 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapiens2
Apr 23, 2026We present Sapiens2, a model family of high-resolution transformers for human-centric vision focused on generalization, versatility, and high-fidelity outputs. Our model sizes range from 0.4 to 5 billion parameters, with native 1K resolution and hierarchical variants that support 4K. Sapiens2 substantially improves over its predecessor in both pretraining and post-training. First, to learn features that capture low-level details (for dense prediction) and high-level semantics (for zero-shot or few-label settings), we combine masked image reconstruction with self-distilled contrastive objectives. Our evaluations show that this unified pretraining objective is better suited for a wider range of downstream tasks. Second, along the data axis, we pretrain on a curated dataset of 1 billion high-quality human images and improve the quality and quantity of task annotations. Third, architecturally, we incorporate advances from frontier models that enable longer training schedules with improved stability. Our 4K models adopt windowed attention to reason over longer spatial context and are pretrained with 2K output resolution. Sapiens2 sets a new state-of-the-art and improves over the first generation on pose (+4 mAP), body-part segmentation (+24.3 mIoU), normal estimation (45.6% lower angular error) and extends to new tasks such as pointmap and albedo estimation. Code: https://github.com/facebookresearch/sapiens2
GeoRelight: Learning Joint Geometrical Relighting and Reconstruction with Flexible Multi-Modal Diffusion Transformers
Apr 22, 2026Relighting a person from a single photo is an attractive but ill-posed task, as a 2D image ambiguously entangles 3D geometry, intrinsic appearance, and illumination. Current methods either use sequential pipelines that suffer from error accumulation, or they do not explicitly leverage 3D geometry during relighting, which limits physical consistency. Since relighting and estimation of 3D geometry are mutually beneficial tasks, we propose a unified Multi-Modal Diffusion Transformer (DiT) that jointly solves for both: GeoRelight. We make this possible through two key technical contributions: isotropic NDC-Orthographic Depth (iNOD), a distortion-free 3D representation compatible with latent diffusion models; and a strategic mixed-data training method that combines synthetic and auto-labeled real data. By solving geometry and relighting jointly, GeoRelight achieves better performance than both sequential models and previous systems that ignored geometry.
GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
Apr 09, 2026We present GenLCA, a diffusion-based generative model for generating and editing photorealistic full-body avatars from text and image inputs. The generated avatars are faithful to the inputs, while supporting high-fidelity facial and full-body animations. The core idea is a novel paradigm that enables training a full-body 3D diffusion model from partially observable 2D data, allowing the training dataset to scale to millions of real-world videos. This scalability contributes to the superior photorealism and generalizability of GenLCA. Specifically, we scale up the dataset by repurposing a pretrained feed-forward avatar reconstruction model as an animatable 3D tokenizer, which encodes unstructured video frames into structured 3D tokens. However, most real-world videos only provide partial observations of body parts, resulting in excessive blurring or transparency artifacts in the 3D tokens. To address this, we propose a novel visibility-aware diffusion training strategy that replaces invalid regions with learnable tokens and computes losses only over valid regions. We then train a flow-based diffusion model on the token dataset, inherently maintaining the photorealism and animatability provided by the pretrained avatar reconstruction model. Our approach effectively enables the use of large-scale real-world video data to train a diffusion model natively in 3D. We demonstrate the efficacy of our method through diverse and high-fidelity generation and editing results, outperforming existing solutions by a large margin. The project page is available at https://onethousandwu.com/GenLCA-Page.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
CamLit: Unified Video Diffusion with Explicit Camera and Lighting Control
Mar 15, 2026We present CamLit, the first unified video diffusion model that jointly performs novel view synthesis (NVS) and relighting from a single input image. Given one reference image, a user-defined camera trajectory, and an environment map, CamLit synthesizes a video of the scene from new viewpoints under the specified illumination. Within a single generative process, our model produces temporally coherent and spatially aligned outputs, including relit novel-view frames and corresponding albedo frames, enabling high-quality control of both camera pose and lighting. Qualitative and quantitative experiments demonstrate that CamLit achieves high-fidelity outputs on par with state-of-the-art methods in both novel view synthesis and relighting, without sacrificing visual quality in either task. We show that a single generative model can effectively integrate camera and lighting control, simplifying the video generation pipeline while maintaining competitive performance and consistent realism.
Capture, Canonicalize, Splat: Zero-Shot 3D Gaussian Avatars from Unstructured Phone Images
Oct 15, 2025We present a novel, zero-shot pipeline for creating hyperrealistic, identity-preserving 3D avatars from a few unstructured phone images. Existing methods face several challenges: single-view approaches suffer from geometric inconsistencies and hallucinations, degrading identity preservation, while models trained on synthetic data fail to capture high-frequency details like skin wrinkles and fine hair, limiting realism. Our method introduces two key contributions: (1) a generative canonicalization module that processes multiple unstructured views into a standardized, consistent representation, and (2) a transformer-based model trained on a new, large-scale dataset of high-fidelity Gaussian splatting avatars derived from dome captures of real people. This "Capture, Canonicalize, Splat" pipeline produces static quarter-body avatars with compelling realism and robust identity preservation from unstructured photos.
3DGH: 3D Head Generation with Composable Hair and Face
Jun 25, 2025We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles. Based on this data representation, we design a 3D GAN-based architecture with dual generators and employ a cross-attention mechanism to model the inherent correlation between hair and face. The model is trained on synthetic renderings using carefully designed objectives to stabilize training and facilitate hair-face separation. We conduct extensive experiments to validate the design choice of 3DGH, and evaluate it both qualitatively and quantitatively by comparing with several state-of-the-art 3D GAN methods, demonstrating its effectiveness in unconditional full-head image synthesis and composable 3D hairstyle editing. More details will be available on our project page: https://c-he.github.io/projects/3dgh/.
REWIND: Real-Time Egocentric Whole-Body Motion Diffusion with Exemplar-Based Identity Conditioning
Apr 08, 2025We present REWIND (Real-Time Egocentric Whole-Body Motion Diffusion), a one-step diffusion model for real-time, high-fidelity human motion estimation from egocentric image inputs. While an existing method for egocentric whole-body (i.e., body and hands) motion estimation is non-real-time and acausal due to diffusion-based iterative motion refinement to capture correlations between body and hand poses, REWIND operates in a fully causal and real-time manner. To enable real-time inference, we introduce (1) cascaded body-hand denoising diffusion, which effectively models the correlation between egocentric body and hand motions in a fast, feed-forward manner, and (2) diffusion distillation, which enables high-quality motion estimation with a single denoising step. Our denoising diffusion model is based on a modified Transformer architecture, designed to causally model output motions while enhancing generalizability to unseen motion lengths. Additionally, REWIND optionally supports identity-conditioned motion estimation when identity prior is available. To this end, we propose a novel identity conditioning method based on a small set of pose exemplars of the target identity, which further enhances motion estimation quality. Through extensive experiments, we demonstrate that REWIND significantly outperforms the existing baselines both with and without exemplar-based identity conditioning.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025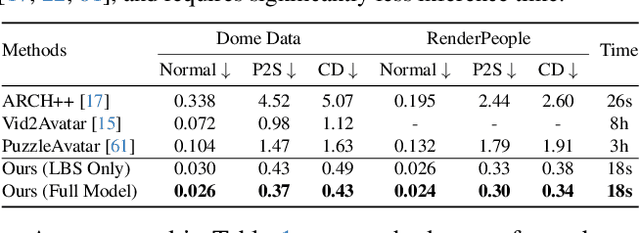
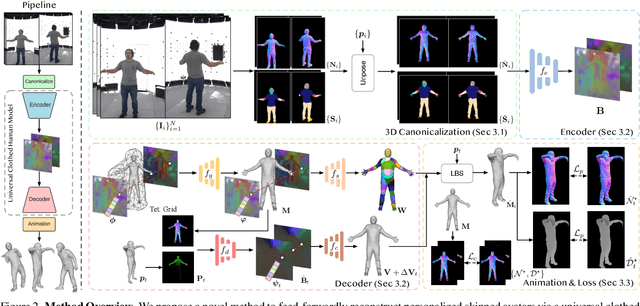
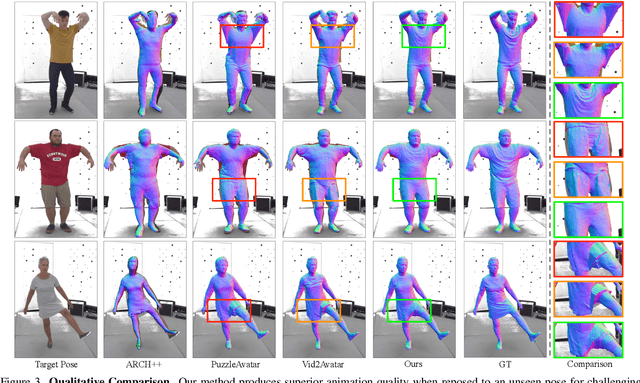
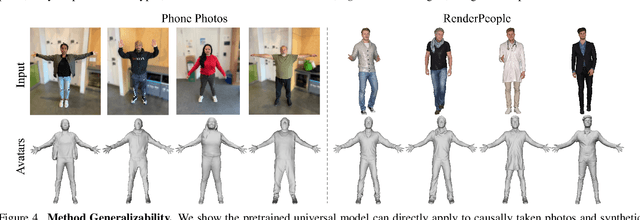
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Mar 03, 2025We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.