 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Disentangled Representations to Improve Vision-Based Keystroke Inference Attacks Under Low Data
Apr 05, 2022
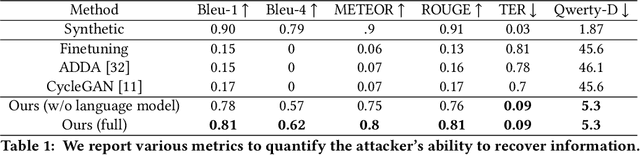
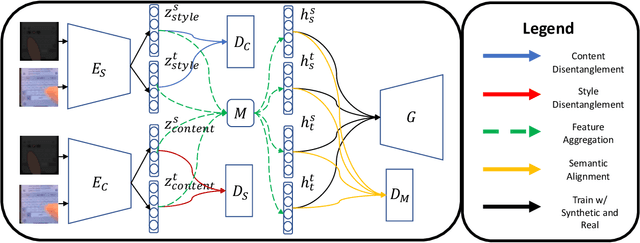
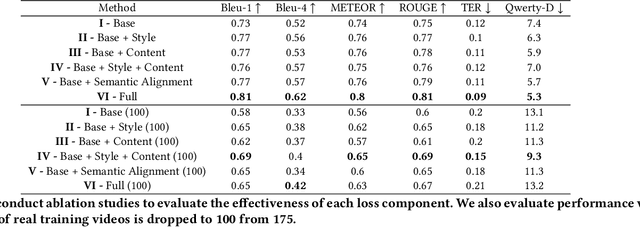
Keystroke inference attacks are a form of side-channel attacks in which an attacker leverages various techniques to recover a user's keystrokes as she inputs information into some display (e.g., while sending a text message or entering her pin). Typically, these attacks leverage machine learning approaches, but assessing the realism of the threat space has lagged behind the pace of machine learning advancements, due in-part, to the challenges in curating large real-life datasets. We aim to overcome the challenge of having limited number of real data by introducing a video domain adaptation technique that is able to leverage synthetic data through supervised disentangled learning. Specifically, for a given domain, we decompose the observed data into two factors of variation: Style and Content. Doing so provides four learned representations: real-life style, synthetic style, real-life content and synthetic content. Then, we combine them into feature representations from all combinations of style-content pairings across domains, and train a model on these combined representations to classify the content (i.e., labels) of a given datapoint in the style of another domain. We evaluate our method on real-life data using a variety of metrics to quantify the amount of information an attacker is able to recover. We show that our method prevents our model from overfitting to a small real-life training set, indicating that our method is an effective form of data augmentation, thereby making keystroke inference attacks more practical.
Revisiting the Threat Space for Vision-based Keystroke Inference Attacks
Sep 12, 2020

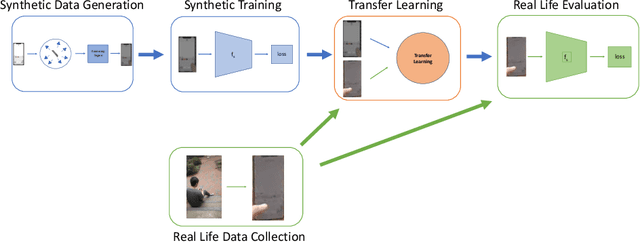

A vision-based keystroke inference attack is a side-channel attack in which an attacker uses an optical device to record users on their mobile devices and infer their keystrokes. The threat space for these attacks has been studied in the past, but we argue that the defining characteristics for this threat space, namely the strength of the attacker, are outdated. Previous works do not study adversaries with vision systems that have been trained with deep neural networks because these models require large amounts of training data and curating such a dataset is expensive. To address this, we create a large-scale synthetic dataset to simulate the attack scenario for a keystroke inference attack. We show that first pre-training on synthetic data, followed by adopting transfer learning techniques on real-life data, increases the performance of our deep learning models. This indicates that these models are able to learn rich, meaningful representations from our synthetic data and that training on the synthetic data can help overcome the issue of having small, real-life datasets for vision-based key stroke inference attacks. For this work, we focus on single keypress classification where the input is a frame of a keypress and the output is a predicted key. We are able to get an accuracy of 95.6% after pre-training a CNN on our synthetic data and training on a small set of real-life data in an adversarial domain adaptation framework. Source Code for Simulator: https://github.com/jlim13/keystroke-inference-attack-synthetic-dataset-generator-
Tangent Images for Mitigating Spherical Distortion
Dec 19, 2019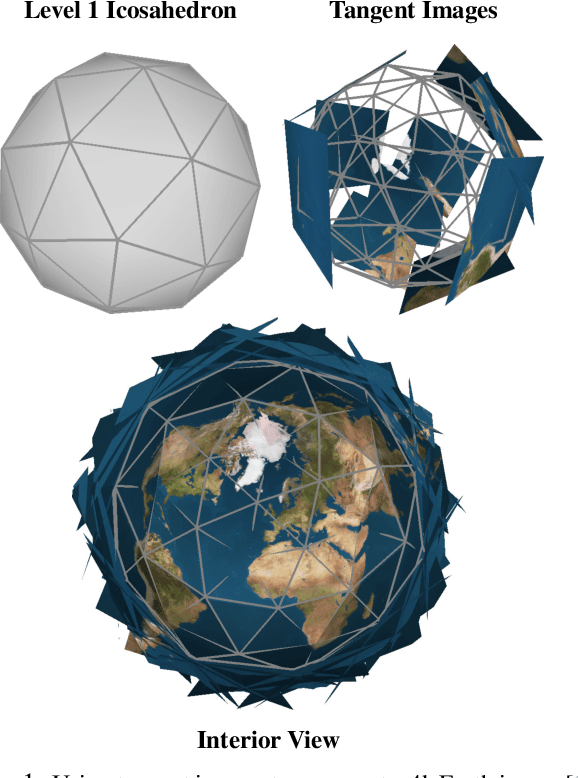
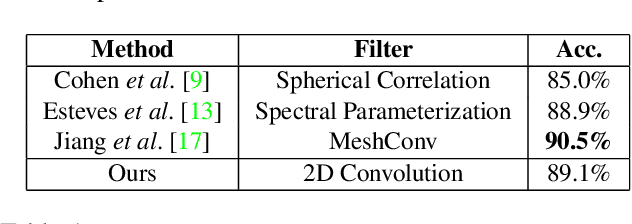

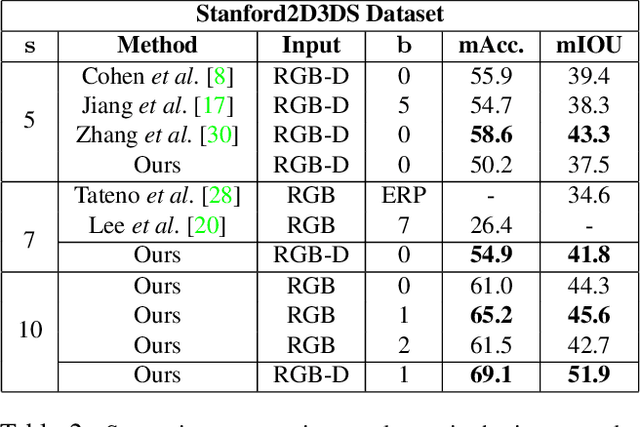
In this work, we propose "tangent images," a spherical image representation that facilitates transferable and scalable $360^\circ$ computer vision. Inspired by techniques in cartography and computer graphics, we render a spherical image to a set of distortion-mitigated, locally-planar image grids tangent to a subdivided icosahedron. By varying the resolution of these grids independently of the subdivision level, we can effectively represent high resolution spherical images while still benefiting from the low-distortion icosahedral spherical approximation. We show that training standard convolutional neural networks on tangent images compares favorably to the many specialized spherical convolutional kernels that have been developed, while also allowing us to scale training to significantly higher spherical resolutions. Furthermore, because we do not require specialized kernels, we show that we can transfer networks trained on perspective images to spherical data without fine-tuning and with limited performance drop-off. Finally, we demonstrate that tangent images can be used to improve the quality of sparse feature detection on spherical images, illustrating its usefulness for traditional computer vision tasks like structure-from-motion and SLAM.