 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End 3D Hand Pose Estimation from Stereo Cameras
Jun 03, 2022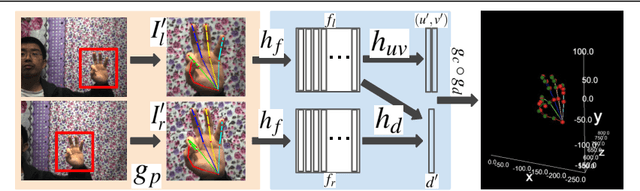
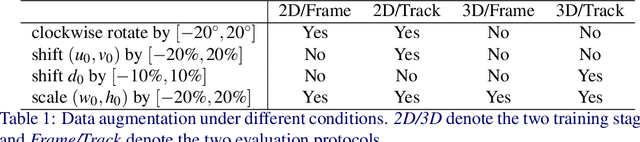

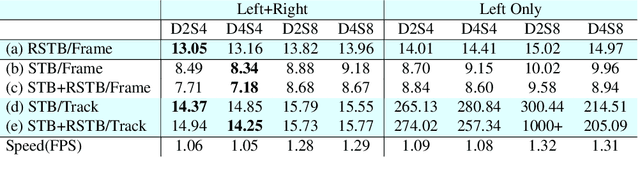
This work proposes an end-to-end approach to estimate full 3D hand pose from stereo cameras. Most existing methods of estimating hand pose from stereo cameras apply stereo matching to obtain depth map and use depth-based solution to estimate hand pose. In contrast, we propose to bypass the stereo matching and directly estimate the 3D hand pose from the stereo image pairs. The proposed neural network architecture extends from any keypoint predictor to estimate the sparse disparity of the hand joints. In order to effectively train the model, we propose a large scale synthetic dataset that is composed of stereo image pairs and ground truth 3D hand pose annotations. Experiments show that the proposed approach outperforms the existing methods based on the stereo depth.
Pose-based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Oct 30, 2020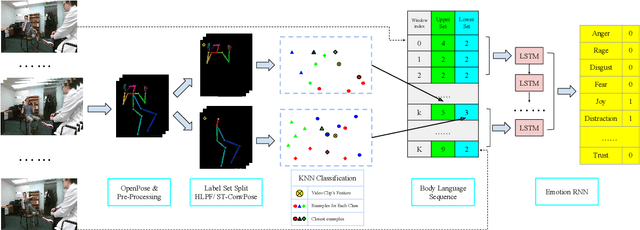
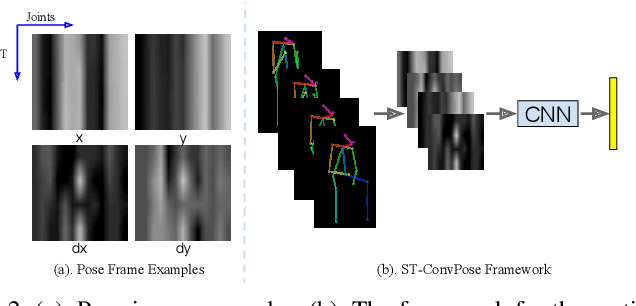
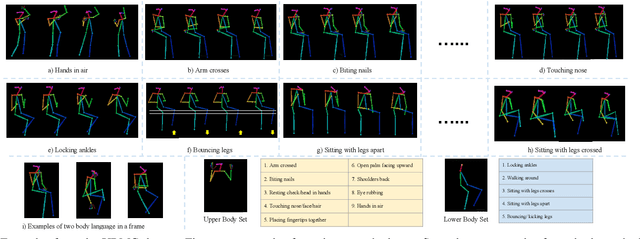
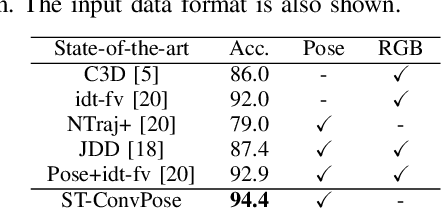
Inspired by the human ability to infer emotions from body language, we propose an automated framework for body language based emotion recognition starting from regular RGB videos. In collaboration with psychologists, we further extend the framework for psychiatric symptom prediction. Because a specific application domain of the proposed framework may only supply a limited amount of data, the framework is designed to work on a small training set and possess a good transferability. The proposed system in the first stage generates sequences of body language predictions based on human poses estimated from input videos. In the second stage, the predicted sequences are fed into a temporal network for emotion interpretation and psychiatric symptom prediction. We first validate the accuracy and transferability of the proposed body language recognition method on several public action recognition datasets. We then evaluate the framework on a proposed URMC dataset, which consists of conversations between a standardized patient and a behavioral health professional, along with expert annotations of body language, emotions, and potential psychiatric symptoms. The proposed framework outperforms other methods on the URMC dataset.
Dynamic Kernel Distillation for Efficient Pose Estimation in Videos
Aug 24, 2019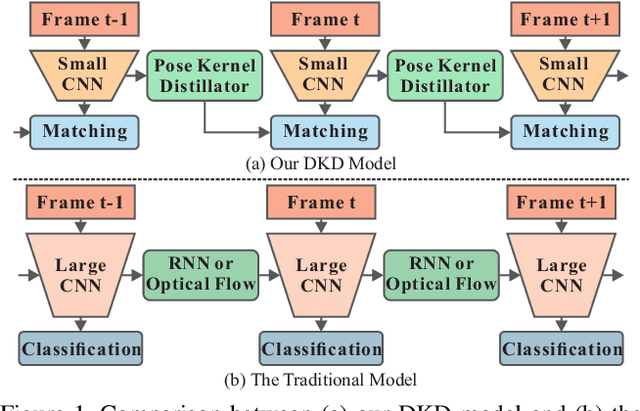
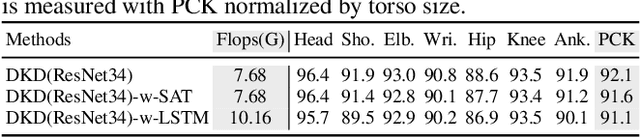
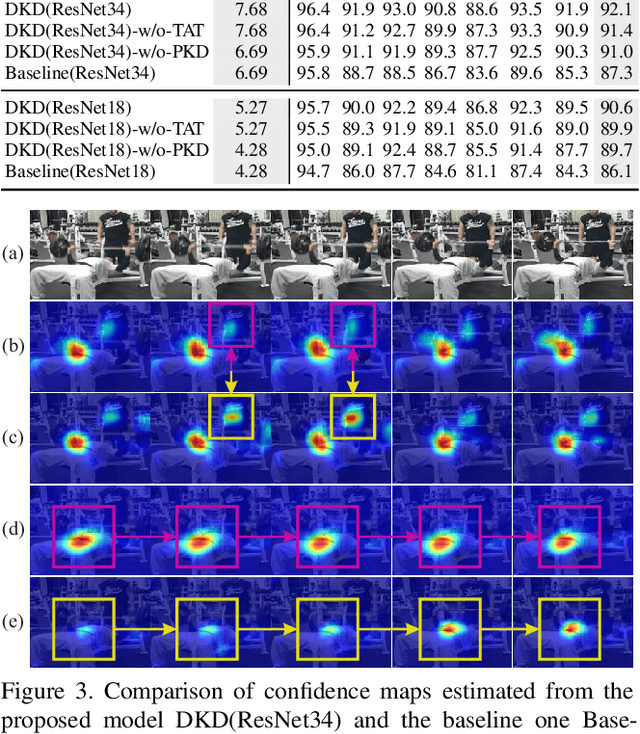
Existing video-based human pose estimation methods extensively apply large networks onto every frame in the video to localize body joints, which suffer high computational cost and hardly meet the low-latency requirement in realistic applications. To address this issue, we propose a novel Dynamic Kernel Distillation (DKD) model to facilitate small networks for estimating human poses in videos, thus significantly lifting the efficiency. In particular, DKD introduces a light-weight distillator to online distill pose kernels via leveraging temporal cues from the previous frame in a one-shot feed-forward manner. Then, DKD simplifies body joint localization into a matching procedure between the pose kernels and the current frame, which can be efficiently computed via simple convolution. In this way, DKD fast transfers pose knowledge from one frame to provide compact guidance for body joint localization in the following frame, which enables utilization of small networks in video-based pose estimation. To facilitate the training process, DKD exploits a temporally adversarial training strategy that introduces a temporal discriminator to help generate temporally coherent pose kernels and pose estimation results within a long range. Experiments on Penn Action and Sub-JHMDB benchmarks demonstrate outperforming efficiency of DKD, specifically, 10x flops reduction and 2x speedup over previous best model, and its state-of-the-art accuracy.
Weakly Supervised Body Part Parsing with Pose based Part Priors
Jul 30, 2019
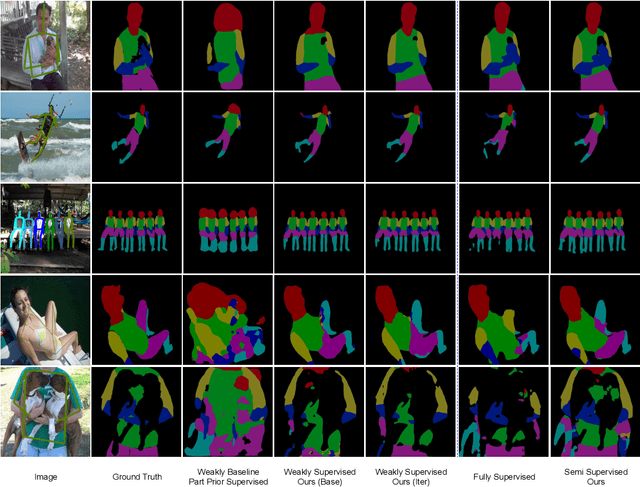

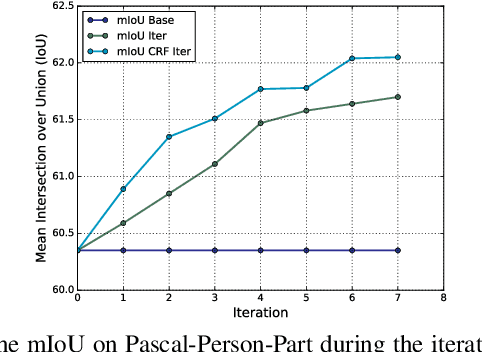
Human body part parsing refers to the task of predicting the semantic segmentation mask for each body part. Fully supervised body part parsing methods achieve good performances, but require an enormous amount of effort to annotate part masks for training. In contrast to high annotation costs required for a limited number of part mask annotations, a large number of weak labels such as poses and full body masks already exist and contain relevant information. Motivated by the possibility of using existing weak labels, we propose the first weakly supervised body part parsing framework. The basic idea is to train a parsing network with pose generated part priors that has blank uncertain regions on estimated boundaries, and use an iterative refinement module to generate new supervision and predictions on these regions. When sufficient extra weak supervisions are available, our weakly-supervised results (62.0% mIoU) on Pascal-Person-Part are comparable to the fully supervised state-of-the-art results (63.6% mIoU). Furthermore, in the extended semi-supervised setting, the proposed framework outperforms the state-of-art methods. In addition, we show that the proposed framework can be extended to other keypoint-supervised part parsing tasks such as face parsing.
Laplace Landmark Localization
Mar 27, 2019
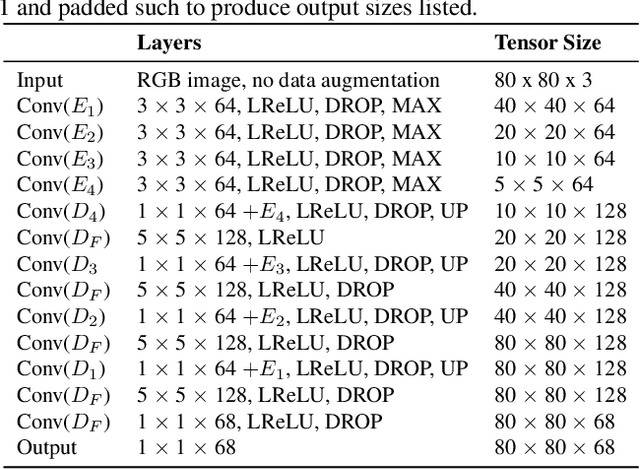
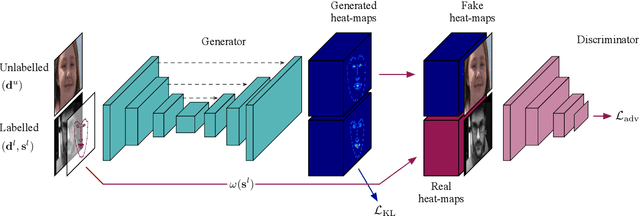
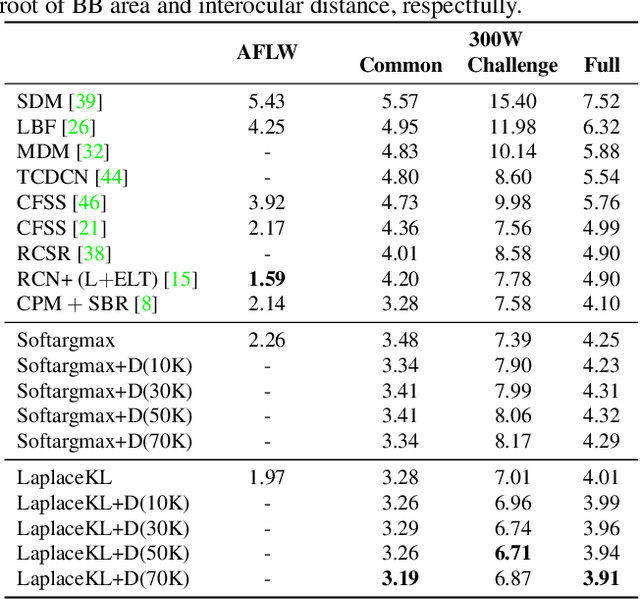
Landmark localization in images and videos is a classic problem solved in various ways. Nowadays, with deep networks prevailing throughout machine learning, there are revamped interests in pushing facial landmark detection technologies to handle more challenging data. Most efforts use network objectives based on L1 or L2 norms, which have several disadvantages. First of all, the locations of landmarks are determined from generated heatmaps (i.e., confidence maps) from which predicted landmark locations (i.e., the means) get penalized without accounting for the spread: a high scatter corresponds to low confidence and vice-versa. For this, we introduce a LaplaceKL objective that penalizes for a low confidence. Another issue is a dependency on labeled data, which are expensive to obtain and susceptible to error. To address both issues we propose an adversarial training framework that leverages unlabeled data to improve model performance. Our method claims state-of-the-art on all of the 300W benchmarks and ranks second-to-best on the Annotated Facial Landmarks in the Wild (AFLW) dataset. Furthermore, our model is robust with a reduced size: 1/8 the number of channels (i.e., 0.0398MB) is comparable to state-of-that-art in real-time on CPU. Thus, we show that our method is of high practical value to real-life application.
3D Hand Shape and Pose Estimation from a Single RGB Image
Mar 03, 2019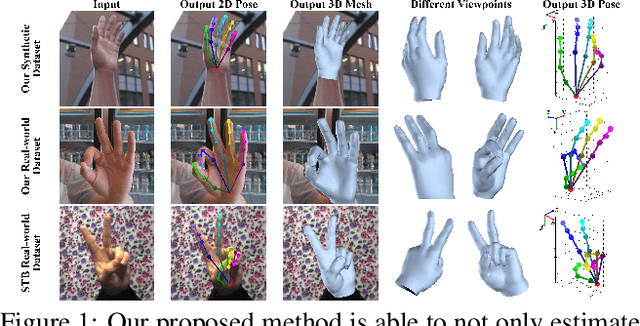



This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
Skin Disease Classification versus Skin Lesion Characterization: Achieving Robust Diagnosis using Multi-label Deep Neural Networks
Dec 09, 2018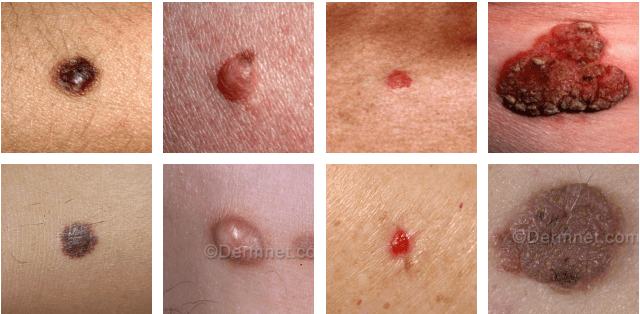
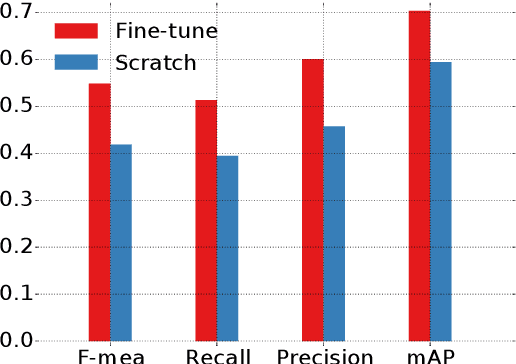
In this study, we investigate what a practically useful approach is in order to achieve robust skin disease diagnosis. A direct approach is to target the ground truth diagnosis labels, while an alternative approach instead focuses on determining skin lesion characteristics that are more visually consistent and discernible. We argue that, for computer-aided skin disease diagnosis, it is both more realistic and more useful that lesion type tags should be considered as the target of an automated diagnosis system such that the system can first achieve a high accuracy in describing skin lesions, and in turn facilitate disease diagnosis using lesion characteristics in conjunction with other evidence. To further meet such an objective, we employ convolutional neural networks (CNNs) for both the disease-targeted and lesion-targeted classifications. We have collected a large-scale and diverse dataset of 75,665 skin disease images from six publicly available dermatology atlantes. Then we train and compare both disease-targeted and lesion-targeted classifiers, respectively. For disease-targeted classification, only 27.6% top-1 accuracy and 57.9% top-5 accuracy are achieved with a mean average precision (mAP) of 0.42. In contrast, for lesion-targeted classification, we can achieve a much higher mAP of 0.70.
Action Recognition with Spatio-Temporal Visual Attention on Skeleton Image Sequences
Apr 11, 2018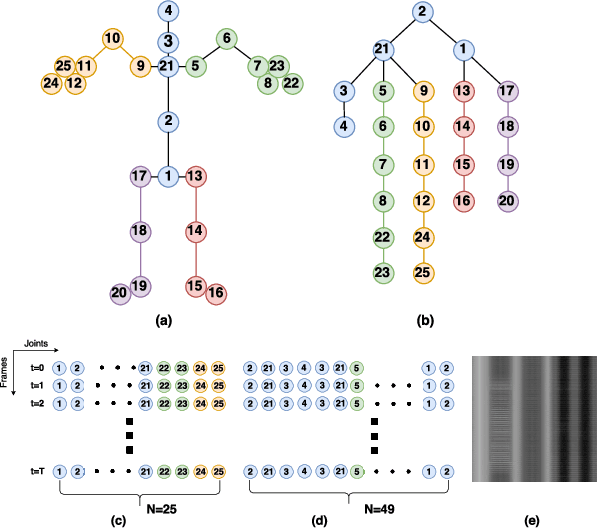

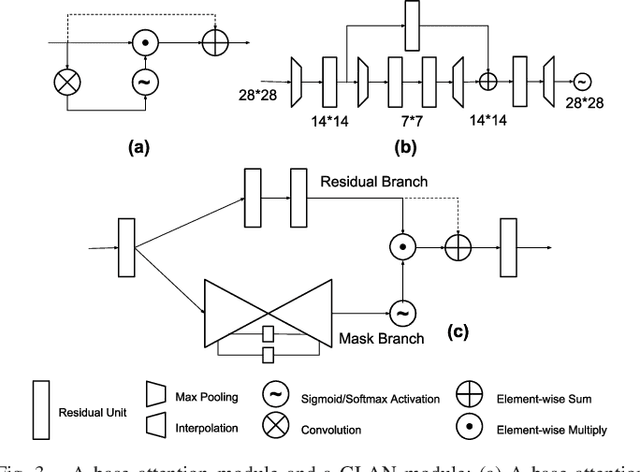
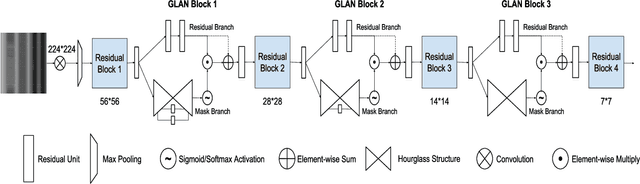
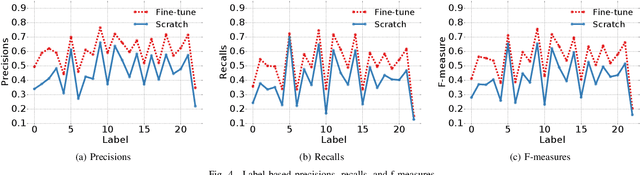
Action recognition with 3D skeleton sequences is becoming popular due to its speed and robustness. The recently proposed Convolutional Neural Networks (CNN) based methods have shown good performance in learning spatio-temporal representations for skeleton sequences. Despite the good recognition accuracy achieved by previous CNN based methods, there exist two problems that potentially limit the performance. First, previous skeleton representations are generated by chaining joints with a fixed order. The corresponding semantic meaning is unclear and the structural information among the joints is lost. Second, previous models do not have an ability to focus on informative joints. The attention mechanism is important for skeleton based action recognition because there exist spatio-temporal key stages while the joint predictions can be inaccurate. To solve these two problems, we propose a novel CNN based method for skeleton based action recognition. We first redesign the skeleton representations with a depth-first tree traversal order, which enhances the semantic meaning of skeleton images and better preserves the associated structural information. We then propose the idea of a two-branch attention architecture that focuses on spatio-temporal key stages and filters out unreliable joint predictions. A base attention model with the simplest structure is first introduced. By improving the structures in both branches, we further propose a Global Long-sequence Attention Network (GLAN). Furthermore, in order to adjust the kernel's spatio-temporal aspect ratios and better capture long term dependencies, we propose a Sub-Sequence Attention Network (SSAN) that takes sub-image sequences as inputs. Our experiment results on NTU RGB+D and SBU Kinetic Interaction outperforms the state-of-the-art. The model is further validated on noisy estimated poses from UCF101 and Kinetics.
Asynchronous Parallel Stochastic Gradient for Nonconvex Optimization
Jun 10, 2017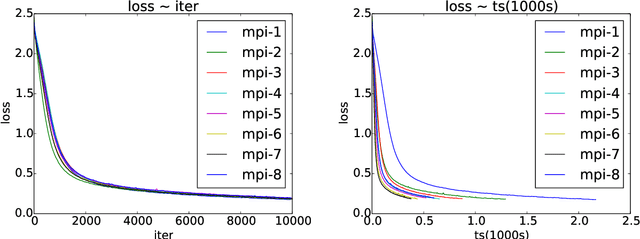

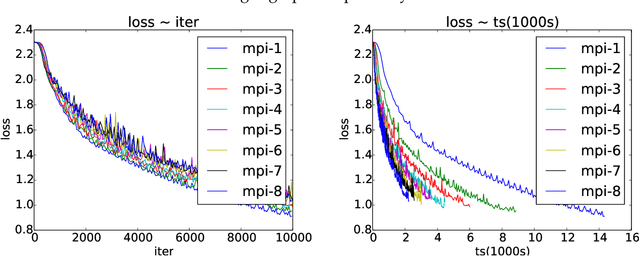

Asynchronous parallel implementations of stochastic gradient (SG) have been broadly used in solving deep neural network and received many successes in practice recently. However, existing theories cannot explain their convergence and speedup properties, mainly due to the nonconvexity of most deep learning formulations and the asynchronous parallel mechanism. To fill the gaps in theory and provide theoretical supports, this paper studies two asynchronous parallel implementations of SG: one is on the computer network and the other is on the shared memory system. We establish an ergodic convergence rate $O(1/\sqrt{K})$ for both algorithms and prove that the linear speedup is achievable if the number of workers is bounded by $\sqrt{K}$ ($K$ is the total number of iterations). Our results generalize and improve existing analysis for convex minimization.
Improving Pairwise Ranking for Multi-label Image Classification
Jun 01, 2017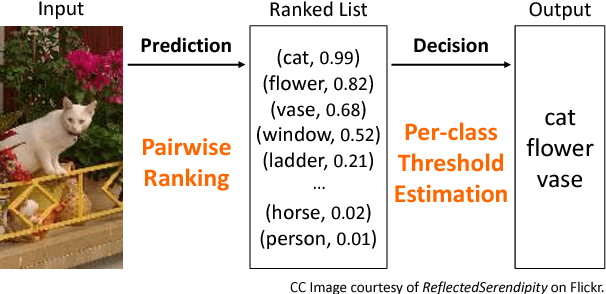
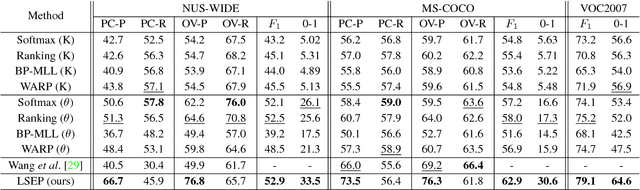

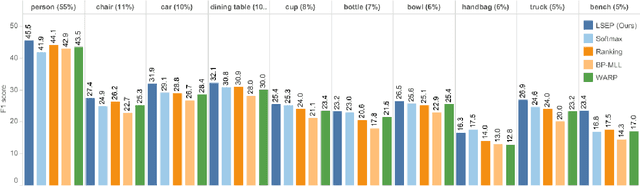
Learning to rank has recently emerged as an attractive technique to train deep convolutional neural networks for various computer vision tasks. Pairwise ranking, in particular, has been successful in multi-label image classification, achieving state-of-the-art results on various benchmarks. However, most existing approaches use the hinge loss to train their models, which is non-smooth and thus is difficult to optimize especially with deep networks. Furthermore, they employ simple heuristics, such as top-k or thresholding, to determine which labels to include in the output from a ranked list of labels, which limits their use in the real-world setting. In this work, we propose two techniques to improve pairwise ranking based multi-label image classification: (1) we propose a novel loss function for pairwise ranking, which is smooth everywhere and thus is easier to optimize; and (2) we incorporate a label decision module into the model, estimating the optimal confidence thresholds for each visual concept. We provide theoretical analyses of our loss function in the Bayes consistency and risk minimization framework, and show its benefit over existing pairwise ranking formulations. We demonstrate the effectiveness of our approach on three large-scale datasets, VOC2007, NUS-WIDE and MS-COCO, achieving the best reported results in the literature.