 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Your Imagination with Audio-Video Generation via a Unified Director
Dec 29, 2025Existing AI-driven video creation systems typically treat script drafting and key-shot design as two disjoint tasks: the former relies on large language models, while the latter depends on image generation models. We argue that these two tasks should be unified within a single framework, as logical reasoning and imaginative thinking are both fundamental qualities of a film director. In this work, we propose UniMAGE, a unified director model that bridges user prompts with well-structured scripts, thereby empowering non-experts to produce long-context, multi-shot films by leveraging existing audio-video generation models. To achieve this, we employ the Mixture-of-Transformers architecture that unifies text and image generation. To further enhance narrative logic and keyframe consistency, we introduce a ``first interleaving, then disentangling'' training paradigm. Specifically, we first perform Interleaved Concept Learning, which utilizes interleaved text-image data to foster the model's deeper understanding and imaginative interpretation of scripts. We then conduct Disentangled Expert Learning, which decouples script writing from keyframe generation, enabling greater flexibility and creativity in storytelling. Extensive experiments demonstrate that UniMAGE achieves state-of-the-art performance among open-source models, generating logically coherent video scripts and visually consistent keyframe images.
Lynx: Towards High-Fidelity Personalized Video Generation
Sep 19, 2025We present Lynx, a high-fidelity model for personalized video synthesis from a single input image. Built on an open-source Diffusion Transformer (DiT) foundation model, Lynx introduces two lightweight adapters to ensure identity fidelity. The ID-adapter employs a Perceiver Resampler to convert ArcFace-derived facial embeddings into compact identity tokens for conditioning, while the Ref-adapter integrates dense VAE features from a frozen reference pathway, injecting fine-grained details across all transformer layers through cross-attention. These modules collectively enable robust identity preservation while maintaining temporal coherence and visual realism. Through evaluation on a curated benchmark of 40 subjects and 20 unbiased prompts, which yielded 800 test cases, Lynx has demonstrated superior face resemblance, competitive prompt following, and strong video quality, thereby advancing the state of personalized video generation.
X-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection
Nov 26, 2024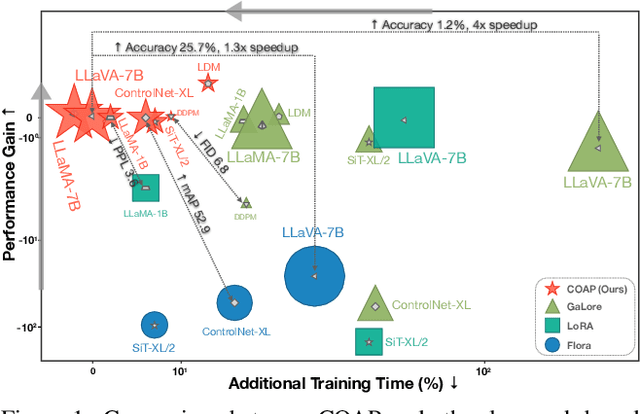
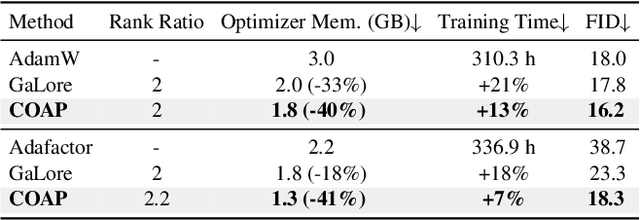
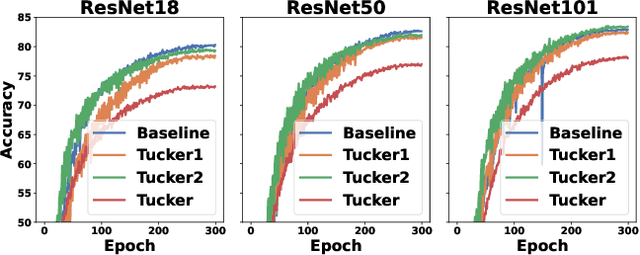
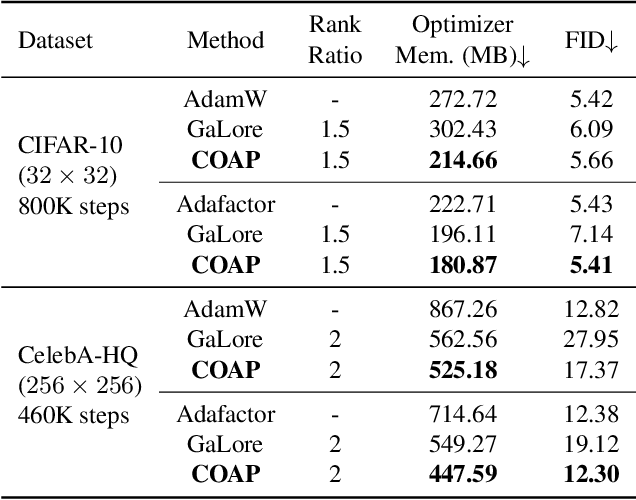
Training large-scale neural networks in vision, and multimodal domains demands substantial memory resources, primarily due to the storage of optimizer states. While LoRA, a popular parameter-efficient method, reduces memory usage, it often suffers from suboptimal performance due to the constraints of low-rank updates. Low-rank gradient projection methods (e.g., GaLore, Flora) reduce optimizer memory by projecting gradients and moment estimates into low-rank spaces via singular value decomposition or random projection. However, they fail to account for inter-projection correlation, causing performance degradation, and their projection strategies often incur high computational costs. In this paper, we present COAP (Correlation-Aware Gradient Projection), a memory-efficient method that minimizes computational overhead while maintaining training performance. Evaluated across various vision, language, and multimodal tasks, COAP outperforms existing methods in both training speed and model performance. For LLaMA-1B, it reduces optimizer memory by 61% with only 2% additional time cost, achieving the same PPL as AdamW. With 8-bit quantization, COAP cuts optimizer memory by 81% and achieves 4x speedup over GaLore for LLaVA-v1.5-7B fine-tuning, while delivering higher accuracy.
ID-Patch: Robust ID Association for Group Photo Personalization
Nov 20, 2024



The ability to synthesize personalized group photos and specify the positions of each identity offers immense creative potential. While such imagery can be visually appealing, it presents significant challenges for existing technologies. A persistent issue is identity (ID) leakage, where injected facial features interfere with one another, resulting in low face resemblance, incorrect positioning, and visual artifacts. Existing methods suffer from limitations such as the reliance on segmentation models, increased runtime, or a high probability of ID leakage. To address these challenges, we propose ID-Patch, a novel method that provides robust association between identities and 2D positions. Our approach generates an ID patch and ID embeddings from the same facial features: the ID patch is positioned on the conditional image for precise spatial control, while the ID embeddings integrate with text embeddings to ensure high resemblance. Experimental results demonstrate that ID-Patch surpasses baseline methods across metrics, such as face ID resemblance, ID-position association accuracy, and generation efficiency. Project Page is: https://byteaigc.github.io/ID-Patch/
High Quality Human Image Animation using Regional Supervision and Motion Blur Condition
Sep 29, 2024



Recent advances in video diffusion models have enabled realistic and controllable human image animation with temporal coherence. Although generating reasonable results, existing methods often overlook the need for regional supervision in crucial areas such as the face and hands, and neglect the explicit modeling for motion blur, leading to unrealistic low-quality synthesis. To address these limitations, we first leverage regional supervision for detailed regions to enhance face and hand faithfulness. Second, we model the motion blur explicitly to further improve the appearance quality. Third, we explore novel training strategies for high-resolution human animation to improve the overall fidelity. Experimental results demonstrate that our proposed method outperforms state-of-the-art approaches, achieving significant improvements upon the strongest baseline by more than 21.0% and 57.4% in terms of reconstruction precision (L1) and perceptual quality (FVD) on HumanDance dataset. Code and model will be made available.
Learning Feature-Preserving Portrait Editing from Generated Pairs
Jul 29, 2024Portrait editing is challenging for existing techniques due to difficulties in preserving subject features like identity. In this paper, we propose a training-based method leveraging auto-generated paired data to learn desired editing while ensuring the preservation of unchanged subject features. Specifically, we design a data generation process to create reasonably good training pairs for desired editing at low cost. Based on these pairs, we introduce a Multi-Conditioned Diffusion Model to effectively learn the editing direction and preserve subject features. During inference, our model produces accurate editing mask that can guide the inference process to further preserve detailed subject features. Experiments on costume editing and cartoon expression editing show that our method achieves state-of-the-art quality, quantitatively and qualitatively.
X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention
Mar 27, 2024We propose X-Portrait, an innovative conditional diffusion model tailored for generating expressive and temporally coherent portrait animation. Specifically, given a single portrait as appearance reference, we aim to animate it with motion derived from a driving video, capturing both highly dynamic and subtle facial expressions along with wide-range head movements. As its core, we leverage the generative prior of a pre-trained diffusion model as the rendering backbone, while achieve fine-grained head pose and expression control with novel controlling signals within the framework of ControlNet. In contrast to conventional coarse explicit controls such as facial landmarks, our motion control module is learned to interpret the dynamics directly from the original driving RGB inputs. The motion accuracy is further enhanced with a patch-based local control module that effectively enhance the motion attention to small-scale nuances like eyeball positions. Notably, to mitigate the identity leakage from the driving signals, we train our motion control modules with scaling-augmented cross-identity images, ensuring maximized disentanglement from the appearance reference modules. Experimental results demonstrate the universal effectiveness of X-Portrait across a diverse range of facial portraits and expressive driving sequences, and showcase its proficiency in generating captivating portrait animations with consistently maintained identity characteristics.
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Dec 22, 2023



We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.