 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile DreamFusion: Exploiting Tactile Sensing for 3D Generation
Dec 09, 2024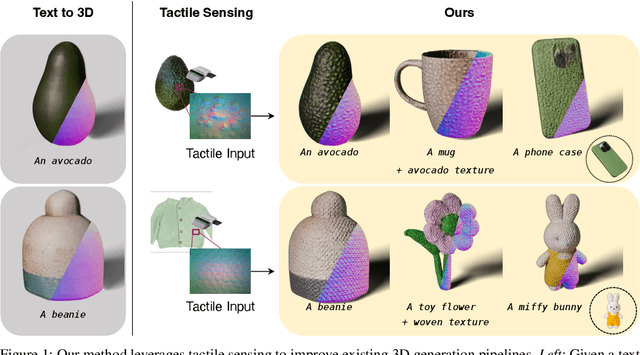
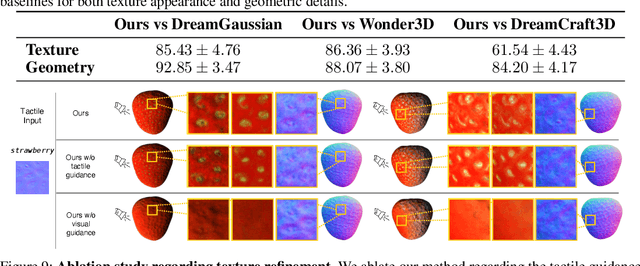
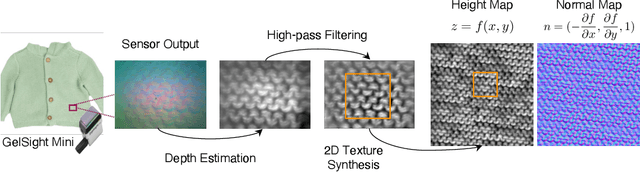

3D generation methods have shown visually compelling results powered by diffusion image priors. However, they often fail to produce realistic geometric details, resulting in overly smooth surfaces or geometric details inaccurately baked in albedo maps. To address this, we introduce a new method that incorporates touch as an additional modality to improve the geometric details of generated 3D assets. We design a lightweight 3D texture field to synthesize visual and tactile textures, guided by 2D diffusion model priors on both visual and tactile domains. We condition the visual texture generation on high-resolution tactile normals and guide the patch-based tactile texture refinement with a customized TextureDreambooth. We further present a multi-part generation pipeline that enables us to synthesize different textures across various regions. To our knowledge, we are the first to leverage high-resolution tactile sensing to enhance geometric details for 3D generation tasks. We evaluate our method in both text-to-3D and image-to-3D settings. Our experiments demonstrate that our method provides customized and realistic fine geometric textures while maintaining accurate alignment between two modalities of vision and touch.
Agent-to-Sim: Learning Interactive Behavior Models from Casual Longitudinal Videos
Oct 21, 2024We present Agent-to-Sim (ATS), a framework for learning interactive behavior models of 3D agents from casual longitudinal video collections. Different from prior works that rely on marker-based tracking and multiview cameras, ATS learns natural behaviors of animal and human agents non-invasively through video observations recorded over a long time-span (e.g., a month) in a single environment. Modeling 3D behavior of an agent requires persistent 3D tracking (e.g., knowing which point corresponds to which) over a long time period. To obtain such data, we develop a coarse-to-fine registration method that tracks the agent and the camera over time through a canonical 3D space, resulting in a complete and persistent spacetime 4D representation. We then train a generative model of agent behaviors using paired data of perception and motion of an agent queried from the 4D reconstruction. ATS enables real-to-sim transfer from video recordings of an agent to an interactive behavior simulator. We demonstrate results on pets (e.g., cat, dog, bunny) and human given monocular RGBD videos captured by a smartphone.
DressRecon: Freeform 4D Human Reconstruction from Monocular Video
Sep 30, 2024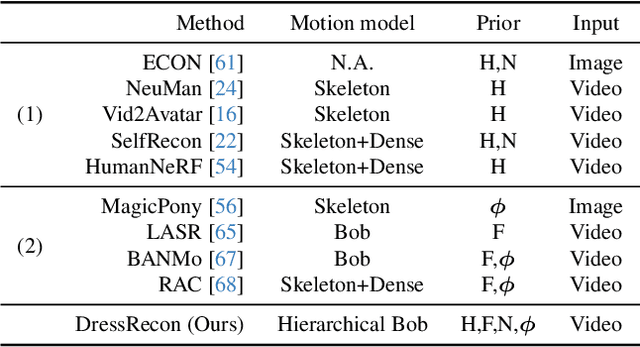
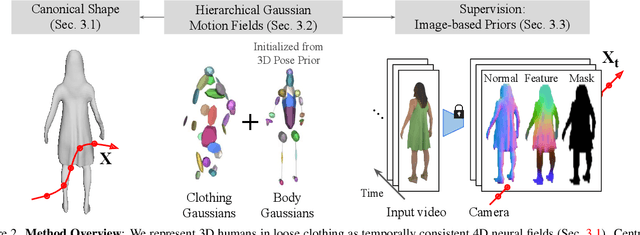
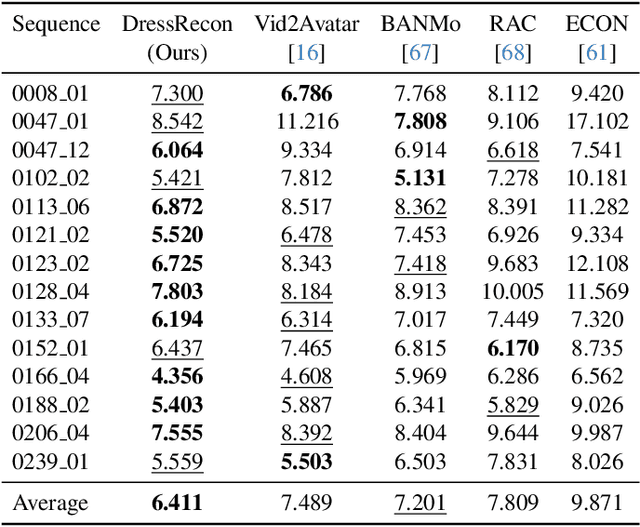
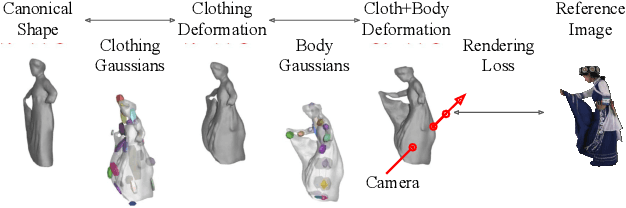
We present a method to reconstruct time-consistent human body models from monocular videos, focusing on extremely loose clothing or handheld object interactions. Prior work in human reconstruction is either limited to tight clothing with no object interactions, or requires calibrated multi-view captures or personalized template scans which are costly to collect at scale. Our key insight for high-quality yet flexible reconstruction is the careful combination of generic human priors about articulated body shape (learned from large-scale training data) with video-specific articulated "bag-of-bones" deformation (fit to a single video via test-time optimization). We accomplish this by learning a neural implicit model that disentangles body versus clothing deformations as separate motion model layers. To capture subtle geometry of clothing, we leverage image-based priors such as human body pose, surface normals, and optical flow during optimization. The resulting neural fields can be extracted into time-consistent meshes, or further optimized as explicit 3D Gaussians for high-fidelity interactive rendering. On datasets with highly challenging clothing deformations and object interactions, DressRecon yields higher-fidelity 3D reconstructions than prior art. Project page: https://jefftan969.github.io/dressrecon/
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
Dec 04, 2023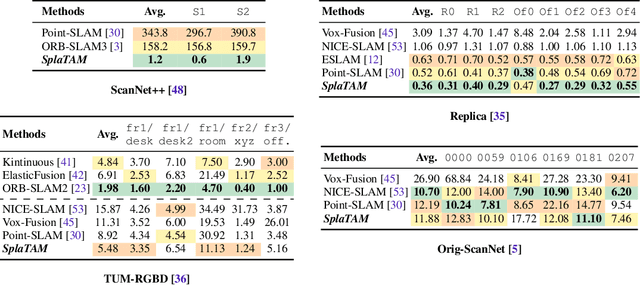
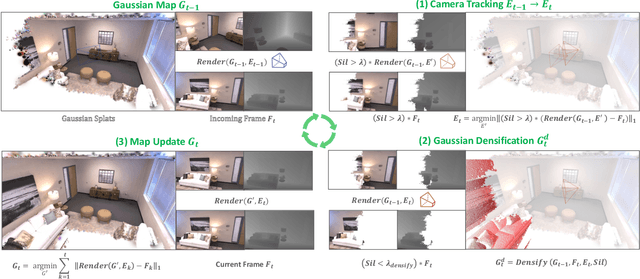
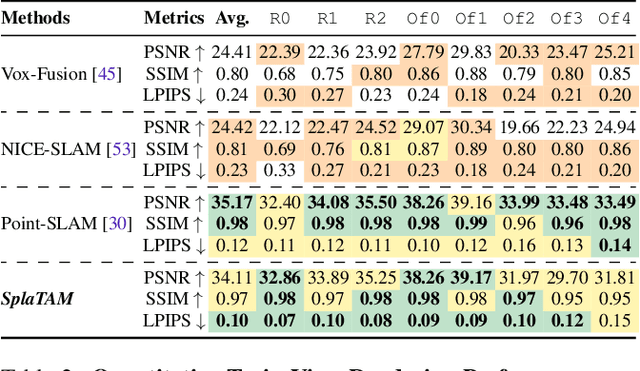

Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by 3D Gaussians can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. We employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments show that SplaTAM achieves up to 2X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches, while allowing real-time rendering of a high-resolution dense 3D map.
Reconstructing Animatable Categories from Videos
May 10, 2023



Building animatable 3D models is challenging due to the need for 3D scans, laborious registration, and manual rigging, which are difficult to scale to arbitrary categories. Recently, differentiable rendering provides a pathway to obtain high-quality 3D models from monocular videos, but these are limited to rigid categories or single instances. We present RAC that builds category 3D models from monocular videos while disentangling variations over instances and motion over time. Three key ideas are introduced to solve this problem: (1) specializing a skeleton to instances via optimization, (2) a method for latent space regularization that encourages shared structure across a category while maintaining instance details, and (3) using 3D background models to disentangle objects from the background. We show that 3D models of humans, cats, and dogs can be learned from 50-100 internet videos.
SLoMo: A General System for Legged Robot Motion Imitation from Casual Videos
Apr 27, 2023We present SLoMo: a first-of-its-kind framework for transferring skilled motions from casually captured "in the wild" video footage of humans and animals to legged robots. SLoMo works in three stages: 1) synthesize a physically plausible reconstructed key-point trajectory from monocular videos; 2) optimize a dynamically feasible reference trajectory for the robot offline that includes body and foot motion, as well as contact sequences that closely tracks the key points; 3) track the reference trajectory online using a general-purpose model-predictive controller on robot hardware. Traditional motion imitation for legged motor skills often requires expert animators, collaborative demonstrations, and/or expensive motion capture equipment, all of which limits scalability. Instead, SLoMo only relies on easy-to-obtain monocular video footage, readily available in online repositories such as YouTube. It converts videos into motion primitives that can be executed reliably by real-world robots. We demonstrate our approach by transferring the motions of cats, dogs, and humans to example robots including a quadruped (on hardware) and a humanoid (in simulation). To the best knowledge of the authors, this is the first attempt at a general-purpose motion transfer framework that imitates animal and human motions on legged robots directly from casual videos without artificial markers or labels.
Total-Recon: Deformable Scene Reconstruction for Embodied View Synthesis
Apr 24, 2023We explore the task of embodied view synthesis from monocular videos of deformable scenes. Given a minute-long RGBD video of people interacting with their pets, we render the scene from novel camera trajectories derived from in-scene motion of actors: (1) egocentric cameras that simulate the point of view of a target actor and (2) 3rd-person cameras that follow the actor. Building such a system requires reconstructing the root-body and articulated motion of each actor in the scene, as well as a scene representation that supports free-viewpoint synthesis. Longer videos are more likely to capture the scene from diverse viewpoints (which helps reconstruction) but are also more likely to contain larger motions (which complicates reconstruction). To address these challenges, we present Total-Recon, the first method to photorealistically reconstruct deformable scenes from long monocular RGBD videos. Crucially, to scale to long videos, our method hierarchically decomposes the scene motion into the motion of each object, which itself is decomposed into global root-body motion and local articulations. To quantify such "in-the-wild" reconstruction and view synthesis, we collect ground-truth data from a specialized stereo RGBD capture rig for 11 challenging videos, significantly outperforming prior art. Code, videos, and data can be found at https://andrewsonga.github.io/totalrecon .
3D-aware Conditional Image Synthesis
Feb 16, 2023



We propose pix2pix3D, a 3D-aware conditional generative model for controllable photorealistic image synthesis. Given a 2D label map, such as a segmentation or edge map, our model learns to synthesize a corresponding image from different viewpoints. To enable explicit 3D user control, we extend conditional generative models with neural radiance fields. Given widely-available monocular images and label map pairs, our model learns to assign a label to every 3D point in addition to color and density, which enables it to render the image and pixel-aligned label map simultaneously. Finally, we build an interactive system that allows users to edit the label map from any viewpoint and generate outputs accordingly.
BANMo: Building Animatable 3D Neural Models from Many Casual Videos
Dec 24, 2021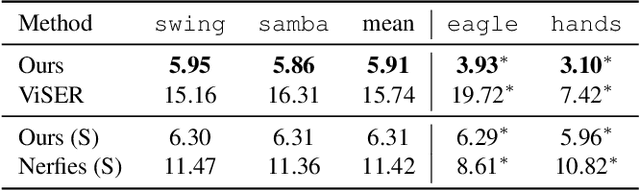
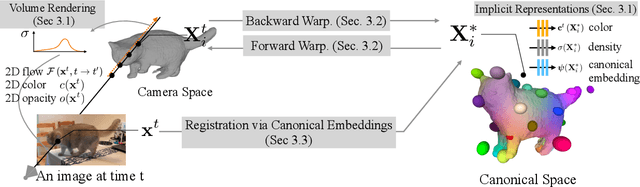

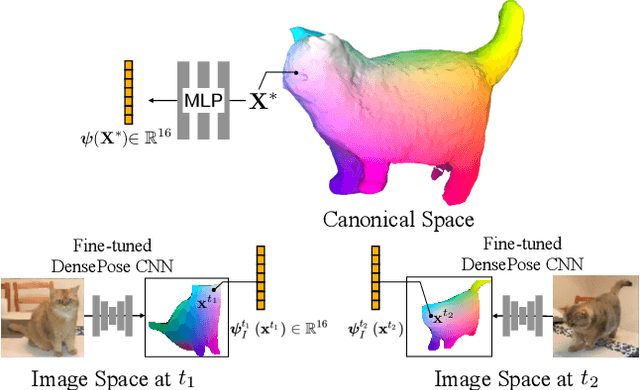
Prior work for articulated 3D shape reconstruction often relies on specialized sensors (e.g., synchronized multi-camera systems), or pre-built 3D deformable models (e.g., SMAL or SMPL). Such methods are not able to scale to diverse sets of objects in the wild. We present BANMo, a method that requires neither a specialized sensor nor a pre-defined template shape. BANMo builds high-fidelity, articulated 3D models (including shape and animatable skinning weights) from many monocular casual videos in a differentiable rendering framework. While the use of many videos provides more coverage of camera views and object articulations, they introduce significant challenges in establishing correspondence across scenes with different backgrounds, illumination conditions, etc. Our key insight is to merge three schools of thought; (1) classic deformable shape models that make use of articulated bones and blend skinning, (2) volumetric neural radiance fields (NeRFs) that are amenable to gradient-based optimization, and (3) canonical embeddings that generate correspondences between pixels and an articulated model. We introduce neural blend skinning models that allow for differentiable and invertible articulated deformations. When combined with canonical embeddings, such models allow us to establish dense correspondences across videos that can be self-supervised with cycle consistency. On real and synthetic datasets, BANMo shows higher-fidelity 3D reconstructions than prior works for humans and animals, with the ability to render realistic images from novel viewpoints and poses. Project webpage: banmo-www.github.io .
NeRS: Neural Reflectance Surfaces for Sparse-view 3D Reconstruction in the Wild
Oct 18, 2021
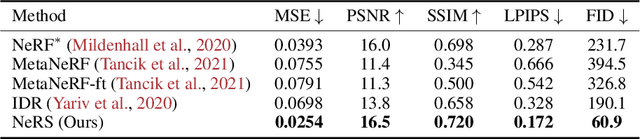
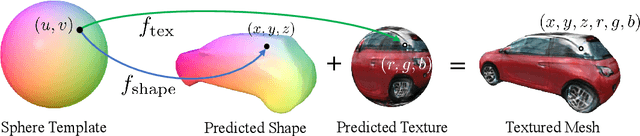

Recent history has seen a tremendous growth of work exploring implicit representations of geometry and radiance, popularized through Neural Radiance Fields (NeRF). Such works are fundamentally based on a (implicit) volumetric representation of occupancy, allowing them to model diverse scene structure including translucent objects and atmospheric obscurants. But because the vast majority of real-world scenes are composed of well-defined surfaces, we introduce a surface analog of such implicit models called Neural Reflectance Surfaces (NeRS). NeRS learns a neural shape representation of a closed surface that is diffeomorphic to a sphere, guaranteeing water-tight reconstructions. Even more importantly, surface parameterizations allow NeRS to learn (neural) bidirectional surface reflectance functions (BRDFs) that factorize view-dependent appearance into environmental illumination, diffuse color (albedo), and specular "shininess." Finally, rather than illustrating our results on synthetic scenes or controlled in-the-lab capture, we assemble a novel dataset of multi-view images from online marketplaces for selling goods. Such "in-the-wild" multi-view image sets pose a number of challenges, including a small number of views with unknown/rough camera estimates. We demonstrate that surface-based neural reconstructions enable learning from such data, outperforming volumetric neural rendering-based reconstructions. We hope that NeRS serves as a first step toward building scalable, high-quality libraries of real-world shape, materials, and illumination. The project page with code and video visualizations can be found at https://jasonyzhang.com/ners.