 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDressRecon: Freeform 4D Human Reconstruction from Monocular Video
Paper and Code
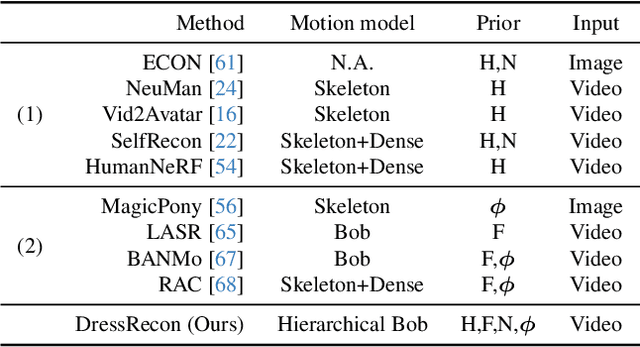
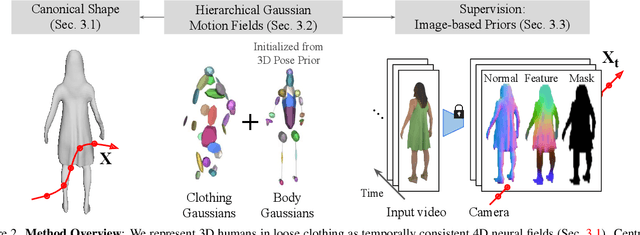
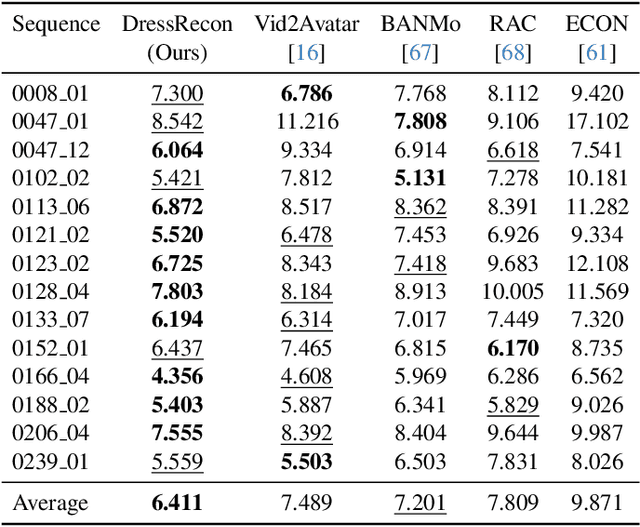
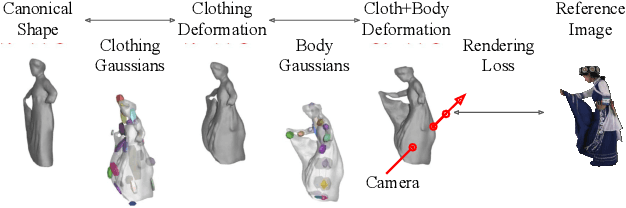
We present a method to reconstruct time-consistent human body models from monocular videos, focusing on extremely loose clothing or handheld object interactions. Prior work in human reconstruction is either limited to tight clothing with no object interactions, or requires calibrated multi-view captures or personalized template scans which are costly to collect at scale. Our key insight for high-quality yet flexible reconstruction is the careful combination of generic human priors about articulated body shape (learned from large-scale training data) with video-specific articulated "bag-of-bones" deformation (fit to a single video via test-time optimization). We accomplish this by learning a neural implicit model that disentangles body versus clothing deformations as separate motion model layers. To capture subtle geometry of clothing, we leverage image-based priors such as human body pose, surface normals, and optical flow during optimization. The resulting neural fields can be extracted into time-consistent meshes, or further optimized as explicit 3D Gaussians for high-fidelity interactive rendering. On datasets with highly challenging clothing deformations and object interactions, DressRecon yields higher-fidelity 3D reconstructions than prior art. Project page: https://jefftan969.github.io/dressrecon/