 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIN-NBV: A View Introspection Network for Next-Best-View Selection for Resource-Efficient 3D Reconstruction
May 09, 2025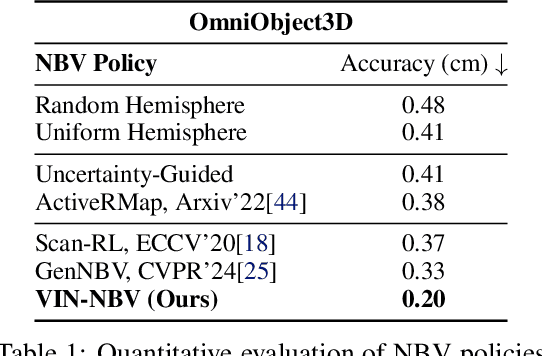
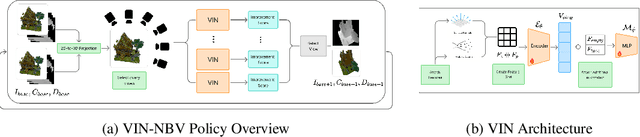
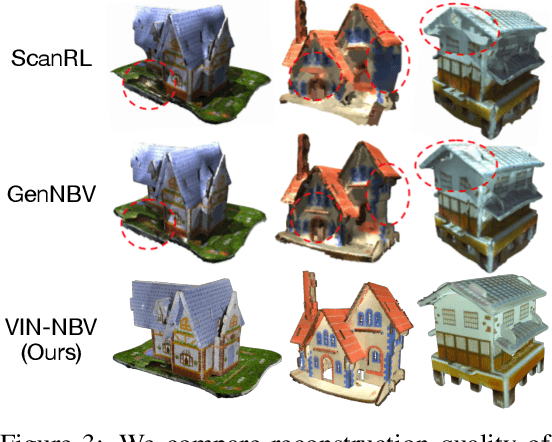
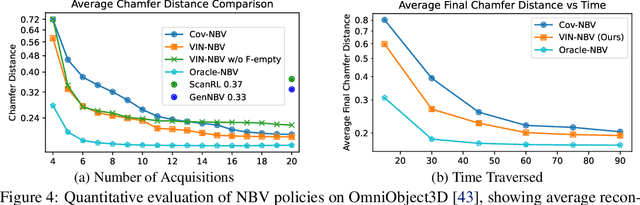
Next Best View (NBV) algorithms aim to acquire an optimal set of images using minimal resources, time, or number of captures to enable efficient 3D reconstruction of a scene. Existing approaches often rely on prior scene knowledge or additional image captures and often develop policies that maximize coverage. Yet, for many real scenes with complex geometry and self-occlusions, coverage maximization does not lead to better reconstruction quality directly. In this paper, we propose the View Introspection Network (VIN), which is trained to predict the reconstruction quality improvement of views directly, and the VIN-NBV policy. A greedy sequential sampling-based policy, where at each acquisition step, we sample multiple query views and choose the one with the highest VIN predicted improvement score. We design the VIN to perform 3D-aware featurization of the reconstruction built from prior acquisitions, and for each query view create a feature that can be decoded into an improvement score. We then train the VIN using imitation learning to predict the reconstruction improvement score. We show that VIN-NBV improves reconstruction quality by ~30% over a coverage maximization baseline when operating with constraints on the number of acquisitions or the time in motion.
MVPSNet: Fast Generalizable Multi-view Photometric Stereo
May 18, 2023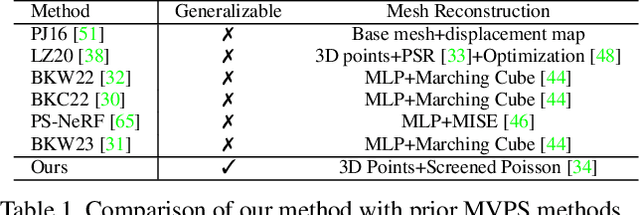
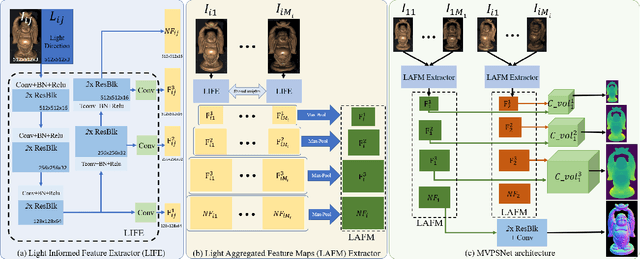

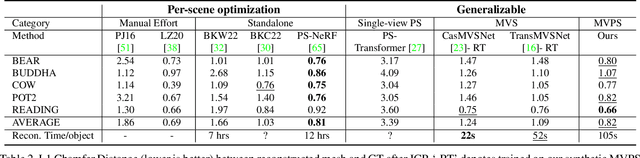
We propose a fast and generalizable solution to Multi-view Photometric Stereo (MVPS), called MVPSNet. The key to our approach is a feature extraction network that effectively combines images from the same view captured under multiple lighting conditions to extract geometric features from shading cues for stereo matching. We demonstrate these features, termed `Light Aggregated Feature Maps' (LAFM), are effective for feature matching even in textureless regions, where traditional multi-view stereo methods fail. Our method produces similar reconstruction results to PS-NeRF, a state-of-the-art MVPS method that optimizes a neural network per-scene, while being 411$\times$ faster (105 seconds vs. 12 hours) in inference. Additionally, we introduce a new synthetic dataset for MVPS, sMVPS, which is shown to be effective to train a generalizable MVPS method.
LossMix: Simplify and Generalize Mixup for Object Detection and Beyond
Mar 18, 2023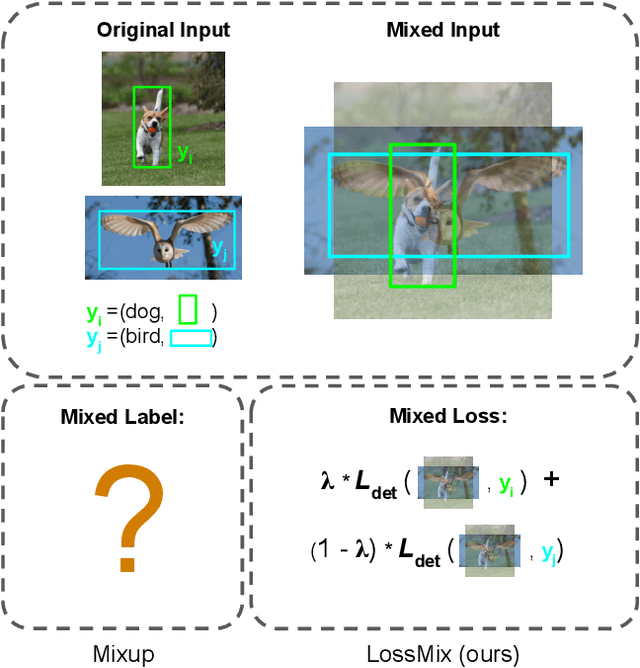
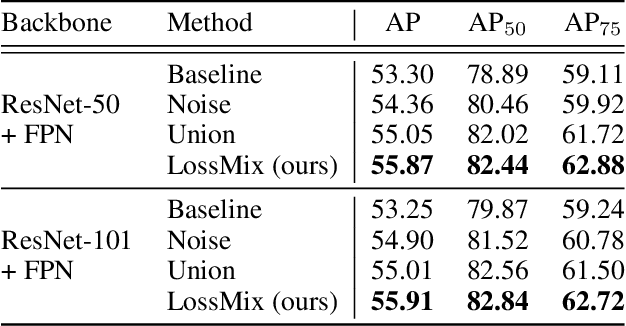
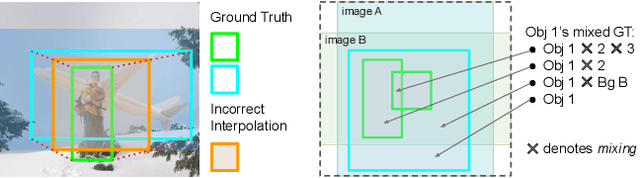
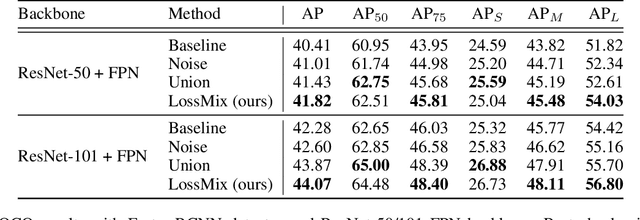
The success of data mixing augmentations in image classification tasks has been well-received. However, these techniques cannot be readily applied to object detection due to challenges such as spatial misalignment, foreground/background distinction, and plurality of instances. To tackle these issues, we first introduce a novel conceptual framework called Supervision Interpolation, which offers a fresh perspective on interpolation-based augmentations by relaxing and generalizing Mixup. Building on this framework, we propose LossMix, a simple yet versatile and effective regularization that enhances the performance and robustness of object detectors and more. Our key insight is that we can effectively regularize the training on mixed data by interpolating their loss errors instead of ground truth labels. Empirical results on the PASCAL VOC and MS COCO datasets demonstrate that LossMix consistently outperforms currently popular mixing strategies. Furthermore, we design a two-stage domain mixing method that leverages LossMix to surpass Adaptive Teacher (CVPR 2022) and set a new state of the art for unsupervised domain adaptation.
A Surface-normal Based Neural Framework for Colonoscopy Reconstruction
Mar 13, 2023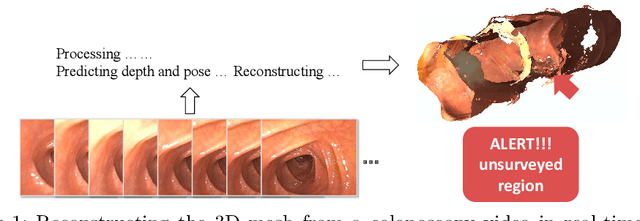
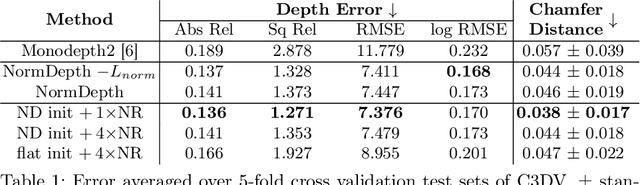
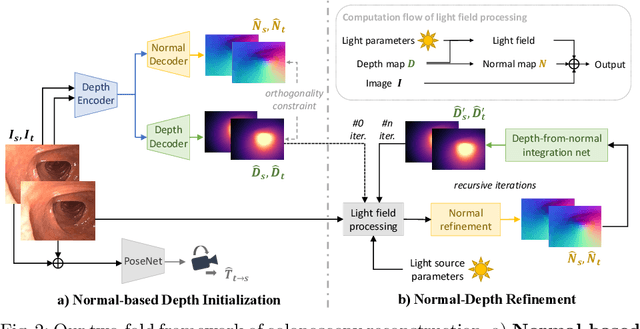
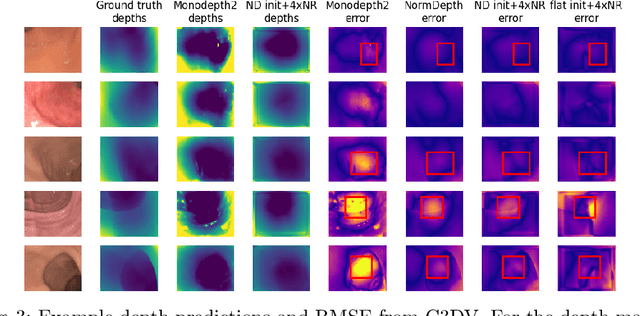
Reconstructing a 3D surface from colonoscopy video is challenging due to illumination and reflectivity variation in the video frame that can cause defective shape predictions. Aiming to overcome this challenge, we utilize the characteristics of surface normal vectors and develop a two-step neural framework that significantly improves the colonoscopy reconstruction quality. The normal-based depth initialization network trained with self-supervised normal consistency loss provides depth map initialization to the normal-depth refinement module, which utilizes the relationship between illumination and surface normals to refine the frame-wise normal and depth predictions recursively. Our framework's depth accuracy performance on phantom colonoscopy data demonstrates the value of exploiting the surface normals in colonoscopy reconstruction, especially on en face views. Due to its low depth error, the prediction result from our framework will require limited post-processing to be clinically applicable for real-time colonoscopy reconstruction.
A Practical Stereo Depth System for Smart Glasses
Nov 19, 2022



We present the design of a productionized end-to-end stereo depth sensing system that does pre-processing, online stereo rectification, and stereo depth estimation with a fallback to monocular depth estimation when rectification is unreliable. The output of our depth sensing system is then used in a novel view generation pipeline to create 3D computational photography effect using point-of-view images captured by smart glasses. All these steps are executed on-device on the stringent compute budget of a mobile phone, and because we expect the users can use a wide range of smartphones, our design needs to be general and cannot be dependent on a particular hardware or ML accelerator such as a smartphone GPU. Although each of these steps is well-studied, a description of a practical system is still lacking. For such a system, each of these steps need to work in tandem with one another and fallback gracefully on failures within the system or less than ideal input data. We show how we handle unforeseen changes to calibration, e.g. due to heat, robustly support depth estimation in the wild, and still abide by the memory and latency constraints required for a smooth user experience. We show that our trained models are fast, that run in less than 1s on a six-year-old Samsung Galaxy S8 phone's CPU. Our models generalize well to unseen data and achieve good results on Middlebury and in-the-wild images captured from the smart glasses.
Toward Edge-Efficient Dense Predictions with Synergistic Multi-Task Neural Architecture Search
Oct 04, 2022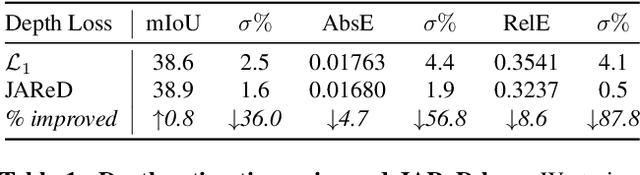

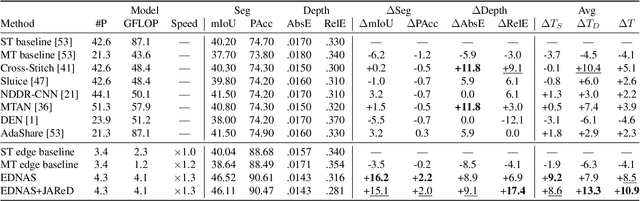
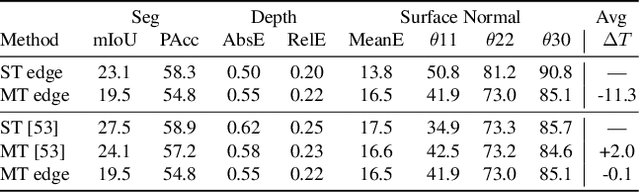
In this work, we propose a novel and scalable solution to address the challenges of developing efficient dense predictions on edge platforms. Our first key insight is that MultiTask Learning (MTL) and hardware-aware Neural Architecture Search (NAS) can work in synergy to greatly benefit on-device Dense Predictions (DP). Empirical results reveal that the joint learning of the two paradigms is surprisingly effective at improving DP accuracy, achieving superior performance over both the transfer learning of single-task NAS and prior state-of-the-art approaches in MTL, all with just 1/10th of the computation. To the best of our knowledge, our framework, named EDNAS, is the first to successfully leverage the synergistic relationship of NAS and MTL for DP. Our second key insight is that the standard depth training for multi-task DP can cause significant instability and noise to MTL evaluation. Instead, we propose JAReD, an improved, easy-to-adopt Joint Absolute-Relative Depth loss, that reduces up to 88% of the undesired noise while simultaneously boosting accuracy. We conduct extensive evaluations on standard datasets, benchmark against strong baselines and state-of-the-art approaches, as well as provide an analysis of the discovered optimal architectures.
Leveraging Disentangled Representations to Improve Vision-Based Keystroke Inference Attacks Under Low Data
Apr 05, 2022
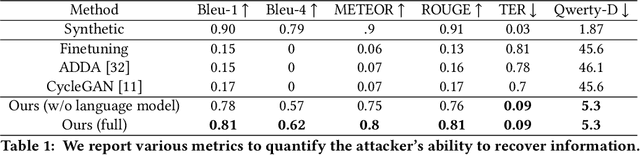
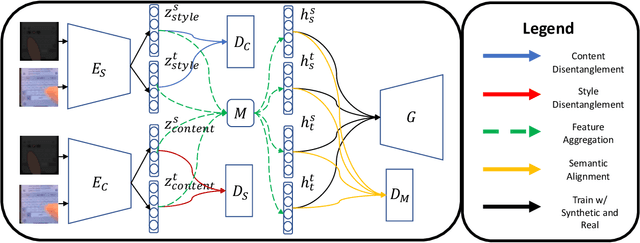
Keystroke inference attacks are a form of side-channel attacks in which an attacker leverages various techniques to recover a user's keystrokes as she inputs information into some display (e.g., while sending a text message or entering her pin). Typically, these attacks leverage machine learning approaches, but assessing the realism of the threat space has lagged behind the pace of machine learning advancements, due in-part, to the challenges in curating large real-life datasets. We aim to overcome the challenge of having limited number of real data by introducing a video domain adaptation technique that is able to leverage synthetic data through supervised disentangled learning. Specifically, for a given domain, we decompose the observed data into two factors of variation: Style and Content. Doing so provides four learned representations: real-life style, synthetic style, real-life content and synthetic content. Then, we combine them into feature representations from all combinations of style-content pairings across domains, and train a model on these combined representations to classify the content (i.e., labels) of a given datapoint in the style of another domain. We evaluate our method on real-life data using a variety of metrics to quantify the amount of information an attacker is able to recover. We show that our method prevents our model from overfitting to a small real-life training set, indicating that our method is an effective form of data augmentation, thereby making keystroke inference attacks more practical.
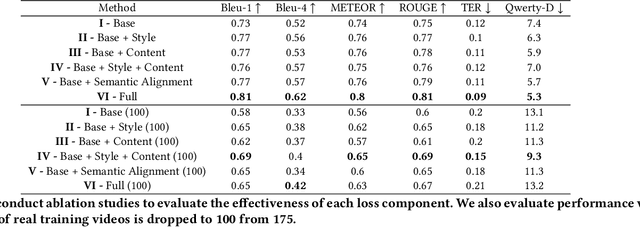
VPFusion: Joint 3D Volume and Pixel-Aligned Feature Fusion for Single and Multi-view 3D Reconstruction
Mar 14, 2022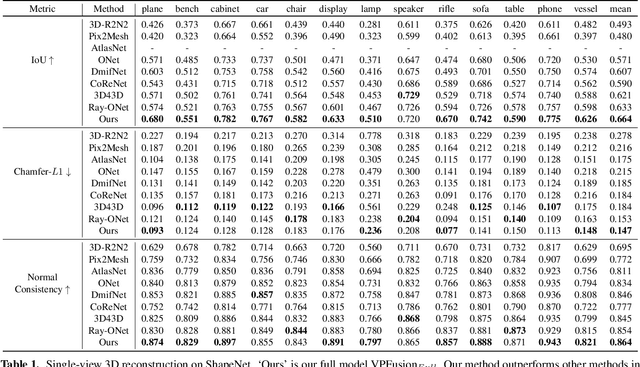
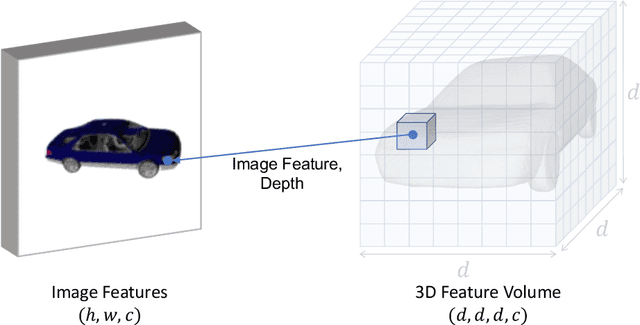
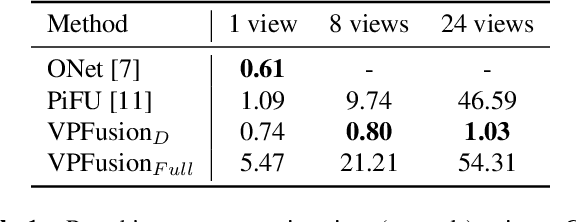

We introduce a unified single and multi-view neural implicit 3D reconstruction framework VPFusion. VPFusion~attains high-quality reconstruction using both - 3D feature volume to capture 3D-structure-aware context, and pixel-aligned image features to capture fine local detail. Existing approaches use RNN, feature pooling, or attention computed independently in each view for multi-view fusion. RNNs suffer from long-term memory loss and permutation variance, while feature pooling or independently computed attention leads to representation in each view being unaware of other views before the final pooling step. In contrast, we show improved multi-view feature fusion by establishing transformer-based pairwise view association. In particular, we propose a novel interleaved 3D reasoning and pairwise view association architecture for feature volume fusion across different views. Using this structure-aware and multi-view-aware feature volume, we show improved 3D reconstruction performance compared to existing methods. VPFusion improves the reconstruction quality further by also incorporating pixel-aligned local image features to capture fine detail. We verify the effectiveness of VPFusion~on the ShapeNet and ModelNet datasets, where we outperform or perform on-par the state-of-the-art single and multi-view 3D shape reconstruction methods.
ColDE: A Depth Estimation Framework for Colonoscopy Reconstruction
Nov 19, 2021
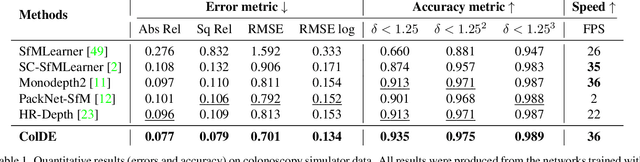
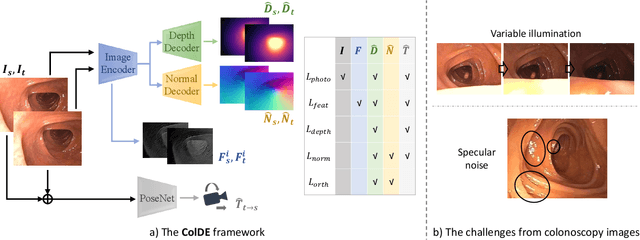
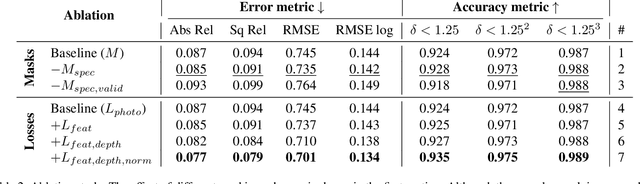
One of the key elements of reconstructing a 3D mesh from a monocular video is generating every frame's depth map. However, in the application of colonoscopy video reconstruction, producing good-quality depth estimation is challenging. Neural networks can be easily fooled by photometric distractions or fail to capture the complex shape of the colon surface, predicting defective shapes that result in broken meshes. Aiming to fundamentally improve the depth estimation quality for colonoscopy 3D reconstruction, in this work we have designed a set of training losses to deal with the special challenges of colonoscopy data. For better training, a set of geometric consistency objectives was developed, using both depth and surface normal information. Also, the classic photometric loss was extended with feature matching to compensate for illumination noise. With the training losses powerful enough, our self-supervised framework named ColDE is able to produce better depth maps of colonoscopy data as compared to the previous work utilizing prior depth knowledge. Used in reconstruction, our network is able to reconstruct good-quality colon meshes in real-time without any post-processing, making it the first to be clinically applicable.
Any-Width Networks
Dec 06, 2020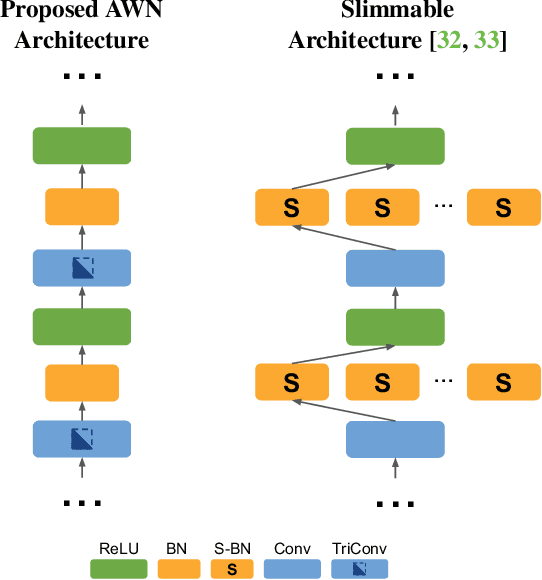

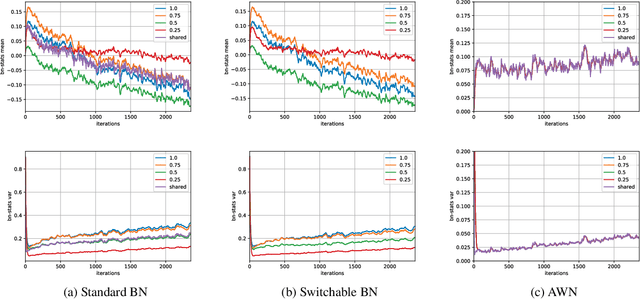

Despite remarkable improvements in speed and accuracy, convolutional neural networks (CNNs) still typically operate as monolithic entities at inference time. This poses a challenge for resource-constrained practical applications, where both computational budgets and performance needs can vary with the situation. To address these constraints, we propose the Any-Width Network (AWN), an adjustable-width CNN architecture and associated training routine that allow for fine-grained control over speed and accuracy during inference. Our key innovation is the use of lower-triangular weight matrices which explicitly address width-varying batch statistics while being naturally suited for multi-width operations. We also show that this design facilitates an efficient training routine based on random width sampling. We empirically demonstrate that our proposed AWNs compare favorably to existing methods while providing maximally granular control during inference.