 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshtryoshka: Differentiable Rendering of Real-World Scenes via Mesh Rasterization
Jun 26, 2026Differentiable rendering has emerged as a powerful approach for 3D reconstruction and novel view synthesis. State-of-the-art differentiable rendering methods combine a variety of custom representations of 3D geometry and appearance with specialized renderers. However, most downstream tasks in computer graphics rely on 3D meshes. While prior work has attempted differentiable rendering with mesh representations, these approaches are limited to object-centric scenes and fail to reconstruct large-scale, unbounded scenes. In this work, we introduce Meshtryoshka, a novel mesh differentiable rendering framework that combines an off-the-shelf triangle rasterizer with a 3D representation that consists of nested mesh shells which resemble a matryoshka doll. In every forward pass, the mesh shells are extracted anew from a 3D signed distance function via iso-surface extraction, and the opacities for each vertex are computed as a function of signed distance. Each mesh shell is then rasterized independently, and the final image is created via alpha compositing. Crucially, mesh vertex positions are updated only indirectly via gradients that flow through the opacity values into the signed distance function, and hence, our method is compatible with off-the-shelf mesh renderers that need not be differentiable with respect to vertex positions. On object-centric scenes, our method performs competitively with surface-based differentiable rendering techniques. Our differentiable mesh rendering method scales to unbounded, real-world 3D scenes, where it yields high-quality novel view synthesis results approaching those of state-of-the-art, non-mesh methods. Our method suggests that it may be possible to solve the differentiable rendering problem without relying on specialized renderers, only using conventional tools from the computer graphics toolbox.
NeRF-Casting: Improved View-Dependent Appearance with Consistent Reflections
May 23, 2024

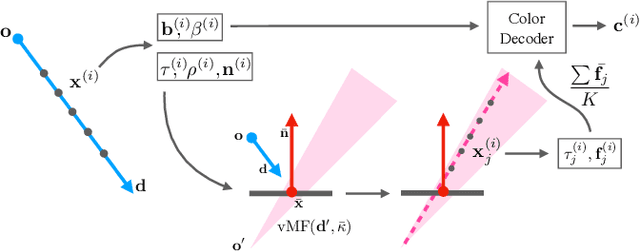

Neural Radiance Fields (NeRFs) typically struggle to reconstruct and render highly specular objects, whose appearance varies quickly with changes in viewpoint. Recent works have improved NeRF's ability to render detailed specular appearance of distant environment illumination, but are unable to synthesize consistent reflections of closer content. Moreover, these techniques rely on large computationally-expensive neural networks to model outgoing radiance, which severely limits optimization and rendering speed. We address these issues with an approach based on ray tracing: instead of querying an expensive neural network for the outgoing view-dependent radiance at points along each camera ray, our model casts reflection rays from these points and traces them through the NeRF representation to render feature vectors which are decoded into color using a small inexpensive network. We demonstrate that our model outperforms prior methods for view synthesis of scenes containing shiny objects, and that it is the only existing NeRF method that can synthesize photorealistic specular appearance and reflections in real-world scenes, while requiring comparable optimization time to current state-of-the-art view synthesis models.
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Feb 19, 2024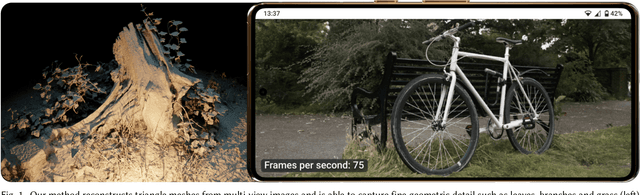



While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
UniSDF: Unifying Neural Representations for High-Fidelity 3D Reconstruction of Complex Scenes with Reflections
Dec 20, 2023Neural 3D scene representations have shown great potential for 3D reconstruction from 2D images. However, reconstructing real-world captures of complex scenes still remains a challenge. Existing generic 3D reconstruction methods often struggle to represent fine geometric details and do not adequately model reflective surfaces of large-scale scenes. Techniques that explicitly focus on reflective surfaces can model complex and detailed reflections by exploiting better reflection parameterizations. However, we observe that these methods are often not robust in real unbounded scenarios where non-reflective as well as reflective components are present. In this work, we propose UniSDF, a general purpose 3D reconstruction method that can reconstruct large complex scenes with reflections. We investigate both view-based as well as reflection-based color prediction parameterization techniques and find that explicitly blending these representations in 3D space enables reconstruction of surfaces that are more geometrically accurate, especially for reflective surfaces. We further combine this representation with a multi-resolution grid backbone that is trained in a coarse-to-fine manner, enabling faster reconstructions than prior methods. Extensive experiments on object-level datasets DTU, Shiny Blender as well as unbounded datasets Mip-NeRF 360 and Ref-NeRF real demonstrate that our method is able to robustly reconstruct complex large-scale scenes with fine details and reflective surfaces. Please see our project page at https://fangjinhuawang.github.io/UniSDF.
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
Dec 12, 2023



Recent techniques for real-time view synthesis have rapidly advanced in fidelity and speed, and modern methods are capable of rendering near-photorealistic scenes at interactive frame rates. At the same time, a tension has arisen between explicit scene representations amenable to rasterization and neural fields built on ray marching, with state-of-the-art instances of the latter surpassing the former in quality while being prohibitively expensive for real-time applications. In this work, we introduce SMERF, a view synthesis approach that achieves state-of-the-art accuracy among real-time methods on large scenes with footprints up to 300 m$^2$ at a volumetric resolution of 3.5 mm$^3$. Our method is built upon two primary contributions: a hierarchical model partitioning scheme, which increases model capacity while constraining compute and memory consumption, and a distillation training strategy that simultaneously yields high fidelity and internal consistency. Our approach enables full six degrees of freedom (6DOF) navigation within a web browser and renders in real-time on commodity smartphones and laptops. Extensive experiments show that our method exceeds the current state-of-the-art in real-time novel view synthesis by 0.78 dB on standard benchmarks and 1.78 dB on large scenes, renders frames three orders of magnitude faster than state-of-the-art radiance field models, and achieves real-time performance across a wide variety of commodity devices, including smartphones. We encourage the reader to explore these models in person at our project website: https://smerf-3d.github.io.
BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
Feb 28, 2023
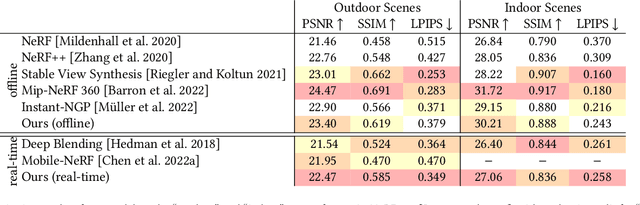

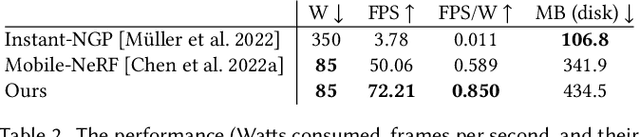
We present a method for reconstructing high-quality meshes of large unbounded real-world scenes suitable for photorealistic novel view synthesis. We first optimize a hybrid neural volume-surface scene representation designed to have well-behaved level sets that correspond to surfaces in the scene. We then bake this representation into a high-quality triangle mesh, which we equip with a simple and fast view-dependent appearance model based on spherical Gaussians. Finally, we optimize this baked representation to best reproduce the captured viewpoints, resulting in a model that can leverage accelerated polygon rasterization pipelines for real-time view synthesis on commodity hardware. Our approach outperforms previous scene representations for real-time rendering in terms of accuracy, speed, and power consumption, and produces high quality meshes that enable applications such as appearance editing and physical simulation.
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Feb 23, 2023



Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.
Accidental Light Probes
Jan 12, 2023
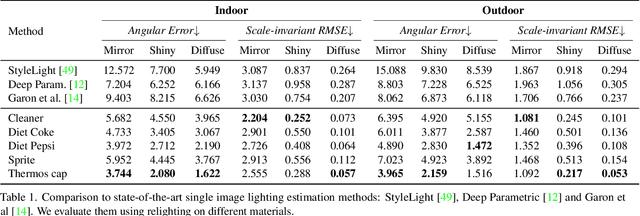
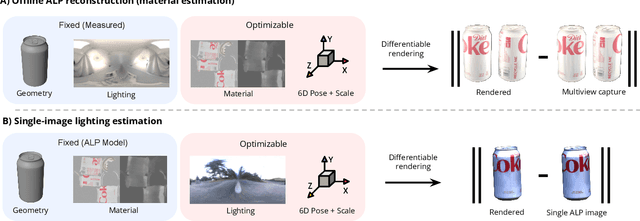
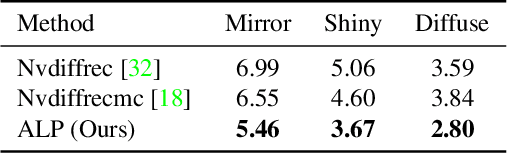
Recovering lighting in a scene from a single image is a fundamental problem in computer vision. While a mirror ball light probe can capture omnidirectional lighting, light probes are generally unavailable in everyday images. In this work, we study recovering lighting from accidental light probes (ALPs) -- common, shiny objects like Coke cans, which often accidentally appear in daily scenes. We propose a physically-based approach to model ALPs and estimate lighting from their appearances in single images. The main idea is to model the appearance of ALPs by photogrammetrically principled shading and to invert this process via differentiable rendering to recover incidental illumination. We demonstrate that we can put an ALP into a scene to allow high-fidelity lighting estimation. Our model can also recover lighting for existing images that happen to contain an ALP.
Animating Pictures with Eulerian Motion Fields
Nov 30, 2020
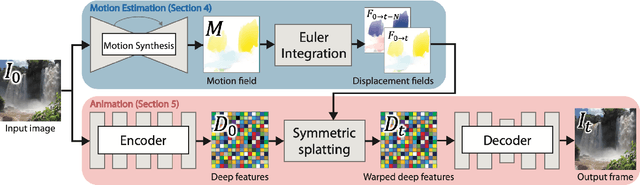
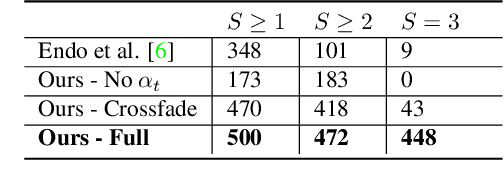

In this paper, we demonstrate a fully automatic method for converting a still image into a realistic animated looping video. We target scenes with continuous fluid motion, such as flowing water and billowing smoke. Our method relies on the observation that this type of natural motion can be convincingly reproduced from a static Eulerian motion description, i.e. a single, temporally constant flow field that defines the immediate motion of a particle at a given 2D location. We use an image-to-image translation network to encode motion priors of natural scenes collected from online videos, so that for a new photo, we can synthesize a corresponding motion field. The image is then animated using the generated motion through a deep warping technique: pixels are encoded as deep features, those features are warped via Eulerian motion, and the resulting warped feature maps are decoded as images. In order to produce continuous, seamlessly looping video textures, we propose a novel video looping technique that flows features both forward and backward in time and then blends the results. We demonstrate the effectiveness and robustness of our method by applying it to a large collection of examples including beaches, waterfalls, and flowing rivers.
Reducing Drift in Structure from Motion using Extended Features
Aug 27, 2020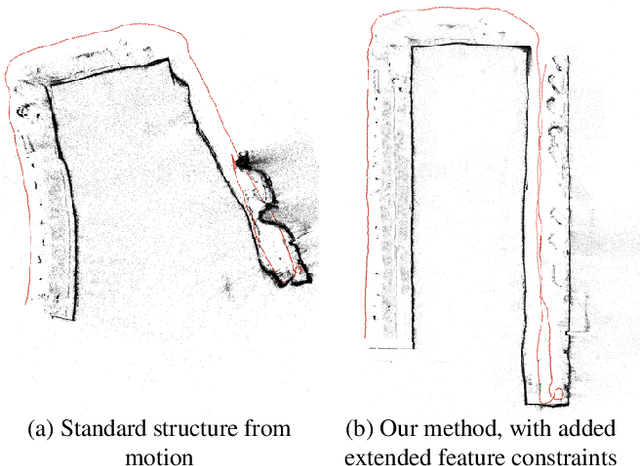
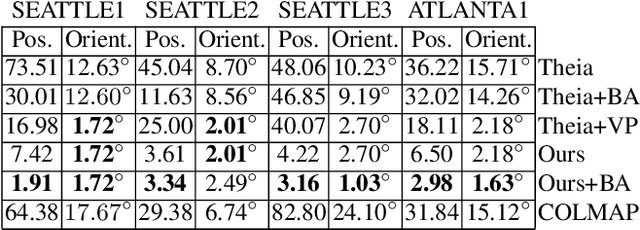


Low-frequency long-range errors (drift) are an endemic problem in 3D structure from motion, and can often hamper reasonable reconstructions of the scene. In this paper, we present a method to dramatically reduce scale and positional drift by using extended structural features such as planes and vanishing points. Unlike traditional feature matches, our extended features are able to span non-overlapping input images, and hence provide long-range constraints on the scale and shape of the reconstruction. We add these features as additional constraints to a state-of-the-art global structure from motion algorithm and demonstrate that the added constraints enable the reconstruction of particularly drift-prone sequences such as long, low field-of-view videos without inertial measurements. Additionally, we provide an analysis of the drift-reducing capabilities of these constraints by evaluating on a synthetic dataset. Our structural features are able to significantly reduce drift for scenes that contain long-spanning man-made structures, such as aligned rows of windows or planar building facades.