 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStanford-ORB: A Real-World 3D Object Inverse Rendering Benchmark
Oct 25, 2023



We introduce Stanford-ORB, a new real-world 3D Object inverse Rendering Benchmark. Recent advances in inverse rendering have enabled a wide range of real-world applications in 3D content generation, moving rapidly from research and commercial use cases to consumer devices. While the results continue to improve, there is no real-world benchmark that can quantitatively assess and compare the performance of various inverse rendering methods. Existing real-world datasets typically only consist of the shape and multi-view images of objects, which are not sufficient for evaluating the quality of material recovery and object relighting. Methods capable of recovering material and lighting often resort to synthetic data for quantitative evaluation, which on the other hand does not guarantee generalization to complex real-world environments. We introduce a new dataset of real-world objects captured under a variety of natural scenes with ground-truth 3D scans, multi-view images, and environment lighting. Using this dataset, we establish the first comprehensive real-world evaluation benchmark for object inverse rendering tasks from in-the-wild scenes, and compare the performance of various existing methods.
Accidental Light Probes
Jan 12, 2023
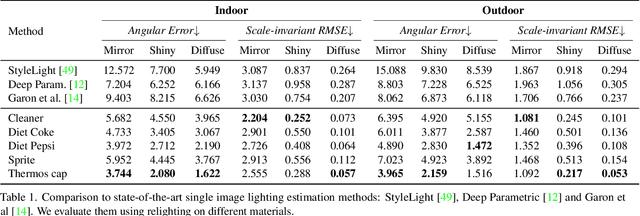
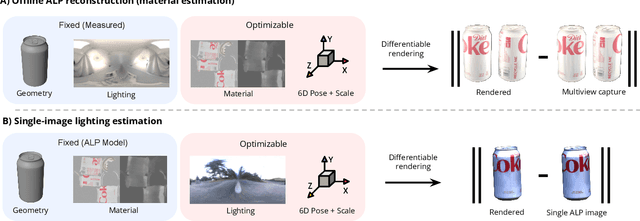
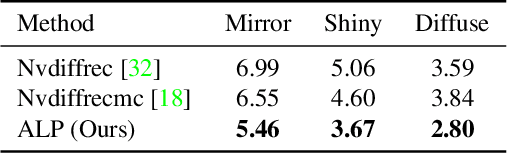
Recovering lighting in a scene from a single image is a fundamental problem in computer vision. While a mirror ball light probe can capture omnidirectional lighting, light probes are generally unavailable in everyday images. In this work, we study recovering lighting from accidental light probes (ALPs) -- common, shiny objects like Coke cans, which often accidentally appear in daily scenes. We propose a physically-based approach to model ALPs and estimate lighting from their appearances in single images. The main idea is to model the appearance of ALPs by photogrammetrically principled shading and to invert this process via differentiable rendering to recover incidental illumination. We demonstrate that we can put an ALP into a scene to allow high-fidelity lighting estimation. Our model can also recover lighting for existing images that happen to contain an ALP.
PlaneFormers: From Sparse View Planes to 3D Reconstruction
Aug 08, 2022

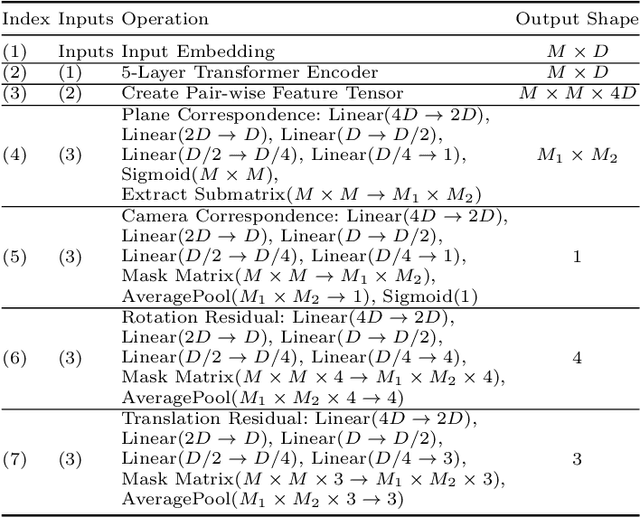
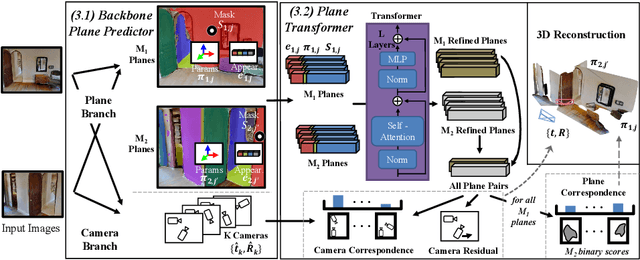
We present an approach for the planar surface reconstruction of a scene from images with limited overlap. This reconstruction task is challenging since it requires jointly reasoning about single image 3D reconstruction, correspondence between images, and the relative camera pose between images. Past work has proposed optimization-based approaches. We introduce a simpler approach, the PlaneFormer, that uses a transformer applied to 3D-aware plane tokens to perform 3D reasoning. Our experiments show that our approach is substantially more effective than prior work, and that several 3D-specific design decisions are crucial for its success.