 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenvTorchCam: An Open-source Library for Camera-Agnostic Differentiable Geometric Vision
Oct 15, 2024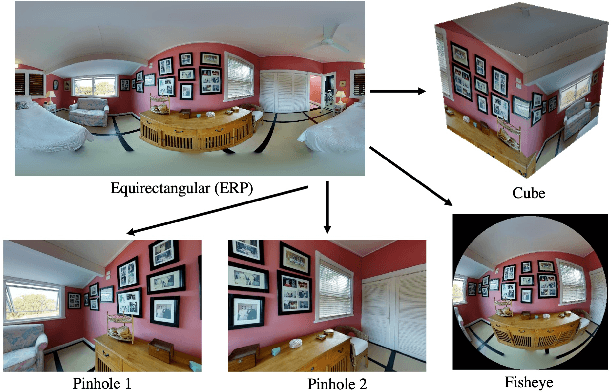



We introduce nvTorchCam, an open-source library under the Apache 2.0 license, designed to make deep learning algorithms camera model-independent. nvTorchCam abstracts critical camera operations such as projection and unprojection, allowing developers to implement algorithms once and apply them across diverse camera models--including pinhole, fisheye, and 360 equirectangular panoramas, which are commonly used in automotive and real estate capture applications. Built on PyTorch, nvTorchCam is fully differentiable and supports GPU acceleration and batching for efficient computation. Furthermore, deep learning models trained for one camera type can be directly transferred to other camera types without requiring additional modification. In this paper, we provide an overview of nvTorchCam, its functionality, and present various code examples and diagrams to demonstrate its usage. Source code and installation instructions can be found on the nvTorchCam GitHub page at https://github.com/NVlabs/nvTorchCam.
FoVA-Depth: Field-of-View Agnostic Depth Estimation for Cross-Dataset Generalization
Jan 24, 2024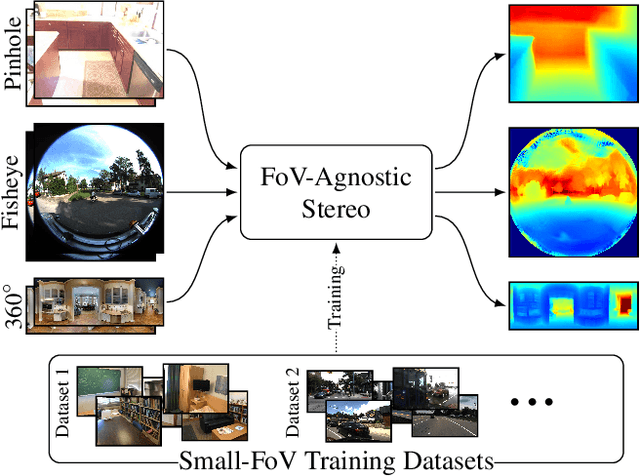

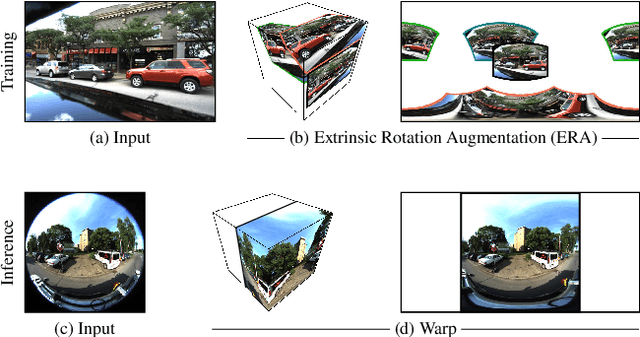
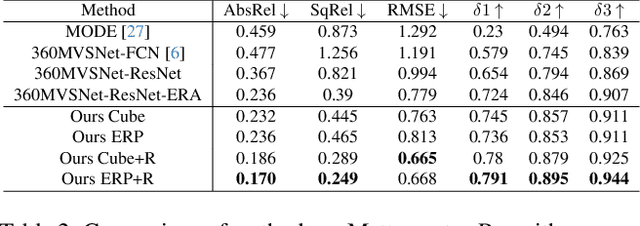
Wide field-of-view (FoV) cameras efficiently capture large portions of the scene, which makes them attractive in multiple domains, such as automotive and robotics. For such applications, estimating depth from multiple images is a critical task, and therefore, a large amount of ground truth (GT) data is available. Unfortunately, most of the GT data is for pinhole cameras, making it impossible to properly train depth estimation models for large-FoV cameras. We propose the first method to train a stereo depth estimation model on the widely available pinhole data, and to generalize it to data captured with larger FoVs. Our intuition is simple: We warp the training data to a canonical, large-FoV representation and augment it to allow a single network to reason about diverse types of distortions that otherwise would prevent generalization. We show strong generalization ability of our approach on both indoor and outdoor datasets, which was not possible with previous methods.
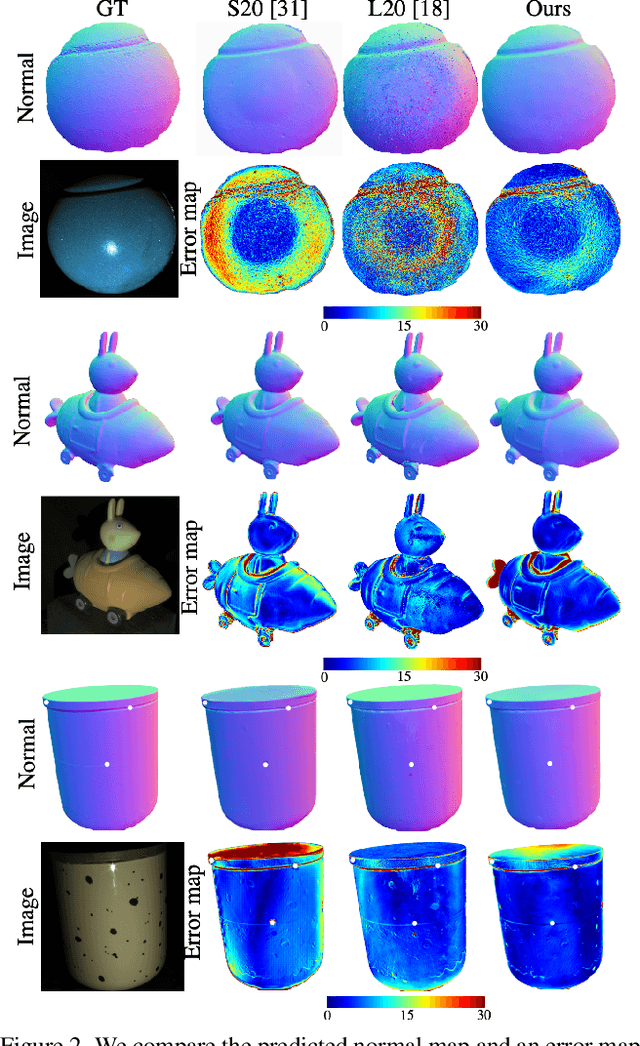
MVPSNet: Fast Generalizable Multi-view Photometric Stereo
May 18, 2023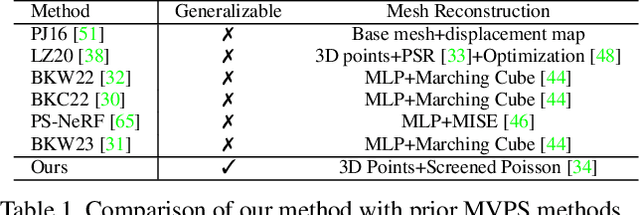
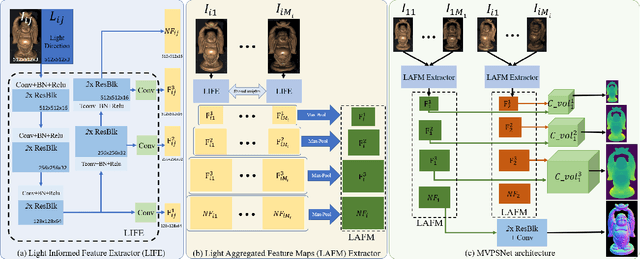

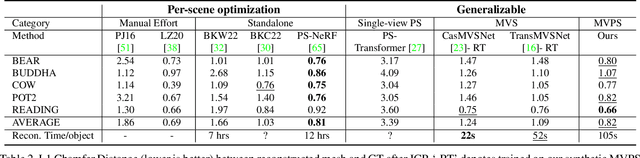
We propose a fast and generalizable solution to Multi-view Photometric Stereo (MVPS), called MVPSNet. The key to our approach is a feature extraction network that effectively combines images from the same view captured under multiple lighting conditions to extract geometric features from shading cues for stereo matching. We demonstrate these features, termed `Light Aggregated Feature Maps' (LAFM), are effective for feature matching even in textureless regions, where traditional multi-view stereo methods fail. Our method produces similar reconstruction results to PS-NeRF, a state-of-the-art MVPS method that optimizes a neural network per-scene, while being 411$\times$ faster (105 seconds vs. 12 hours) in inference. Additionally, we introduce a new synthetic dataset for MVPS, sMVPS, which is shown to be effective to train a generalizable MVPS method.
Fast Light-Weight Near-Field Photometric Stereo
Mar 30, 2022
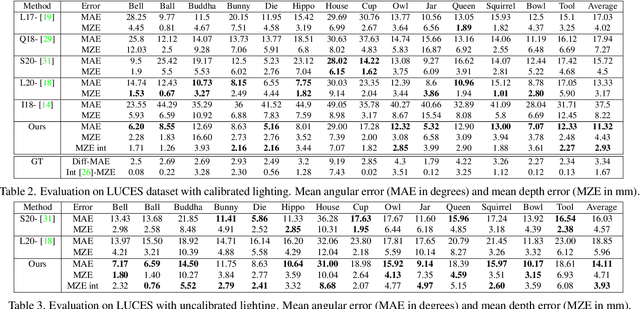
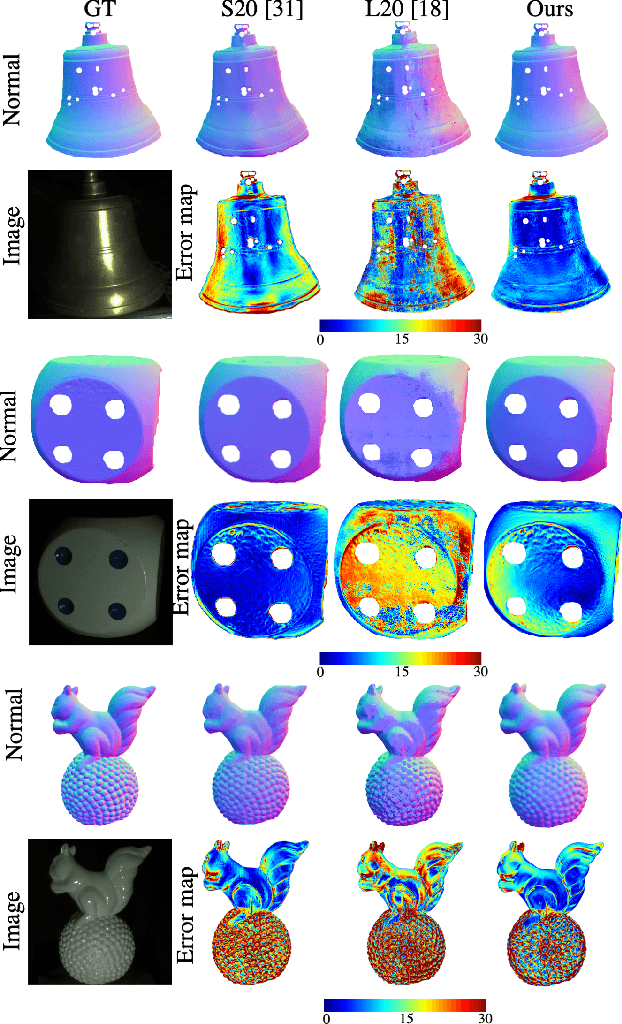
We introduce the first end-to-end learning-based solution to near-field Photometric Stereo (PS), where the light sources are close to the object of interest. This setup is especially useful for reconstructing large immobile objects. Our method is fast, producing a mesh from 52 512$\times$384 resolution images in about 1 second on a commodity GPU, thus potentially unlocking several AR/VR applications. Existing approaches rely on optimization coupled with a far-field PS network operating on pixels or small patches. Using optimization makes these approaches slow and memory intensive (requiring 17GB GPU and 27GB of CPU memory) while using only pixels or patches makes them highly susceptible to noise and calibration errors. To address these issues, we develop a recursive multi-resolution scheme to estimate surface normal and depth maps of the whole image at each step. The predicted depth map at each scale is then used to estimate `per-pixel lighting' for the next scale. This design makes our approach almost 45$\times$ faster and 2$^{\circ}$ more accurate (11.3$^{\circ}$ vs. 13.3$^{\circ}$ Mean Angular Error) than the state-of-the-art near-field PS reconstruction technique, which uses iterative optimization.
Shape and Material Capture at Home
Apr 13, 2021

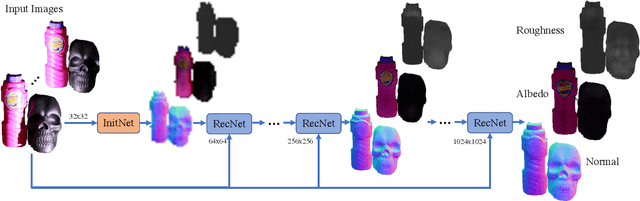

In this paper, we present a technique for estimating the geometry and reflectance of objects using only a camera, flashlight, and optionally a tripod. We propose a simple data capture technique in which the user goes around the object, illuminating it with a flashlight and capturing only a few images. Our main technical contribution is the introduction of a recursive neural architecture, which can predict geometry and reflectance at 2^{k}*2^{k} resolution given an input image at 2^{k}*2^{k} and estimated geometry and reflectance from the previous step at 2^{k-1}*2^{k-1}. This recursive architecture, termed RecNet, is trained with 256x256 resolution but can easily operate on 1024x1024 images during inference. We show that our method produces more accurate surface normal and albedo, especially in regions of specular highlights and cast shadows, compared to previous approaches, given three or fewer input images. For the video and code, please visit the project website http://dlichy.github.io/ShapeAndMaterialAtHome/.