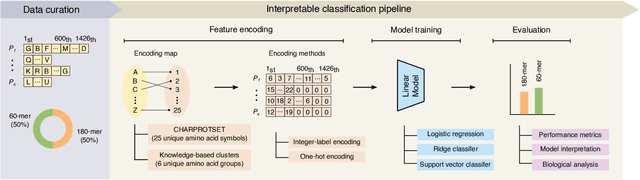

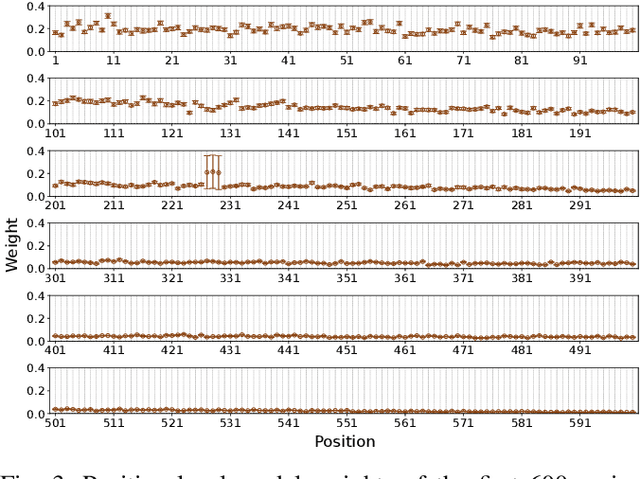
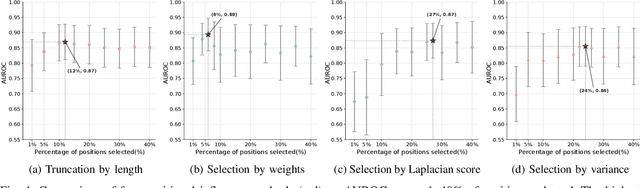
Virus-like particles (VLPs) are valuable for vaccine development due to their immune-triggering properties. Understanding their stoichiometry, the number of protein subunits to form a VLP, is critical for vaccine optimisation. However, current experimental methods to determine stoichiometry are time-consuming and require highly purified proteins. To efficiently classify stoichiometry classes in proteins, we curate a new dataset and propose an interpretable, data-driven pipeline leveraging linear machine learning models. We also explore the impact of feature encoding on model performance and interpretability, as well as methods to identify key protein sequence features influencing classification. The evaluation of our pipeline demonstrates that it can classify stoichiometry while revealing protein features that possibly influence VLP assembly. The data and code used in this work are publicly available at https://github.com/Shef-AIRE/StoicIML.
Quantum Neural Network for Accelerated Magnetic Resonance Imaging
Oct 12, 2024



Magnetic resonance image reconstruction starting from undersampled k-space data requires the recovery of many potential nonlinear features, which is very difficult for algorithms to recover these features. In recent years, the development of quantum computing has discovered that quantum convolution can improve network accuracy, possibly due to potential quantum advantages. This article proposes a hybrid neural network containing quantum and classical networks for fast magnetic resonance imaging, and conducts experiments on a quantum computer simulation system. The experimental results indicate that the hybrid network has achieved excellent reconstruction results, and also confirm the feasibility of applying hybrid quantum-classical neural networks into the image reconstruction of rapid magnetic resonance imaging.
Group-specific discriminant analysis reveals statistically validated sex differences in lateralization of brain functional network
Apr 08, 2024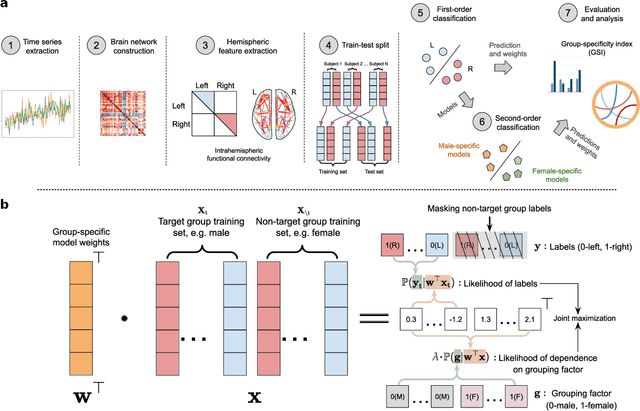

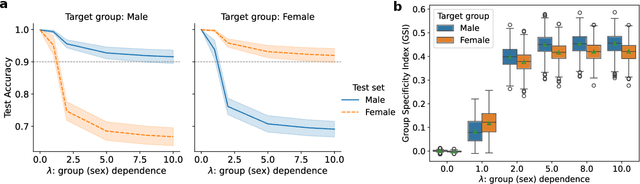

Lateralization is a fundamental feature of the human brain, where sex differences have been observed. Conventional studies in neuroscience on sex-specific lateralization are typically conducted on univariate statistical comparisons between male and female groups. However, these analyses often lack effective validation of group specificity. Here, we formulate modeling sex differences in lateralization of functional networks as a dual-classification problem, consisting of first-order classification for left vs. right functional networks and second-order classification for male vs. female models. To capture sex-specific patterns, we develop the Group-Specific Discriminant Analysis (GSDA) for first-order classification. The evaluation on two public neuroimaging datasets demonstrates the efficacy of GSDA in learning sex-specific models from functional networks, achieving a significant improvement in group specificity over baseline methods. The major sex differences are in the strength of lateralization and the interactions within and between lobes. The GSDA-based method is generic in nature and can be adapted to other group-specific analyses such as handedness-specific or disease-specific analyses.
Interpretable Multimodal Learning for Cardiovascular Hemodynamics Assessment
Apr 06, 2024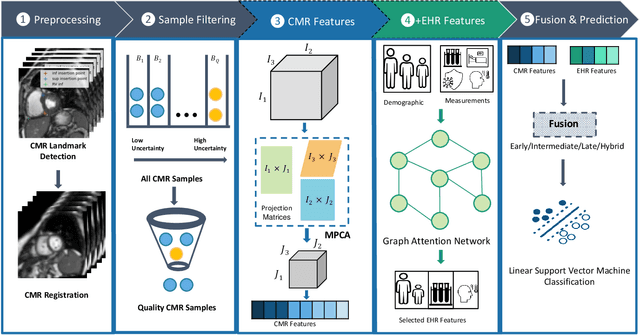
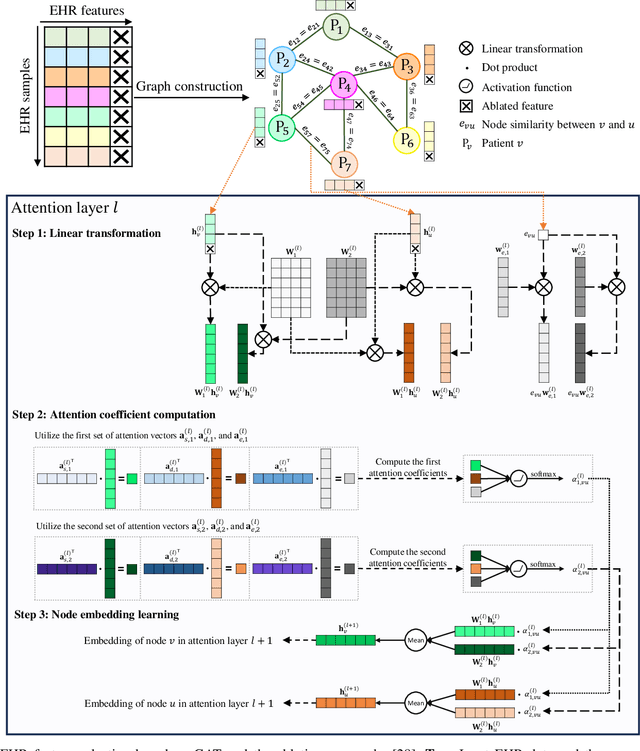
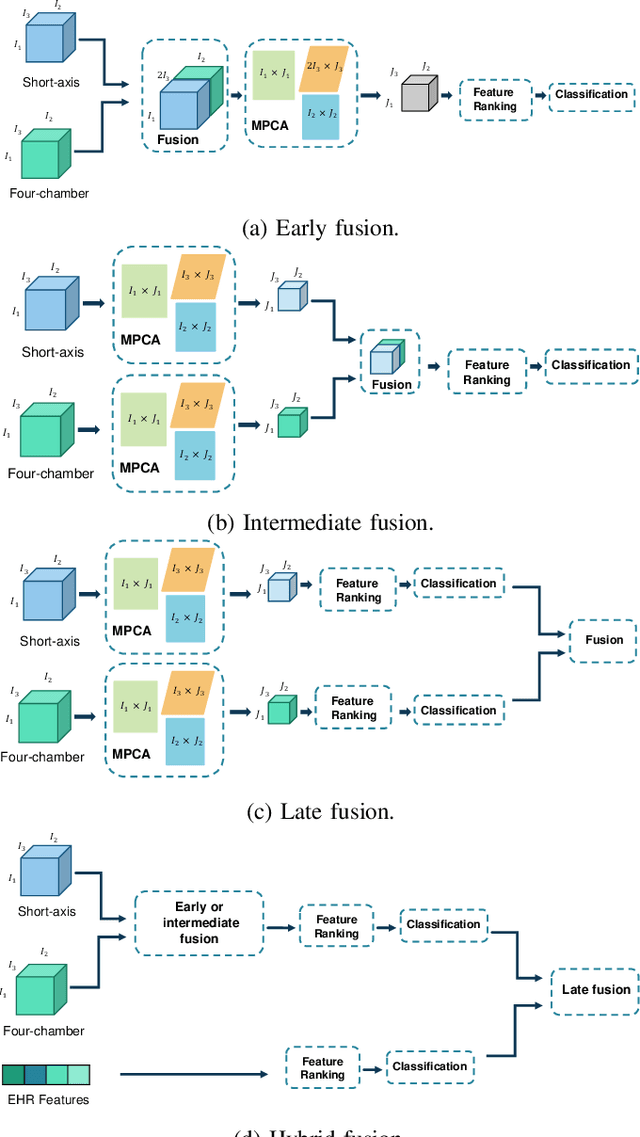
Pulmonary Arterial Wedge Pressure (PAWP) is an essential cardiovascular hemodynamics marker to detect heart failure. In clinical practice, Right Heart Catheterization is considered a gold standard for assessing cardiac hemodynamics while non-invasive methods are often needed to screen high-risk patients from a large population. In this paper, we propose a multimodal learning pipeline to predict PAWP marker. We utilize complementary information from Cardiac Magnetic Resonance Imaging (CMR) scans (short-axis and four-chamber) and Electronic Health Records (EHRs). We extract spatio-temporal features from CMR scans using tensor-based learning. We propose a graph attention network to select important EHR features for prediction, where we model subjects as graph nodes and feature relationships as graph edges using the attention mechanism. We design four feature fusion strategies: early, intermediate, late, and hybrid fusion. With a linear classifier and linear fusion strategies, our pipeline is interpretable. We validate our pipeline on a large dataset of $2,641$ subjects from our ASPIRE registry. The comparative study against state-of-the-art methods confirms the superiority of our pipeline. The decision curve analysis further validates that our pipeline can be applied to screen a large population. The code is available at https://github.com/prasunc/hemodynamics.
Multimodal Variational Autoencoder for Low-cost Cardiac Hemodynamics Instability Detection
Mar 20, 2024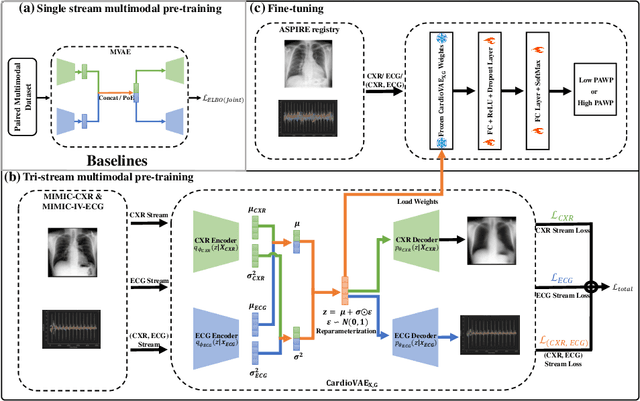
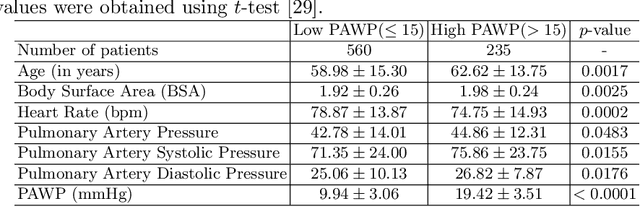
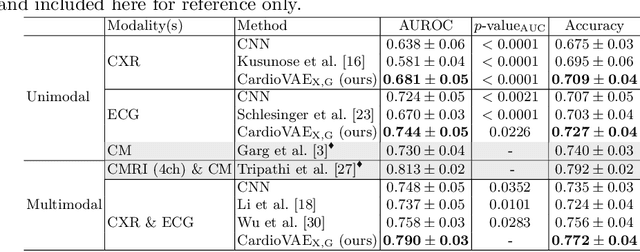
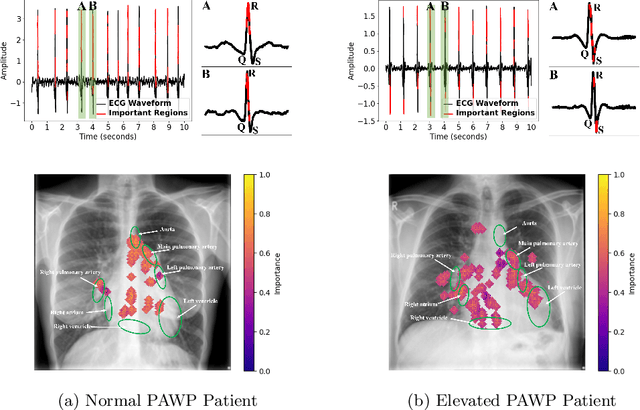
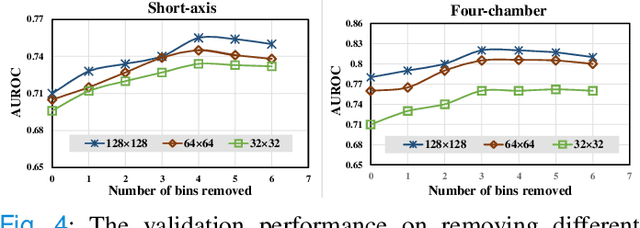
Recent advancements in non-invasive detection of cardiac hemodynamic instability (CHDI) primarily focus on applying machine learning techniques to a single data modality, e.g. cardiac magnetic resonance imaging (MRI). Despite their potential, these approaches often fall short especially when the size of labeled patient data is limited, a common challenge in the medical domain. Furthermore, only a few studies have explored multimodal methods to study CHDI, which mostly rely on costly modalities such as cardiac MRI and echocardiogram. In response to these limitations, we propose a novel multimodal variational autoencoder ($\text{CardioVAE}_\text{X,G}$) to integrate low-cost chest X-ray (CXR) and electrocardiogram (ECG) modalities with pre-training on a large unlabeled dataset. Specifically, $\text{CardioVAE}_\text{X,G}$ introduces a novel tri-stream pre-training strategy to learn both shared and modality-specific features, thus enabling fine-tuning with both unimodal and multimodal datasets. We pre-train $\text{CardioVAE}_\text{X,G}$ on a large, unlabeled dataset of $50,982$ subjects from a subset of MIMIC database and then fine-tune the pre-trained model on a labeled dataset of $795$ subjects from the ASPIRE registry. Comprehensive evaluations against existing methods show that $\text{CardioVAE}_\text{X,G}$ offers promising performance (AUROC $=0.79$ and Accuracy $=0.77$), representing a significant step forward in non-invasive prediction of CHDI. Our model also excels in producing fine interpretations of predictions directly associated with clinical features, thereby supporting clinical decision-making.
MeDSLIP: Medical Dual-Stream Language-Image Pre-training for Fine-grained Alignment
Mar 15, 2024Vision-language pre-training (VLP) models have shown significant advancements in the medical domain. Yet, most VLP models align raw reports to images at a very coarse level, without modeling fine-grained relationships between anatomical and pathological concepts outlined in reports and the corresponding semantic counterparts in images. To address this problem, we propose a Medical Dual-Stream Language-Image Pre-training (MeDSLIP) framework. Specifically, MeDSLIP establishes vision-language fine-grained alignments via disentangling visual and textual representations into anatomy-relevant and pathology-relevant streams. Moreover, a novel vision-language Prototypical Contr-astive Learning (ProtoCL) method is adopted in MeDSLIP to enhance the alignment within the anatomical and pathological streams. MeDSLIP further employs cross-stream Intra-image Contrastive Learning (ICL) to ensure the consistent coexistence of paired anatomical and pathological concepts within the same image. Such a cross-stream regularization encourages the model to exploit the synchrony between two streams for a more comprehensive representation learning. MeDSLIP is evaluated under zero-shot and supervised fine-tuning settings on three public datasets: NIH CXR14, RSNA Pneumonia, and SIIM-ACR Pneumothorax. Under these settings, MeDSLIP outperforms six leading CNN-based models on classification, grounding, and segmentation tasks.
Tensor-based Multimodal Learning for Prediction of Pulmonary Arterial Wedge Pressure from Cardiac MRI
Mar 14, 2023Heart failure is a serious and life-threatening condition that can lead to elevated pressure in the left ventricle. Pulmonary Arterial Wedge Pressure (PAWP) is an important surrogate marker indicating high pressure in the left ventricle. PAWP is determined by Right Heart Catheterization (RHC) but it is an invasive procedure. A non-invasive method is useful in quickly identifying high-risk patients from a large population. In this work, we develop a tensor learning-based pipeline for identifying PAWP from multimodal cardiac Magnetic Resonance Imaging (MRI). This pipeline extracts spatial and temporal features from high-dimensional scans. For quality control, we incorporate an epistemic uncertainty-based binning strategy to identify poor-quality training samples. To improve the performance, we learn complementary information by integrating features from multimodal data: cardiac MRI with short-axis and four-chamber views, and Electronic Health Records. The experimental analysis on a large cohort of $1346$ subjects who underwent the RHC procedure for PAWP estimation indicates that the proposed pipeline has a diagnostic value and can produce promising performance with significant improvement over the baseline in clinical practice (i.e., $\Delta$AUC $=0.10$, $\Delta$Accuracy $=0.06$, and $\Delta$MCC $=0.39$). The decision curve analysis further confirms the clinical utility of our method.