 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairing-free Group-level Knowledge Distillation for Robust Gastrointestinal Lesion Classification in White-Light Endoscopy
Jan 14, 2026White-Light Imaging (WLI) is the standard for endoscopic cancer screening, but Narrow-Band Imaging (NBI) offers superior diagnostic details. A key challenge is transferring knowledge from NBI to enhance WLI-only models, yet existing methods are critically hampered by their reliance on paired NBI-WLI images of the same lesion, a costly and often impractical requirement that leaves vast amounts of clinical data untapped. In this paper, we break this paradigm by introducing PaGKD, a novel Pairing-free Group-level Knowledge Distillation framework that that enables effective cross-modal learning using unpaired WLI and NBI data. Instead of forcing alignment between individual, often semantically mismatched image instances, PaGKD operates at the group level to distill more complete and compatible knowledge across modalities. Central to PaGKD are two complementary modules: (1) Group-level Prototype Distillation (GKD-Pro) distills compact group representations by extracting modality-invariant semantic prototypes via shared lesion-aware queries; (2) Group-level Dense Distillation (GKD-Den) performs dense cross-modal alignment by guiding group-aware attention with activation-derived relation maps. Together, these modules enforce global semantic consistency and local structural coherence without requiring image-level correspondence. Extensive experiments on four clinical datasets demonstrate that PaGKD consistently and significantly outperforms state-of-the-art methods, achieving relative AUC improvements of 3.3%, 1.1%, 2.8%, and 3.2%, respectively, establishing a new direction for cross-modal learning from unpaired data.
Interpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives
Apr 04, 2025In cancer therapeutics, protein-metal binding mechanisms critically govern drug pharmacokinetics and targeting efficacy, thereby fundamentally shaping the rational design of anticancer metallodrugs. While conventional laboratory methods used to study such mechanisms are often costly, low throughput, and limited in capturing dynamic biological processes, machine learning (ML) has emerged as a promising alternative. Despite increasing efforts to develop protein-metal binding datasets and ML algorithms, the application of ML in tumor protein-metal binding remains limited. Key challenges include a shortage of high-quality, tumor-specific datasets, insufficient consideration of multiple data modalities, and the complexity of interpreting results due to the ''black box'' nature of complex ML models. This paper summarizes recent progress and ongoing challenges in using ML to predict tumor protein-metal binding, focusing on data, modeling, and interpretability. We present multimodal protein-metal binding datasets and outline strategies for acquiring, curating, and preprocessing them for training ML models. Moreover, we explore the complementary value provided by different data modalities and examine methods for their integration. We also review approaches for improving model interpretability to support more trustworthy decisions in cancer research. Finally, we offer our perspective on research opportunities and propose strategies to address the scarcity of tumor protein data and the limited number of predictive models for tumor protein-metal binding. We also highlight two promising directions for effective metal-based drug design: integrating protein-protein interaction data to provide structural insights into metal-binding events and predicting structural changes in tumor proteins after metal binding.
A Backbone Replaceable Fine-tuning Network for Stable Face Alignment
Oct 19, 2020

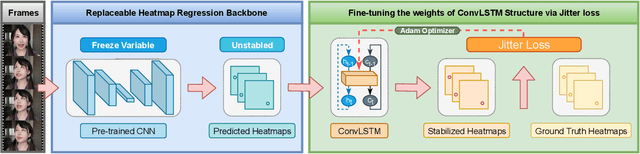
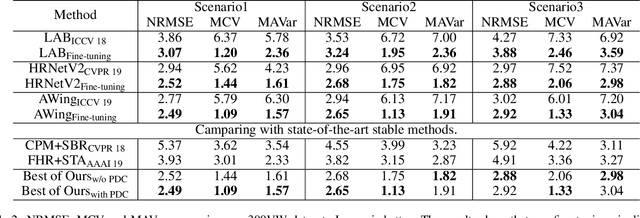
Heatmap regression based face alignment algorithms have achieved prominent performance on static images. However, when applying these methods on videos or sequential images, the stability and accuracy are remarkably discounted. The reason lies in temporal informations are not considered, which is mainly reflected in network structure and loss function. This paper presents a novel backbone replaceable fine-tuning framework, which can swiftly convert facial landmark detector designed for single image level into a better performing one that suitable for videos. On this basis, we proposed the Jitter loss, an innovative temporal information based loss function devised to impose strong penalties on prediction landmarks that jitter around the ground truth. Our framework provides capabilities to achieve at least 40% performance improvement on stability evaluation metrices while enhancing accuracy without re-training the entire model versus state-of-the-art methods.