 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching Policy Gradients
Jul 28, 2025Flow-based generative models, including diffusion models, excel at modeling continuous distributions in high-dimensional spaces. In this work, we introduce Flow Policy Optimization (FPO), a simple on-policy reinforcement learning algorithm that brings flow matching into the policy gradient framework. FPO casts policy optimization as maximizing an advantage-weighted ratio computed from the conditional flow matching loss, in a manner compatible with the popular PPO-clip framework. It sidesteps the need for exact likelihood computation while preserving the generative capabilities of flow-based models. Unlike prior approaches for diffusion-based reinforcement learning that bind training to a specific sampling method, FPO is agnostic to the choice of diffusion or flow integration at both training and inference time. We show that FPO can train diffusion-style policies from scratch in a variety of continuous control tasks. We find that flow-based models can capture multimodal action distributions and achieve higher performance than Gaussian policies, particularly in under-conditioned settings.
A Comprehensive Study of Decoder-Only LLMs for Text-to-Image Generation
Jun 09, 2025Both text-to-image generation and large language models (LLMs) have made significant advancements. However, many text-to-image models still employ the somewhat outdated T5 and CLIP as their text encoders. In this work, we investigate the effectiveness of using modern decoder-only LLMs as text encoders for text-to-image diffusion models. We build a standardized training and evaluation pipeline that allows us to isolate and evaluate the effect of different text embeddings. We train a total of 27 text-to-image models with 12 different text encoders to analyze the critical aspects of LLMs that could impact text-to-image generation, including the approaches to extract embeddings, different LLMs variants, and model sizes. Our experiments reveal that the de facto way of using last-layer embeddings as conditioning leads to inferior performance. Instead, we explore embeddings from various layers and find that using layer-normalized averaging across all layers significantly improves alignment with complex prompts. Most LLMs with this conditioning outperform the baseline T5 model, showing enhanced performance in advanced visio-linguistic reasoning skills.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Illusion3D: 3D Multiview Illusion with 2D Diffusion Priors
Dec 12, 2024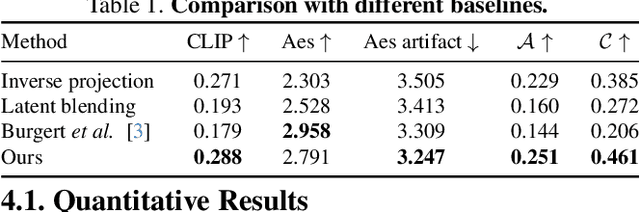


Automatically generating multiview illusions is a compelling challenge, where a single piece of visual content offers distinct interpretations from different viewing perspectives. Traditional methods, such as shadow art and wire art, create interesting 3D illusions but are limited to simple visual outputs (i.e., figure-ground or line drawing), restricting their artistic expressiveness and practical versatility. Recent diffusion-based illusion generation methods can generate more intricate designs but are confined to 2D images. In this work, we present a simple yet effective approach for creating 3D multiview illusions based on user-provided text prompts or images. Our method leverages a pre-trained text-to-image diffusion model to optimize the textures and geometry of neural 3D representations through differentiable rendering. When viewed from multiple angles, this produces different interpretations. We develop several techniques to improve the quality of the generated 3D multiview illusions. We demonstrate the effectiveness of our approach through extensive experiments and showcase illusion generation with diverse 3D forms.
Rethinking Score Distillation as a Bridge Between Image Distributions
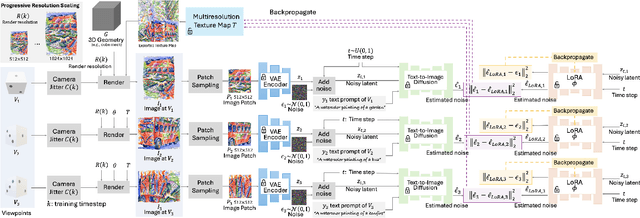
Jun 13, 2024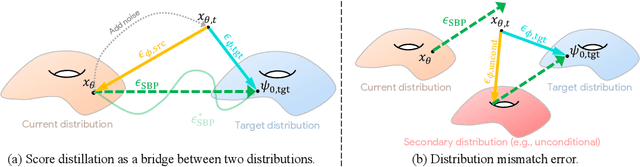

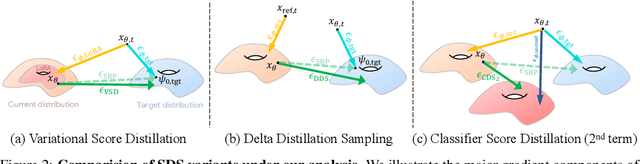
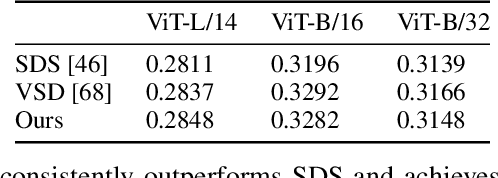
Score distillation sampling (SDS) has proven to be an important tool, enabling the use of large-scale diffusion priors for tasks operating in data-poor domains. Unfortunately, SDS has a number of characteristic artifacts that limit its usefulness in general-purpose applications. In this paper, we make progress toward understanding the behavior of SDS and its variants by viewing them as solving an optimal-cost transport path from a source distribution to a target distribution. Under this new interpretation, these methods seek to transport corrupted images (source) to the natural image distribution (target). We argue that current methods' characteristic artifacts are caused by (1) linear approximation of the optimal path and (2) poor estimates of the source distribution. We show that calibrating the text conditioning of the source distribution can produce high-quality generation and translation results with little extra overhead. Our method can be easily applied across many domains, matching or beating the performance of specialized methods. We demonstrate its utility in text-to-2D, text-based NeRF optimization, translating paintings to real images, optical illusion generation, and 3D sketch-to-real. We compare our method to existing approaches for score distillation sampling and show that it can produce high-frequency details with realistic colors.
Coherent Zero-Shot Visual Instruction Generation
Jun 06, 2024

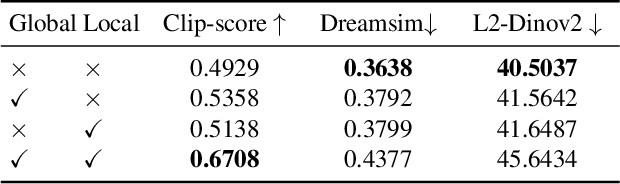

Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
On the Content Bias in Fréchet Video Distance
Apr 18, 2024



Fr\'echet Video Distance (FVD), a prominent metric for evaluating video generation models, is known to conflict with human perception occasionally. In this paper, we aim to explore the extent of FVD's bias toward per-frame quality over temporal realism and identify its sources. We first quantify the FVD's sensitivity to the temporal axis by decoupling the frame and motion quality and find that the FVD increases only slightly with large temporal corruption. We then analyze the generated videos and show that via careful sampling from a large set of generated videos that do not contain motions, one can drastically decrease FVD without improving the temporal quality. Both studies suggest FVD's bias towards the quality of individual frames. We further observe that the bias can be attributed to the features extracted from a supervised video classifier trained on the content-biased dataset. We show that FVD with features extracted from the recent large-scale self-supervised video models is less biased toward image quality. Finally, we revisit a few real-world examples to validate our hypothesis.
Grounded Text-to-Image Synthesis with Attention Refocusing
Jun 08, 2023Driven by scalable diffusion models trained on large-scale paired text-image datasets, text-to-image synthesis methods have shown compelling results. However, these models still fail to precisely follow the text prompt when multiple objects, attributes, and spatial compositions are involved in the prompt. In this paper, we identify the potential reasons in both the cross-attention and self-attention layers of the diffusion model. We propose two novel losses to refocus the attention maps according to a given layout during the sampling process. We perform comprehensive experiments on the DrawBench and HRS benchmarks using layouts synthesized by Large Language Models, showing that our proposed losses can be integrated easily and effectively into existing text-to-image methods and consistently improve their alignment between the generated images and the text prompts.
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models
May 17, 2023Despite tremendous progress in generating high-quality images using diffusion models, synthesizing a sequence of animated frames that are both photorealistic and temporally coherent is still in its infancy. While off-the-shelf billion-scale datasets for image generation are available, collecting similar video data of the same scale is still challenging. Also, training a video diffusion model is computationally much more expensive than its image counterpart. In this work, we explore finetuning a pretrained image diffusion model with video data as a practical solution for the video synthesis task. We find that naively extending the image noise prior to video noise prior in video diffusion leads to sub-optimal performance. Our carefully designed video noise prior leads to substantially better performance. Extensive experimental validation shows that our model, Preserve Your Own Correlation (PYoCo), attains SOTA zero-shot text-to-video results on the UCF-101 and MSR-VTT benchmarks. It also achieves SOTA video generation quality on the small-scale UCF-101 benchmark with a $10\times$ smaller model using significantly less computation than the prior art.
Expressive Text-to-Image Generation with Rich Text
Apr 13, 2023

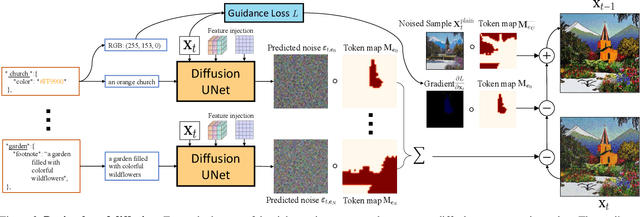

Plain text has become a prevalent interface for text-to-image synthesis. However, its limited customization options hinder users from accurately describing desired outputs. For example, plain text makes it hard to specify continuous quantities, such as the precise RGB color value or importance of each word. Furthermore, creating detailed text prompts for complex scenes is tedious for humans to write and challenging for text encoders to interpret. To address these challenges, we propose using a rich-text editor supporting formats such as font style, size, color, and footnote. We extract each word's attributes from rich text to enable local style control, explicit token reweighting, precise color rendering, and detailed region synthesis. We achieve these capabilities through a region-based diffusion process. We first obtain each word's region based on cross-attention maps of a vanilla diffusion process using plain text. For each region, we enforce its text attributes by creating region-specific detailed prompts and applying region-specific guidance. We present various examples of image generation from rich text and demonstrate that our method outperforms strong baselines with quantitative evaluations.