 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Depth Prediction and Semantic Segmentation with Multi-View SAM
Oct 31, 2023



Multi-task approaches to joint depth and segmentation prediction are well-studied for monocular images. Yet, predictions from a single-view are inherently limited, while multiple views are available in many robotics applications. On the other end of the spectrum, video-based and full 3D methods require numerous frames to perform reconstruction and segmentation. With this work we propose a Multi-View Stereo (MVS) technique for depth prediction that benefits from rich semantic features of the Segment Anything Model (SAM). This enhanced depth prediction, in turn, serves as a prompt to our Transformer-based semantic segmentation decoder. We report the mutual benefit that both tasks enjoy in our quantitative and qualitative studies on the ScanNet dataset. Our approach consistently outperforms single-task MVS and segmentation models, along with multi-task monocular methods.
Tangent Images for Mitigating Spherical Distortion
Dec 19, 2019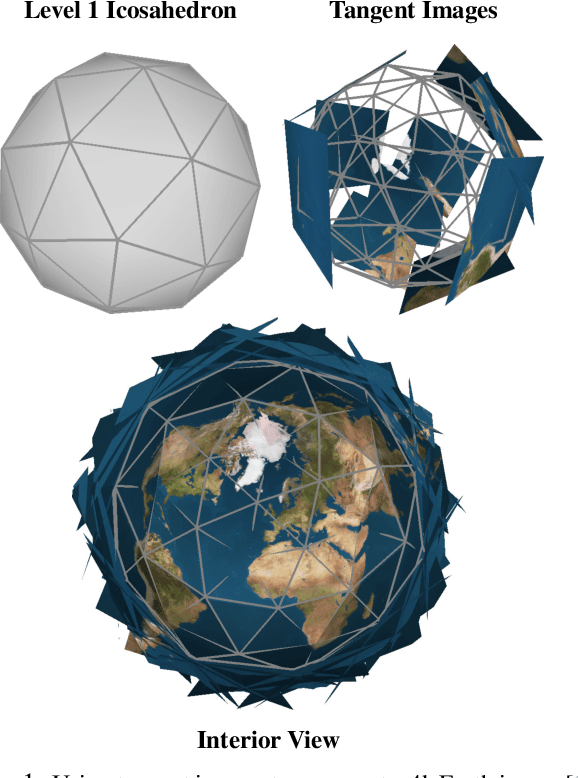
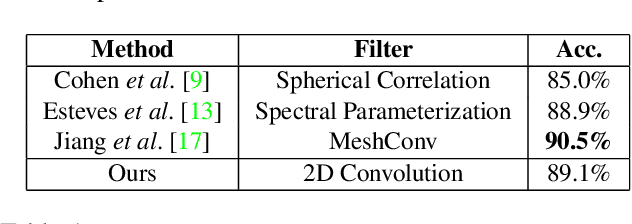

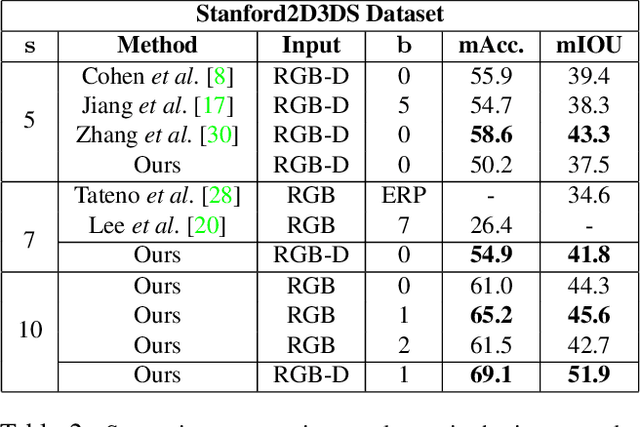
In this work, we propose "tangent images," a spherical image representation that facilitates transferable and scalable $360^\circ$ computer vision. Inspired by techniques in cartography and computer graphics, we render a spherical image to a set of distortion-mitigated, locally-planar image grids tangent to a subdivided icosahedron. By varying the resolution of these grids independently of the subdivision level, we can effectively represent high resolution spherical images while still benefiting from the low-distortion icosahedral spherical approximation. We show that training standard convolutional neural networks on tangent images compares favorably to the many specialized spherical convolutional kernels that have been developed, while also allowing us to scale training to significantly higher spherical resolutions. Furthermore, because we do not require specialized kernels, we show that we can transfer networks trained on perspective images to spherical data without fine-tuning and with limited performance drop-off. Finally, we demonstrate that tangent images can be used to improve the quality of sparse feature detection on spherical images, illustrating its usefulness for traditional computer vision tasks like structure-from-motion and SLAM.
MolecularRNN: Generating realistic molecular graphs with optimized properties
May 31, 2019
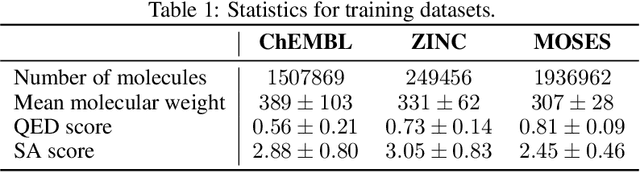


Designing new molecules with a set of predefined properties is a core problem in modern drug discovery and development. There is a growing need for de-novo design methods that would address this problem. We present MolecularRNN, the graph recurrent generative model for molecular structures. Our model generates diverse realistic molecular graphs after likelihood pretraining on a big database of molecules. We perform an analysis of our pretrained models on large-scale generated datasets of 1 million samples. Further, the model is tuned with policy gradient algorithm, provided a critic that estimates the reward for the property of interest. We show a significant distribution shift to the desired range for lipophilicity, drug-likeness, and melting point outperforming state-of-the-art works. With the use of rejection sampling based on valency constraints, our model yields 100% validity. Moreover, we show that invalid molecules provide a rich signal to the model through the use of structure penalty in our reinforcement learning pipeline.
RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free
Jan 10, 2019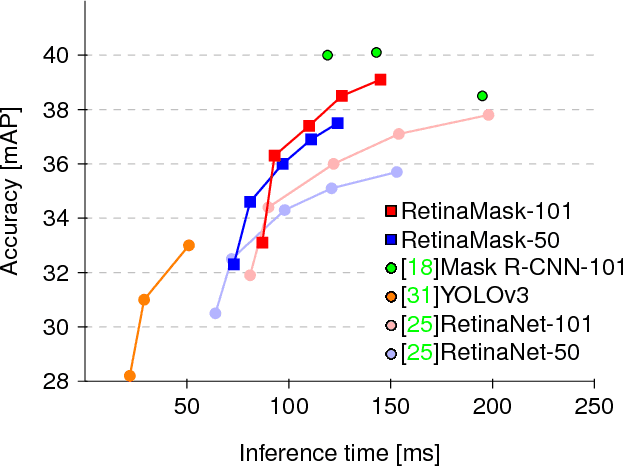
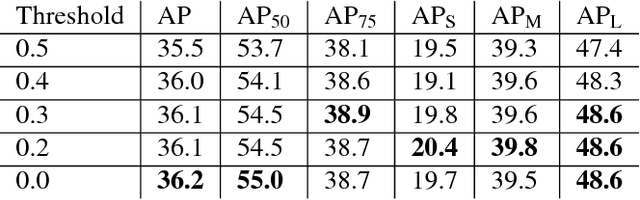
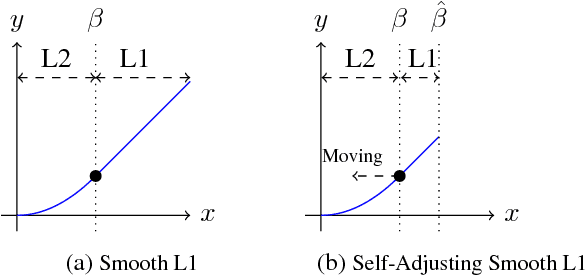
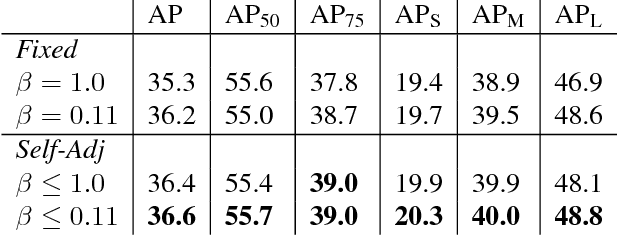
Recently two-stage detectors have surged ahead of single-shot detectors in the accuracy-vs-speed trade-off. Nevertheless single-shot detectors are immensely popular in embedded vision applications. This paper brings single-shot detectors up to the same level as current two-stage techniques. We do this by improving training for the state-of-the-art single-shot detector, RetinaNet, in three ways: integrating instance mask prediction for the first time, making the loss function adaptive and more stable, and including additional hard examples in training. We call the resulting augmented network RetinaMask. The detection component of RetinaMask has the same computational cost as the original RetinaNet, but is more accurate. COCO test-dev results are up to 41.4 mAP for RetinaMask-101 vs 39.1mAP for RetinaNet-101, while the runtime is the same during evaluation. Adding Group Normalization increases the performance of RetinaMask-101 to 41.7 mAP. Code is at:https://github.com/chengyangfu/retinamask
Target Driven Instance Detection
Jul 17, 2018
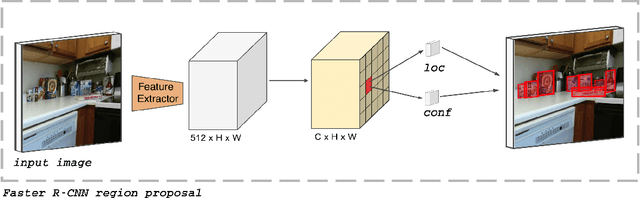
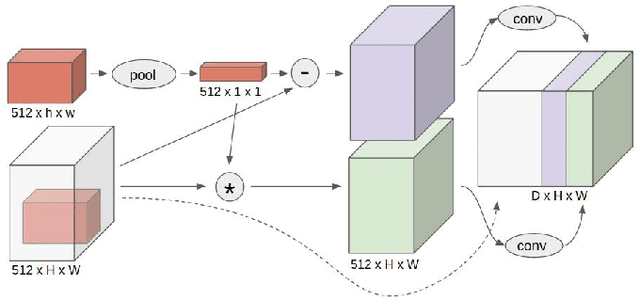

While state-of-the-art general object detectors are getting better and better, there are not many systems specifically designed to take advantage of the instance detection problem. For many applications, such as household robotics, a system may need to recognize a few very specific instances at a time. Speed can be critical in these applications, as can the need to recognize previously unseen instances. We introduce a Target Driven Instance Detector(TDID), which modifies existing general object detectors for the instance recognition setting. TDID not only improves performance on instances seen during training, with a fast runtime, but is also able to generalize to detect novel instances.