 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Multi-sensor Conditioning for Street-view Novel-view Synthesis
Jun 01, 2026Modern vehicle platforms are equipped with a rich sensor suite, including LiDAR, calibrated multi-camera rigs, and accurate ego-motion, that in principle offers strong signal for re-rendering a driving scene from novel viewpoints. A growing line of recent work leverages video diffusion models for this task, using their generative priors to synthesize plausible novel views from sparse vehicle observations. In practice, however, existing methods exploit only a fragment of this signal, and their quality tends to degrade as the target trajectory departs from the recorded driving path. We argue that this is fundamentally a multi-sensor fusion problem: sparse LiDAR reprojections supply accurate but incomplete metric geometry, surround-view reference imagery supplies dense appearance but no metric depth, and camera poses tie the two together across views. We introduce StreetNVS, a video diffusion framework that jointly conditions on all three signals through a Reference-Enhanced Camera Attention module based on a relative ray-level positional encoding. We develop a two-stage curriculum training strategy that gradually exposes the model to increasingly sparse LiDAR. On the Waymo Open Dataset, StreetNVS substantially outperforms state-of-the-art baselines under sparse LiDAR conditioning, matches methods that rely on 10-100 times denser point clouds. We further show capabilities of synthesizing coherent videos along extreme out-of-trajectory paths such as elevation, lane-shift, pullback, and rotation. Our website: https://streetnvs.github.io
GeoFlow: Enforcing Implicit Geometric Consistency in Video Generation
May 18, 2026Generating geometrically consistent videos remains an open challenge: text-to-video diffusion models trained on web-scale data treat geometry only implicitly, leading to object deformation, texture drift, and non-rigid backgrounds under camera motion. Existing solutions either improve consistency as a byproduct, apply only to static scenes or realign the latent space of the model completely. We introduce a geometry-consistency reward that directly measures whether motion in a generated video is compatible with a coherent scene. Our key insight is that in physically consistent videos, background motion should be explainable by rigid camera-induced flow, while independently moving objects should preserve appearance identity along motion trajectories. We operationalize this using optical flow, depth--pose predictions, and feature-based correspondence to separate rigid and dynamic regions and evaluate their respective consistency. Integrating this reward with reinforcement fine-tuning transforms geometric consistency from an emergent property into an explicit optimization objective for video generators. The approach is model agnostic and applies to diverse dynamic scenes containing both camera and object motion. Experiments show substantial reductions in temporal geometric artifacts over strong baselines while preserving perceptual quality. Code and model weights are published.
Envision: Embodied Visual Planning via Goal-Imagery Video Diffusion
Dec 27, 2025Embodied visual planning aims to enable manipulation tasks by imagining how a scene evolves toward a desired goal and using the imagined trajectories to guide actions. Video diffusion models, through their image-to-video generation capability, provide a promising foundation for such visual imagination. However, existing approaches are largely forward predictive, generating trajectories conditioned on the initial observation without explicit goal modeling, thus often leading to spatial drift and goal misalignment. To address these challenges, we propose Envision, a diffusion-based framework that performs visual planning for embodied agents. By explicitly constraining the generation with a goal image, our method enforces physical plausibility and goal consistency throughout the generated trajectory. Specifically, Envision operates in two stages. First, a Goal Imagery Model identifies task-relevant regions, performs region-aware cross attention between the scene and the instruction, and synthesizes a coherent goal image that captures the desired outcome. Then, an Env-Goal Video Model, built upon a first-and-last-frame-conditioned video diffusion model (FL2V), interpolates between the initial observation and the goal image, producing smooth and physically plausible video trajectories that connect the start and goal states. Experiments on object manipulation and image editing benchmarks demonstrate that Envision achieves superior goal alignment, spatial consistency, and object preservation compared to baselines. The resulting visual plans can directly support downstream robotic planning and control, providing reliable guidance for embodied agents.
VULCAN: Tool-Augmented Multi Agents for Iterative 3D Object Arrangement
Dec 26, 2025Despite the remarkable progress of Multimodal Large Language Models (MLLMs) in 2D vision-language tasks, their application to complex 3D scene manipulation remains underexplored. In this paper, we bridge this critical gap by tackling three key challenges in 3D object arrangement task using MLLMs. First, to address the weak visual grounding of MLLMs, which struggle to link programmatic edits with precise 3D outcomes, we introduce an MCP-based API. This shifts the interaction from brittle raw code manipulation to more robust, function-level updates. Second, we augment the MLLM's 3D scene understanding with a suite of specialized visual tools to analyze scene state, gather spatial information, and validate action outcomes. This perceptual feedback loop is critical for closing the gap between language-based updates and precise 3D-aware manipulation. Third, to manage the iterative, error-prone updates, we propose a collaborative multi-agent framework with designated roles for planning, execution, and verification. This decomposition allows the system to robustly handle multi-step instructions and recover from intermediate errors. We demonstrate the effectiveness of our approach on a diverse set of 25 complex object arrangement tasks, where it significantly outperforms existing baselines. Website: vulcan-3d.github.io
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.
Buffer Anytime: Zero-Shot Video Depth and Normal from Image Priors
Nov 26, 2024We present Buffer Anytime, a framework for estimation of depth and normal maps (which we call geometric buffers) from video that eliminates the need for paired video--depth and video--normal training data. Instead of relying on large-scale annotated video datasets, we demonstrate high-quality video buffer estimation by leveraging single-image priors with temporal consistency constraints. Our zero-shot training strategy combines state-of-the-art image estimation models based on optical flow smoothness through a hybrid loss function, implemented via a lightweight temporal attention architecture. Applied to leading image models like Depth Anything V2 and Marigold-E2E-FT, our approach significantly improves temporal consistency while maintaining accuracy. Experiments show that our method not only outperforms image-based approaches but also achieves results comparable to state-of-the-art video models trained on large-scale paired video datasets, despite using no such paired video data.
RelitLRM: Generative Relightable Radiance for Large Reconstruction Models
Oct 10, 2024



We propose RelitLRM, a Large Reconstruction Model (LRM) for generating high-quality Gaussian splatting representations of 3D objects under novel illuminations from sparse (4-8) posed images captured under unknown static lighting. Unlike prior inverse rendering methods requiring dense captures and slow optimization, often causing artifacts like incorrect highlights or shadow baking, RelitLRM adopts a feed-forward transformer-based model with a novel combination of a geometry reconstructor and a relightable appearance generator based on diffusion. The model is trained end-to-end on synthetic multi-view renderings of objects under varying known illuminations. This architecture design enables to effectively decompose geometry and appearance, resolve the ambiguity between material and lighting, and capture the multi-modal distribution of shadows and specularity in the relit appearance. We show our sparse-view feed-forward RelitLRM offers competitive relighting results to state-of-the-art dense-view optimization-based baselines while being significantly faster. Our project page is available at: https://relit-lrm.github.io/.
Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
May 27, 2024



Research on video generation has recently made tremendous progress, enabling high-quality videos to be generated from text prompts or images. Adding control to the video generation process is an important goal moving forward and recent approaches that condition video generation models on camera trajectories make strides towards it. Yet, it remains challenging to generate a video of the same scene from multiple different camera trajectories. Solutions to this multi-video generation problem could enable large-scale 3D scene generation with editable camera trajectories, among other applications. We introduce collaborative video diffusion (CVD) as an important step towards this vision. The CVD framework includes a novel cross-video synchronization module that promotes consistency between corresponding frames of the same video rendered from different camera poses using an epipolar attention mechanism. Trained on top of a state-of-the-art camera-control module for video generation, CVD generates multiple videos rendered from different camera trajectories with significantly better consistency than baselines, as shown in extensive experiments. Project page: https://collaborativevideodiffusion.github.io/.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023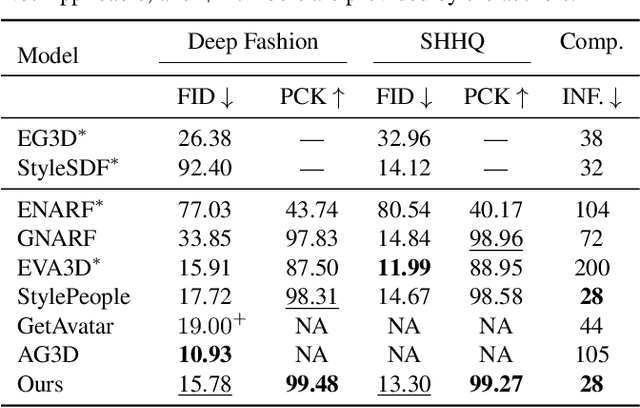



Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.
Stanford-ORB: A Real-World 3D Object Inverse Rendering Benchmark
Oct 25, 2023



We introduce Stanford-ORB, a new real-world 3D Object inverse Rendering Benchmark. Recent advances in inverse rendering have enabled a wide range of real-world applications in 3D content generation, moving rapidly from research and commercial use cases to consumer devices. While the results continue to improve, there is no real-world benchmark that can quantitatively assess and compare the performance of various inverse rendering methods. Existing real-world datasets typically only consist of the shape and multi-view images of objects, which are not sufficient for evaluating the quality of material recovery and object relighting. Methods capable of recovering material and lighting often resort to synthetic data for quantitative evaluation, which on the other hand does not guarantee generalization to complex real-world environments. We introduce a new dataset of real-world objects captured under a variety of natural scenes with ground-truth 3D scans, multi-view images, and environment lighting. Using this dataset, we establish the first comprehensive real-world evaluation benchmark for object inverse rendering tasks from in-the-wild scenes, and compare the performance of various existing methods.