 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Aging Multiverse: Generating Condition-Aware Facial Aging Tree via Training-Free Diffusion
Jun 26, 2025We introduce the Aging Multiverse, a framework for generating multiple plausible facial aging trajectories from a single image, each conditioned on external factors such as environment, health, and lifestyle. Unlike prior methods that model aging as a single deterministic path, our approach creates an aging tree that visualizes diverse futures. To enable this, we propose a training-free diffusion-based method that balances identity preservation, age accuracy, and condition control. Our key contributions include attention mixing to modulate editing strength and a Simulated Aging Regularization strategy to stabilize edits. Extensive experiments and user studies demonstrate state-of-the-art performance across identity preservation, aging realism, and conditional alignment, outperforming existing editing and age-progression models, which often fail to account for one or more of the editing criteria. By transforming aging into a multi-dimensional, controllable, and interpretable process, our approach opens up new creative and practical avenues in digital storytelling, health education, and personalized visualization.
MyTimeMachine: Personalized Facial Age Transformation
Nov 21, 2024Facial aging is a complex process, highly dependent on multiple factors like gender, ethnicity, lifestyle, etc., making it extremely challenging to learn a global aging prior to predict aging for any individual accurately. Existing techniques often produce realistic and plausible aging results, but the re-aged images often do not resemble the person's appearance at the target age and thus need personalization. In many practical applications of virtual aging, e.g. VFX in movies and TV shows, access to a personal photo collection of the user depicting aging in a small time interval (20$\sim$40 years) is often available. However, naive attempts to personalize global aging techniques on personal photo collections often fail. Thus, we propose MyTimeMachine (MyTM), which combines a global aging prior with a personal photo collection (using as few as 50 images) to learn a personalized age transformation. We introduce a novel Adapter Network that combines personalized aging features with global aging features and generates a re-aged image with StyleGAN2. We also introduce three loss functions to personalize the Adapter Network with personalized aging loss, extrapolation regularization, and adaptive w-norm regularization. Our approach can also be extended to videos, achieving high-quality, identity-preserving, and temporally consistent aging effects that resemble actual appearances at target ages, demonstrating its superiority over state-of-the-art approaches.
Rethinking Score Distillation as a Bridge Between Image Distributions
Jun 13, 2024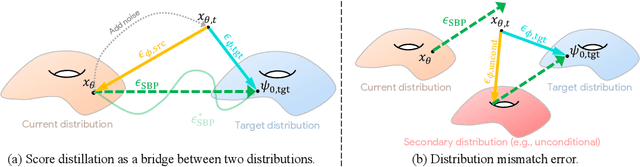

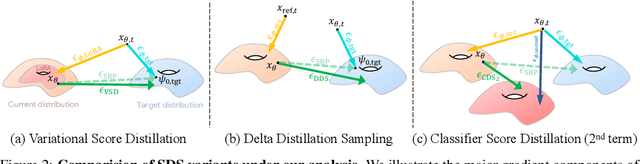
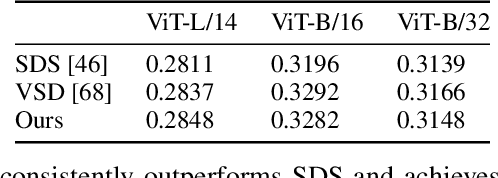
Score distillation sampling (SDS) has proven to be an important tool, enabling the use of large-scale diffusion priors for tasks operating in data-poor domains. Unfortunately, SDS has a number of characteristic artifacts that limit its usefulness in general-purpose applications. In this paper, we make progress toward understanding the behavior of SDS and its variants by viewing them as solving an optimal-cost transport path from a source distribution to a target distribution. Under this new interpretation, these methods seek to transport corrupted images (source) to the natural image distribution (target). We argue that current methods' characteristic artifacts are caused by (1) linear approximation of the optimal path and (2) poor estimates of the source distribution. We show that calibrating the text conditioning of the source distribution can produce high-quality generation and translation results with little extra overhead. Our method can be easily applied across many domains, matching or beating the performance of specialized methods. We demonstrate its utility in text-to-2D, text-based NeRF optimization, translating paintings to real images, optical illusion generation, and 3D sketch-to-real. We compare our method to existing approaches for score distillation sampling and show that it can produce high-frequency details with realistic colors.
Autoregressive Perturbations for Data Poisoning
Jun 15, 2022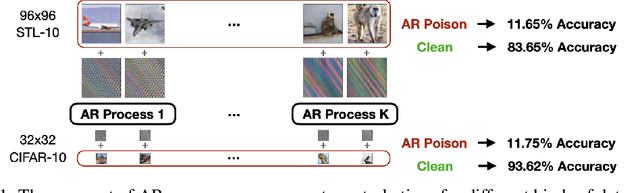
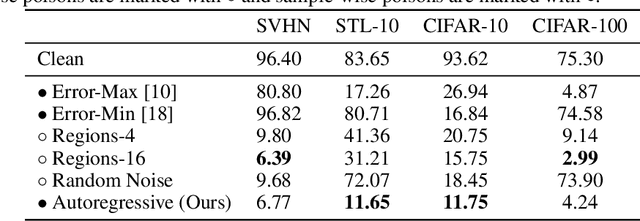
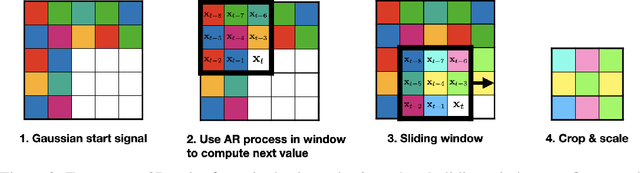
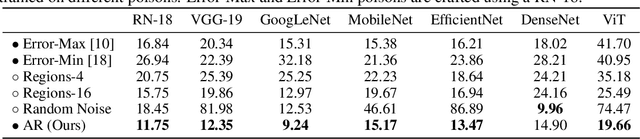
The prevalence of data scraping from social media as a means to obtain datasets has led to growing concerns regarding unauthorized use of data. Data poisoning attacks have been proposed as a bulwark against scraping, as they make data "unlearnable" by adding small, imperceptible perturbations. Unfortunately, existing methods require knowledge of both the target architecture and the complete dataset so that a surrogate network can be trained, the parameters of which are used to generate the attack. In this work, we introduce autoregressive (AR) poisoning, a method that can generate poisoned data without access to the broader dataset. The proposed AR perturbations are generic, can be applied across different datasets, and can poison different architectures. Compared to existing unlearnable methods, our AR poisons are more resistant against common defenses such as adversarial training and strong data augmentations. Our analysis further provides insight into what makes an effective data poison.
Fast Light-Weight Near-Field Photometric Stereo
Mar 30, 2022
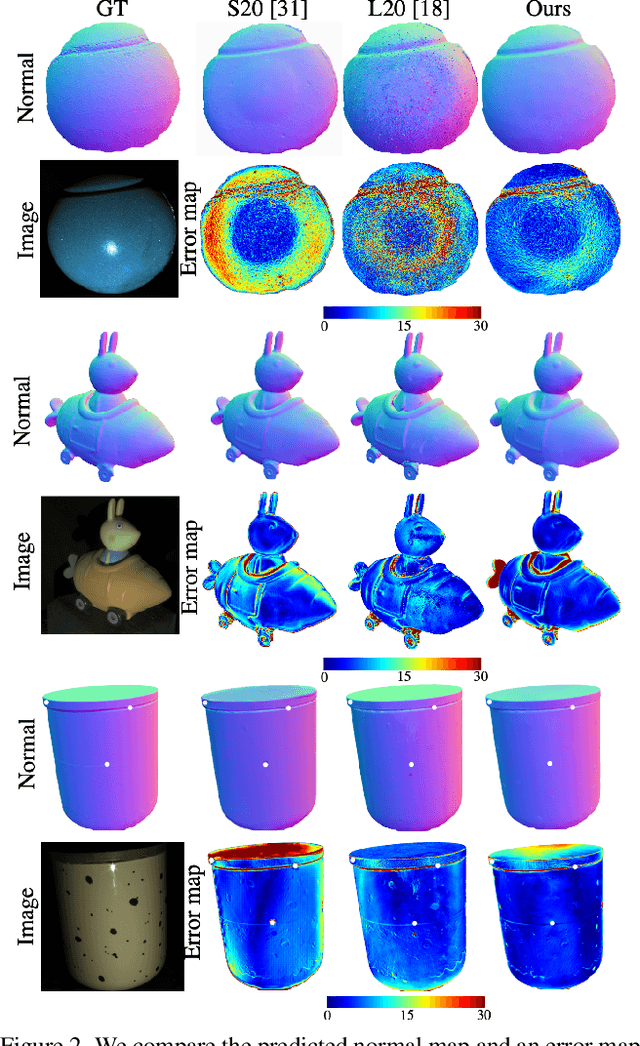
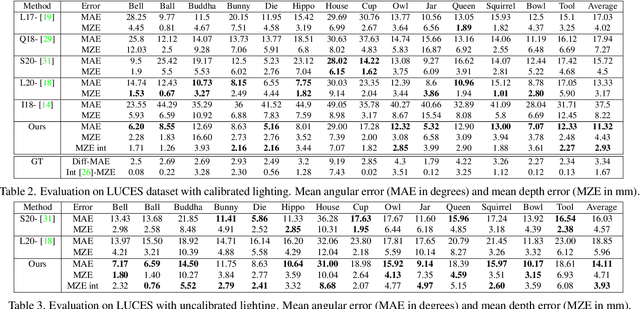
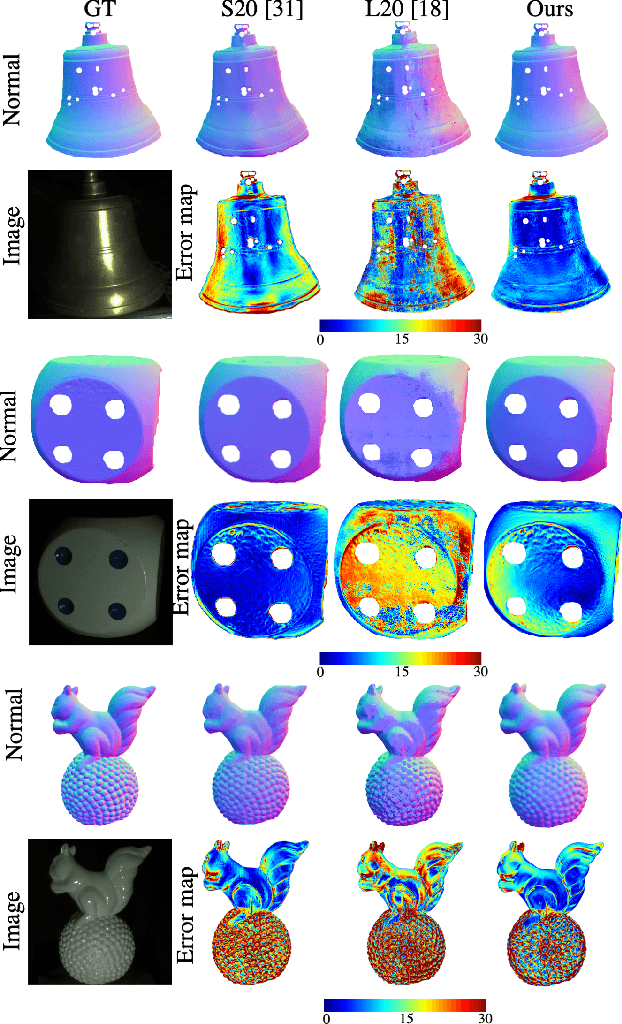
We introduce the first end-to-end learning-based solution to near-field Photometric Stereo (PS), where the light sources are close to the object of interest. This setup is especially useful for reconstructing large immobile objects. Our method is fast, producing a mesh from 52 512$\times$384 resolution images in about 1 second on a commodity GPU, thus potentially unlocking several AR/VR applications. Existing approaches rely on optimization coupled with a far-field PS network operating on pixels or small patches. Using optimization makes these approaches slow and memory intensive (requiring 17GB GPU and 27GB of CPU memory) while using only pixels or patches makes them highly susceptible to noise and calibration errors. To address these issues, we develop a recursive multi-resolution scheme to estimate surface normal and depth maps of the whole image at each step. The predicted depth map at each scale is then used to estimate `per-pixel lighting' for the next scale. This design makes our approach almost 45$\times$ faster and 2$^{\circ}$ more accurate (11.3$^{\circ}$ vs. 13.3$^{\circ}$ Mean Angular Error) than the state-of-the-art near-field PS reconstruction technique, which uses iterative optimization.
Shape and Material Capture at Home
Apr 13, 2021

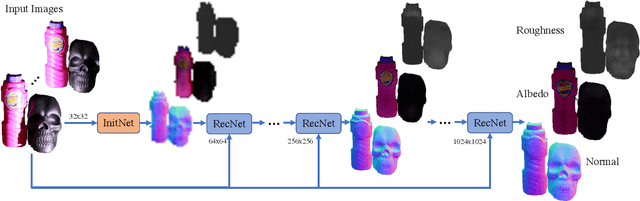

In this paper, we present a technique for estimating the geometry and reflectance of objects using only a camera, flashlight, and optionally a tripod. We propose a simple data capture technique in which the user goes around the object, illuminating it with a flashlight and capturing only a few images. Our main technical contribution is the introduction of a recursive neural architecture, which can predict geometry and reflectance at 2^{k}*2^{k} resolution given an input image at 2^{k}*2^{k} and estimated geometry and reflectance from the previous step at 2^{k-1}*2^{k-1}. This recursive architecture, termed RecNet, is trained with 256x256 resolution but can easily operate on 1024x1024 images during inference. We show that our method produces more accurate surface normal and albedo, especially in regions of specular highlights and cast shadows, compared to previous approaches, given three or fewer input images. For the video and code, please visit the project website http://dlichy.github.io/ShapeAndMaterialAtHome/.
Neural Inverse Rendering of an Indoor Scene from a Single Image
Jan 08, 2019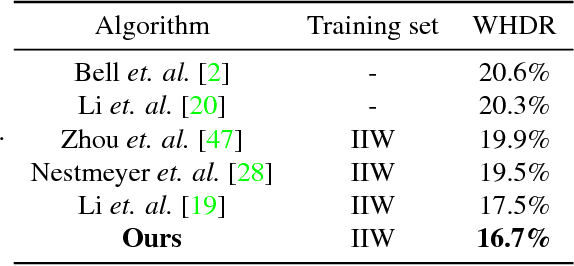
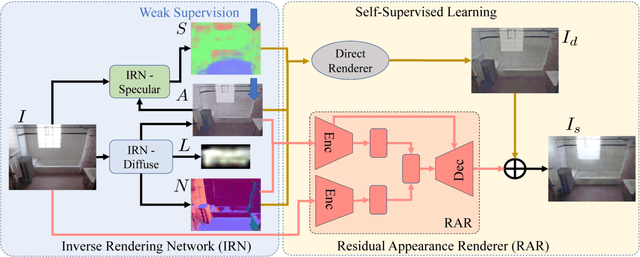


Inverse rendering aims to estimate physical scene attributes (e.g., reflectance, geometry, and lighting) from image(s). As a long-standing, highly ill-posed problem, inverse rendering has been studied primarily for single 3D objects or with methods that solve for only one of the scene attributes. To our knowledge, we are the first to propose a holistic approach for inverse rendering of an indoor scene from a single image with CNNs, which jointly estimates reflectance (albedo and gloss), surface normals and illumination. To address the lack of labeled real-world images, we create a large-scale synthetic dataset, named SUNCG-PBR, with physically-based rendering, which is a significant improvement over prior datasets. For fine-tuning on real images, we perform self-supervised learning using the reconstruction loss, which re-synthesizes the input images from the estimated components. To enable self-supervised learning on real data, our key contribution is the Residual Appearance Renderer (RAR), which can be trained to synthesize complex appearance effects (e.g., inter-reflection, cast shadows, near-field illumination, and realistic shading), which would be neglected otherwise. Experimental results show that our approach outperforms state-of-the-art methods, especially on real images.
End-to-end Recovery of Human Shape and Pose
Jun 23, 2018
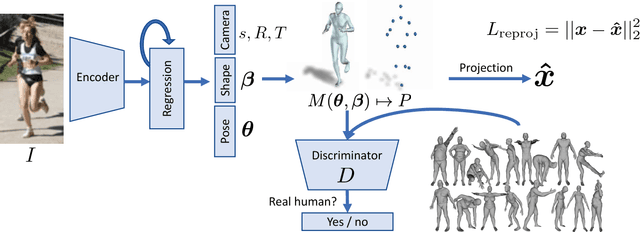

We describe Human Mesh Recovery (HMR), an end-to-end framework for reconstructing a full 3D mesh of a human body from a single RGB image. In contrast to most current methods that compute 2D or 3D joint locations, we produce a richer and more useful mesh representation that is parameterized by shape and 3D joint angles. The main objective is to minimize the reprojection loss of keypoints, which allow our model to be trained using images in-the-wild that only have ground truth 2D annotations. However, the reprojection loss alone leaves the model highly under constrained. In this work we address this problem by introducing an adversary trained to tell whether a human body parameter is real or not using a large database of 3D human meshes. We show that HMR can be trained with and without using any paired 2D-to-3D supervision. We do not rely on intermediate 2D keypoint detections and infer 3D pose and shape parameters directly from image pixels. Our model runs in real-time given a bounding box containing the person. We demonstrate our approach on various images in-the-wild and out-perform previous optimization based methods that output 3D meshes and show competitive results on tasks such as 3D joint location estimation and part segmentation.
Label Denoising Adversarial Network (LDAN) for Inverse Lighting of Face Images
Sep 06, 2017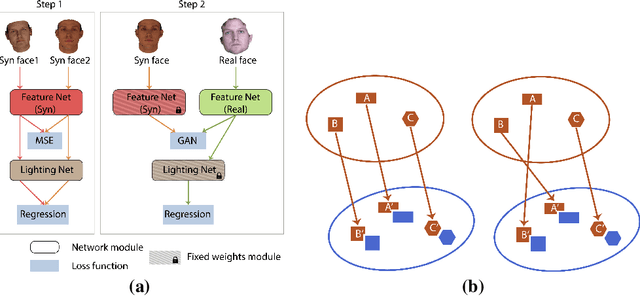

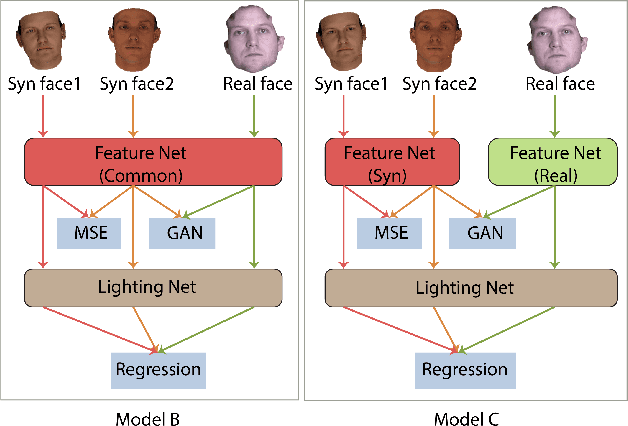

Lighting estimation from face images is an important task and has applications in many areas such as image editing, intrinsic image decomposition, and image forgery detection. We propose to train a deep Convolutional Neural Network (CNN) to regress lighting parameters from a single face image. Lacking massive ground truth lighting labels for face images in the wild, we use an existing method to estimate lighting parameters, which are treated as ground truth with unknown noises. To alleviate the effect of such noises, we utilize the idea of Generative Adversarial Networks (GAN) and propose a Label Denoising Adversarial Network (LDAN) to make use of synthetic data with accurate ground truth to help train a deep CNN for lighting regression on real face images. Experiments show that our network outperforms existing methods in producing consistent lighting parameters of different faces under similar lighting conditions. Moreover, our method is 100,000 times faster in execution time than prior optimization-based lighting estimation approaches.
Seeing What Is Not There: Learning Context to Determine Where Objects Are Missing
Feb 26, 2017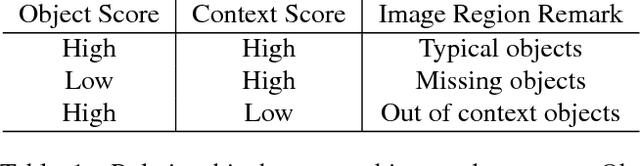
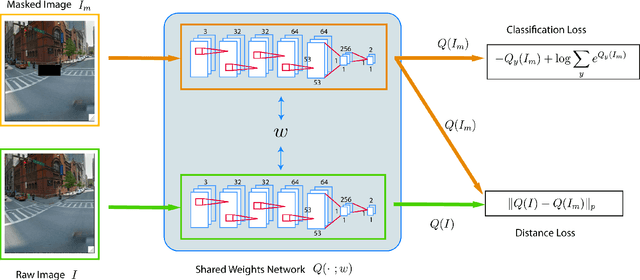

Most of computer vision focuses on what is in an image. We propose to train a standalone object-centric context representation to perform the opposite task: seeing what is not there. Given an image, our context model can predict where objects should exist, even when no object instances are present. Combined with object detection results, we can perform a novel vision task: finding where objects are missing in an image. Our model is based on a convolutional neural network structure. With a specially designed training strategy, the model learns to ignore objects and focus on context only. It is fully convolutional thus highly efficient. Experiments show the effectiveness of the proposed approach in one important accessibility task: finding city street regions where curb ramps are missing, which could help millions of people with mobility disabilities.