 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisheye3R: Adapting Unified 3D Feed-Forward Foundation Models to Fisheye Lenses
Mar 30, 2026Feed-forward foundation models for multi-view 3-dimensional (3D) reconstruction have been trained on large-scale datasets of perspective images; when tested on wide field-of-view images, e.g., from a fisheye camera, their performance degrades. Their error arises from changes in spatial positions of pixels due to a non-linear projection model that maps 3D points onto the 2D image plane. While one may surmise that training on fisheye images would resolve this problem, there are far fewer fisheye images with ground truth than perspective images, which limit generalization. To enable inference on imagery exhibiting high radial distortion, we propose Fisheye3R, a novel adaptation framework that extends these multi-view 3D reconstruction foundation models to natively accommodate fisheye inputs without performance regression on perspective images. To address the scarcity of fisheye images and ground truth, we introduce flexible learning schemes that support self-supervised adaptation using only unlabeled perspective images and supervised adaptation without any fisheye training data. Extensive experiments across three foundation models, including VGGT, $π^3$, and MapAnything, demonstrate that our approach consistently improves camera pose, depth, point map, and field-of-view estimation on fisheye images.
VIN-NBV: A View Introspection Network for Next-Best-View Selection for Resource-Efficient 3D Reconstruction
May 09, 2025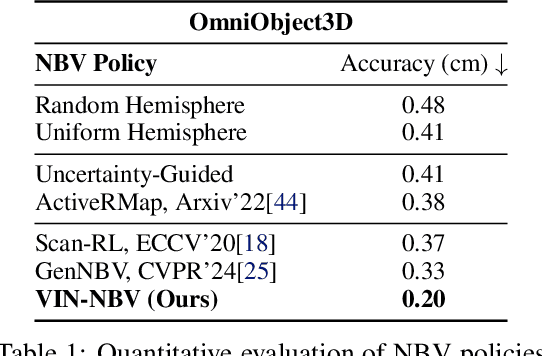
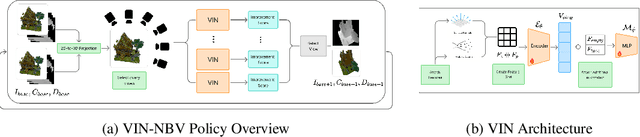
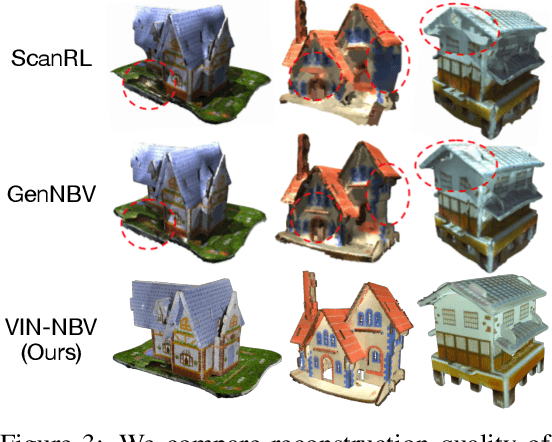
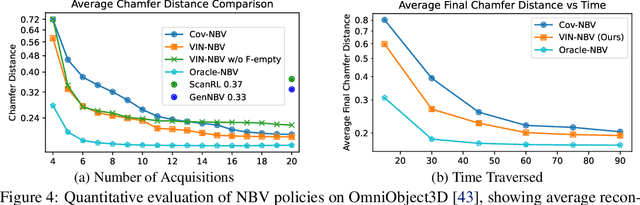
Next Best View (NBV) algorithms aim to acquire an optimal set of images using minimal resources, time, or number of captures to enable efficient 3D reconstruction of a scene. Existing approaches often rely on prior scene knowledge or additional image captures and often develop policies that maximize coverage. Yet, for many real scenes with complex geometry and self-occlusions, coverage maximization does not lead to better reconstruction quality directly. In this paper, we propose the View Introspection Network (VIN), which is trained to predict the reconstruction quality improvement of views directly, and the VIN-NBV policy. A greedy sequential sampling-based policy, where at each acquisition step, we sample multiple query views and choose the one with the highest VIN predicted improvement score. We design the VIN to perform 3D-aware featurization of the reconstruction built from prior acquisitions, and for each query view create a feature that can be decoded into an improvement score. We then train the VIN using imitation learning to predict the reconstruction improvement score. We show that VIN-NBV improves reconstruction quality by ~30% over a coverage maximization baseline when operating with constraints on the number of acquisitions or the time in motion.
Joint Depth Prediction and Semantic Segmentation with Multi-View SAM
Oct 31, 2023



Multi-task approaches to joint depth and segmentation prediction are well-studied for monocular images. Yet, predictions from a single-view are inherently limited, while multiple views are available in many robotics applications. On the other end of the spectrum, video-based and full 3D methods require numerous frames to perform reconstruction and segmentation. With this work we propose a Multi-View Stereo (MVS) technique for depth prediction that benefits from rich semantic features of the Segment Anything Model (SAM). This enhanced depth prediction, in turn, serves as a prompt to our Transformer-based semantic segmentation decoder. We report the mutual benefit that both tasks enjoy in our quantitative and qualitative studies on the ScanNet dataset. Our approach consistently outperforms single-task MVS and segmentation models, along with multi-task monocular methods.
MVPSNet: Fast Generalizable Multi-view Photometric Stereo
May 18, 2023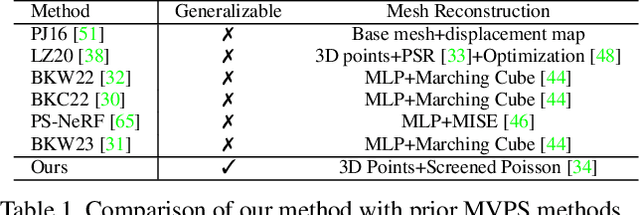
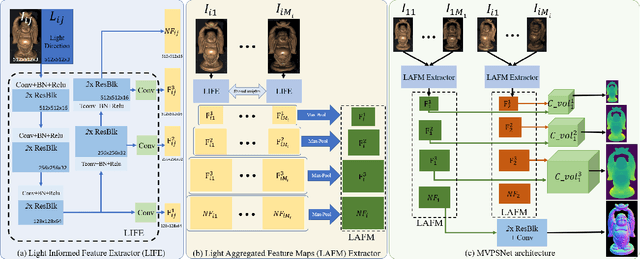

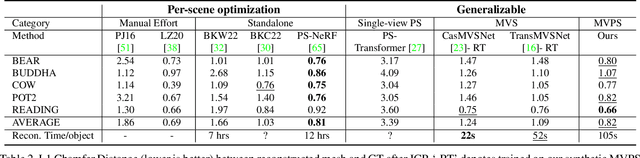
We propose a fast and generalizable solution to Multi-view Photometric Stereo (MVPS), called MVPSNet. The key to our approach is a feature extraction network that effectively combines images from the same view captured under multiple lighting conditions to extract geometric features from shading cues for stereo matching. We demonstrate these features, termed `Light Aggregated Feature Maps' (LAFM), are effective for feature matching even in textureless regions, where traditional multi-view stereo methods fail. Our method produces similar reconstruction results to PS-NeRF, a state-of-the-art MVPS method that optimizes a neural network per-scene, while being 411$\times$ faster (105 seconds vs. 12 hours) in inference. Additionally, we introduce a new synthetic dataset for MVPS, sMVPS, which is shown to be effective to train a generalizable MVPS method.