 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Interpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives
Apr 04, 2025In cancer therapeutics, protein-metal binding mechanisms critically govern drug pharmacokinetics and targeting efficacy, thereby fundamentally shaping the rational design of anticancer metallodrugs. While conventional laboratory methods used to study such mechanisms are often costly, low throughput, and limited in capturing dynamic biological processes, machine learning (ML) has emerged as a promising alternative. Despite increasing efforts to develop protein-metal binding datasets and ML algorithms, the application of ML in tumor protein-metal binding remains limited. Key challenges include a shortage of high-quality, tumor-specific datasets, insufficient consideration of multiple data modalities, and the complexity of interpreting results due to the ''black box'' nature of complex ML models. This paper summarizes recent progress and ongoing challenges in using ML to predict tumor protein-metal binding, focusing on data, modeling, and interpretability. We present multimodal protein-metal binding datasets and outline strategies for acquiring, curating, and preprocessing them for training ML models. Moreover, we explore the complementary value provided by different data modalities and examine methods for their integration. We also review approaches for improving model interpretability to support more trustworthy decisions in cancer research. Finally, we offer our perspective on research opportunities and propose strategies to address the scarcity of tumor protein data and the limited number of predictive models for tumor protein-metal binding. We also highlight two promising directions for effective metal-based drug design: integrating protein-protein interaction data to provide structural insights into metal-binding events and predicting structural changes in tumor proteins after metal binding.
Asynchronous Parallel Stochastic Gradient for Nonconvex Optimization
Jun 10, 2017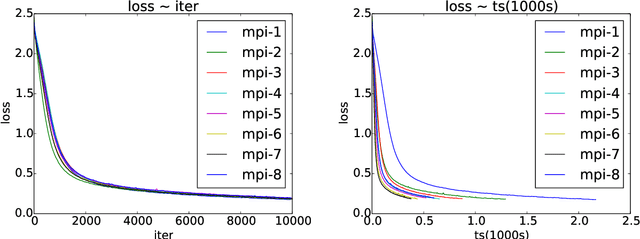

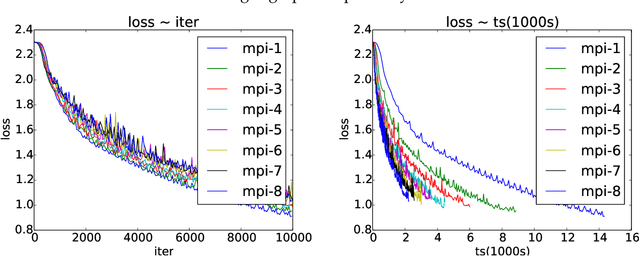

Asynchronous parallel implementations of stochastic gradient (SG) have been broadly used in solving deep neural network and received many successes in practice recently. However, existing theories cannot explain their convergence and speedup properties, mainly due to the nonconvexity of most deep learning formulations and the asynchronous parallel mechanism. To fill the gaps in theory and provide theoretical supports, this paper studies two asynchronous parallel implementations of SG: one is on the computer network and the other is on the shared memory system. We establish an ergodic convergence rate $O(1/\sqrt{K})$ for both algorithms and prove that the linear speedup is achievable if the number of workers is bounded by $\sqrt{K}$ ($K$ is the total number of iterations). Our results generalize and improve existing analysis for convex minimization.
Exclusive Sparsity Norm Minimization with Random Groups via Cone Projection
Oct 27, 2015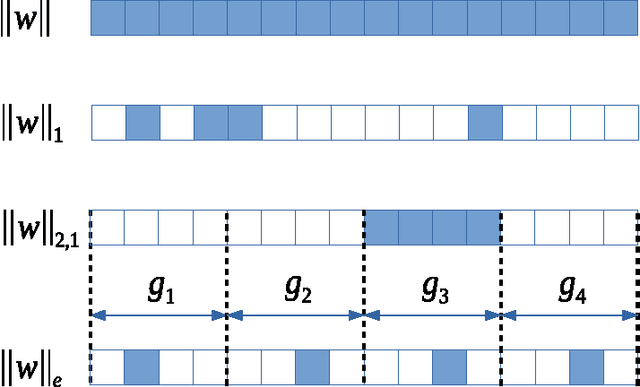
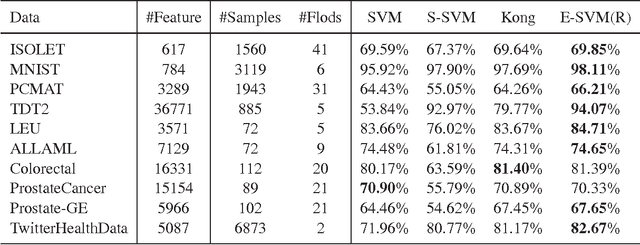
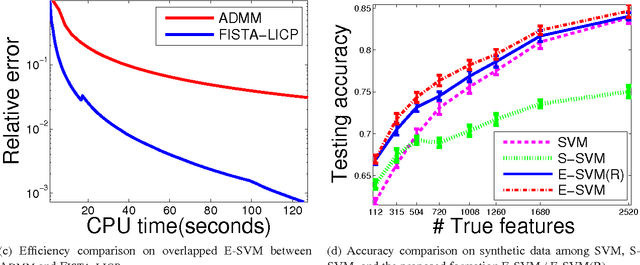
Many practical applications such as gene expression analysis, multi-task learning, image recognition, signal processing, and medical data analysis pursue a sparse solution for the feature selection purpose and particularly favor the nonzeros \emph{evenly} distributed in different groups. The exclusive sparsity norm has been widely used to serve to this purpose. However, it still lacks systematical studies for exclusive sparsity norm optimization. This paper offers two main contributions from the optimization perspective: 1) We provide several efficient algorithms to solve exclusive sparsity norm minimization with either smooth loss or hinge loss (non-smooth loss). All algorithms achieve the optimal convergence rate $O(1/k^2)$ ($k$ is the iteration number). To the best of our knowledge, this is the first time to guarantee such convergence rate for the general exclusive sparsity norm minimization; 2) When the group information is unavailable to define the exclusive sparsity norm, we propose to use the random grouping scheme to construct groups and prove that if the number of groups is appropriately chosen, the nonzeros (true features) would be grouped in the ideal way with high probability. Empirical studies validate the efficiency of proposed algorithms, and the effectiveness of random grouping scheme on the proposed exclusive SVM formulation.