 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllusion3D: 3D Multiview Illusion with 2D Diffusion Priors
Dec 12, 2024


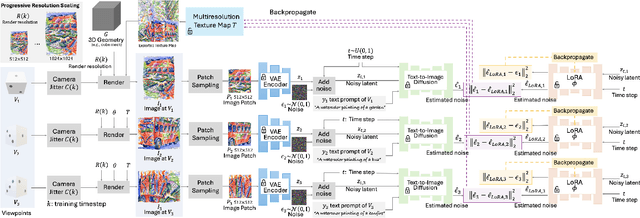
Automatically generating multiview illusions is a compelling challenge, where a single piece of visual content offers distinct interpretations from different viewing perspectives. Traditional methods, such as shadow art and wire art, create interesting 3D illusions but are limited to simple visual outputs (i.e., figure-ground or line drawing), restricting their artistic expressiveness and practical versatility. Recent diffusion-based illusion generation methods can generate more intricate designs but are confined to 2D images. In this work, we present a simple yet effective approach for creating 3D multiview illusions based on user-provided text prompts or images. Our method leverages a pre-trained text-to-image diffusion model to optimize the textures and geometry of neural 3D representations through differentiable rendering. When viewed from multiple angles, this produces different interpretations. We develop several techniques to improve the quality of the generated 3D multiview illusions. We demonstrate the effectiveness of our approach through extensive experiments and showcase illusion generation with diverse 3D forms.
Single-Image 3D Human Digitization with Shape-Guided Diffusion
Nov 15, 2023We present an approach to generate a 360-degree view of a person with a consistent, high-resolution appearance from a single input image. NeRF and its variants typically require videos or images from different viewpoints. Most existing approaches taking monocular input either rely on ground-truth 3D scans for supervision or lack 3D consistency. While recent 3D generative models show promise of 3D consistent human digitization, these approaches do not generalize well to diverse clothing appearances, and the results lack photorealism. Unlike existing work, we utilize high-capacity 2D diffusion models pretrained for general image synthesis tasks as an appearance prior of clothed humans. To achieve better 3D consistency while retaining the input identity, we progressively synthesize multiple views of the human in the input image by inpainting missing regions with shape-guided diffusion conditioned on silhouette and surface normal. We then fuse these synthesized multi-view images via inverse rendering to obtain a fully textured high-resolution 3D mesh of the given person. Experiments show that our approach outperforms prior methods and achieves photorealistic 360-degree synthesis of a wide range of clothed humans with complex textures from a single image.
Text-driven Visual Synthesis with Latent Diffusion Prior
Feb 16, 2023



There has been tremendous progress in large-scale text-to-image synthesis driven by diffusion models enabling versatile downstream applications such as 3D object synthesis from texts, image editing, and customized generation. We present a generic approach using latent diffusion models as powerful image priors for various visual synthesis tasks. Existing methods that utilize such priors fail to use these models' full capabilities. To improve this, our core ideas are 1) a feature matching loss between features from different layers of the decoder to provide detailed guidance and 2) a KL divergence loss to regularize the predicted latent features and stabilize the training. We demonstrate the efficacy of our approach on three different applications, text-to-3D, StyleGAN adaptation, and layered image editing. Extensive results show our method compares favorably against baselines.
Temporally Consistent Semantic Video Editing
Jun 21, 2022

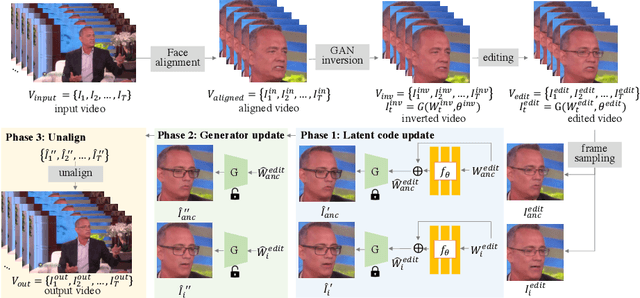
Generative adversarial networks (GANs) have demonstrated impressive image generation quality and semantic editing capability of real images, e.g., changing object classes, modifying attributes, or transferring styles. However, applying these GAN-based editing to a video independently for each frame inevitably results in temporal flickering artifacts. We present a simple yet effective method to facilitate temporally coherent video editing. Our core idea is to minimize the temporal photometric inconsistency by optimizing both the latent code and the pre-trained generator. We evaluate the quality of our editing on different domains and GAN inversion techniques and show favorable results against the baselines.
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
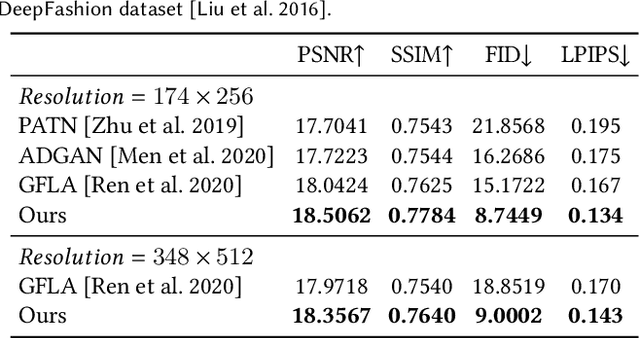


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Guided Image-to-Image Translation with Bi-Directional Feature Transformation
Oct 24, 2019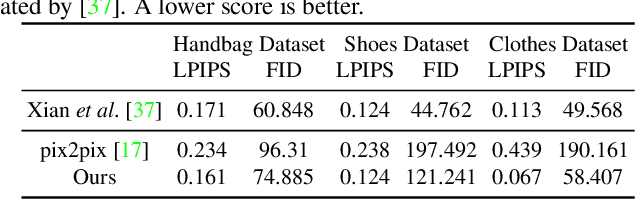
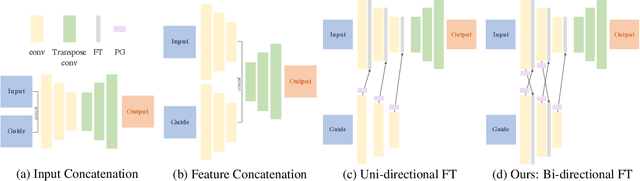
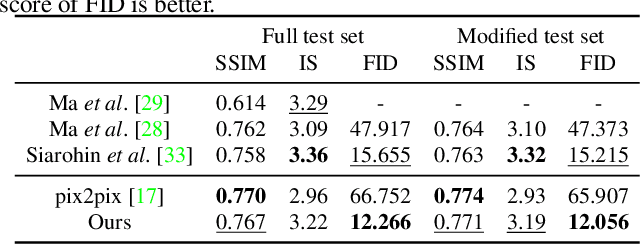
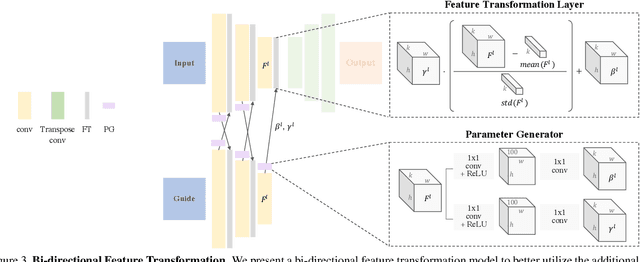
We address the problem of guided image-to-image translation where we translate an input image into another while respecting the constraints provided by an external, user-provided guidance image. Various conditioning methods for leveraging the given guidance image have been explored, including input concatenation , feature concatenation, and conditional affine transformation of feature activations. All these conditioning mechanisms, however, are uni-directional, i.e., no information flow from the input image back to the guidance. To better utilize the constraints of the guidance image, we present a bi-directional feature transformation (bFT) scheme. We show that our bFT scheme outperforms other conditioning schemes and has comparable results to state-of-the-art methods on different tasks.