 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow3r: Factored Flow Prediction for Scalable Visual Geometry Learning
Feb 23, 2026Current feed-forward 3D/4D reconstruction systems rely on dense geometry and pose supervision -- expensive to obtain at scale and particularly scarce for dynamic real-world scenes. We present Flow3r, a framework that augments visual geometry learning with dense 2D correspondences (`flow') as supervision, enabling scalable training from unlabeled monocular videos. Our key insight is that the flow prediction module should be factored: predicting flow between two images using geometry latents from one and pose latents from the other. This factorization directly guides the learning of both scene geometry and camera motion, and naturally extends to dynamic scenes. In controlled experiments, we show that factored flow prediction outperforms alternative designs and that performance scales consistently with unlabeled data. Integrating factored flow into existing visual geometry architectures and training with ${\sim}800$K unlabeled videos, Flow3r achieves state-of-the-art results across eight benchmarks spanning static and dynamic scenes, with its largest gains on in-the-wild dynamic videos where labeled data is most scarce.
Dex4D: Task-Agnostic Point Track Policy for Sim-to-Real Dexterous Manipulation
Feb 17, 2026Learning generalist policies capable of accomplishing a plethora of everyday tasks remains an open challenge in dexterous manipulation. In particular, collecting large-scale manipulation data via real-world teleoperation is expensive and difficult to scale. While learning in simulation provides a feasible alternative, designing multiple task-specific environments and rewards for training is similarly challenging. We propose Dex4D, a framework that instead leverages simulation for learning task-agnostic dexterous skills that can be flexibly recomposed to perform diverse real-world manipulation tasks. Specifically, Dex4D learns a domain-agnostic 3D point track conditioned policy capable of manipulating any object to any desired pose. We train this 'Anypose-to-Anypose' policy in simulation across thousands of objects with diverse pose configurations, covering a broad space of robot-object interactions that can be composed at test time. At deployment, this policy can be zero-shot transferred to real-world tasks without finetuning, simply by prompting it with desired object-centric point tracks extracted from generated videos. During execution, Dex4D uses online point tracking for closed-loop perception and control. Extensive experiments in simulation and on real robots show that our method enables zero-shot deployment for diverse dexterous manipulation tasks and yields consistent improvements over prior baselines. Furthermore, we demonstrate strong generalization to novel objects, scene layouts, backgrounds, and trajectories, highlighting the robustness and scalability of the proposed framework.
EditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing
Feb 16, 2026High-fidelity generative video editing has seen significant quality improvements by leveraging pre-trained video foundation models. However, their computational cost is a major bottleneck, as they are often designed to inefficiently process the full video context regardless of the inpainting mask's size, even for sparse, localized edits. In this paper, we introduce EditCtrl, an efficient video inpainting control framework that focuses computation only where it is needed. Our approach features a novel local video context module that operates solely on masked tokens, yielding a computational cost proportional to the edit size. This local-first generation is then guided by a lightweight temporal global context embedder that ensures video-wide context consistency with minimal overhead. Not only is EditCtrl 10 times more compute efficient than state-of-the-art generative editing methods, it even improves editing quality compared to methods designed with full-attention. Finally, we showcase how EditCtrl unlocks new capabilities, including multi-region editing with text prompts and autoregressive content propagation.
RayRoPE: Projective Ray Positional Encoding for Multi-view Attention
Jan 21, 2026We study positional encodings for multi-view transformers that process tokens from a set of posed input images, and seek a mechanism that encodes patches uniquely, allows SE(3)-invariant attention with multi-frequency similarity, and can be adaptive to the geometry of the underlying scene. We find that prior (absolute or relative) encoding schemes for multi-view attention do not meet the above desiderata, and present RayRoPE to address this gap. RayRoPE represents patch positions based on associated rays but leverages a predicted point along the ray instead of the direction for a geometry-aware encoding. To achieve SE(3) invariance, RayRoPE computes query-frame projective coordinates for computing multi-frequency similarity. Lastly, as the 'predicted' 3D point along a ray may not be precise, RayRoPE presents a mechanism to analytically compute the expected position encoding under uncertainty. We validate RayRoPE on the tasks of novel-view synthesis and stereo depth estimation and show that it consistently improves over alternate position encoding schemes (e.g. 15% relative improvement on LPIPS in CO3D). We also show that RayRoPE can seamlessly incorporate RGB-D input, resulting in even larger gains over alternatives that cannot positionally encode this information.
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
Dec 21, 2025We introduce CRISP, a method that recovers simulatable human motion and scene geometry from monocular video. Prior work on joint human-scene reconstruction relies on data-driven priors and joint optimization with no physics in the loop, or recovers noisy geometry with artifacts that cause motion tracking policies with scene interactions to fail. In contrast, our key insight is to recover convex, clean, and simulation-ready geometry by fitting planar primitives to a point cloud reconstruction of the scene, via a simple clustering pipeline over depth, normals, and flow. To reconstruct scene geometry that might be occluded during interactions, we make use of human-scene contact modeling (e.g., we use human posture to reconstruct the occluded seat of a chair). Finally, we ensure that human and scene reconstructions are physically-plausible by using them to drive a humanoid controller via reinforcement learning. Our approach reduces motion tracking failure rates from 55.2\% to 6.9\% on human-centric video benchmarks (EMDB, PROX), while delivering a 43\% faster RL simulation throughput. We further validate it on in-the-wild videos including casually-captured videos, Internet videos, and even Sora-generated videos. This demonstrates CRISP's ability to generate physically-valid human motion and interaction environments at scale, greatly advancing real-to-sim applications for robotics and AR/VR.
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Dec 11, 2025



Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
LightSwitch: Multi-view Relighting with Material-guided Diffusion
Aug 08, 2025Recent approaches for 3D relighting have shown promise in integrating 2D image relighting generative priors to alter the appearance of a 3D representation while preserving the underlying structure. Nevertheless, generative priors used for 2D relighting that directly relight from an input image do not take advantage of intrinsic properties of the subject that can be inferred or cannot consider multi-view data at scale, leading to subpar relighting. In this paper, we propose Lightswitch, a novel finetuned material-relighting diffusion framework that efficiently relights an arbitrary number of input images to a target lighting condition while incorporating cues from inferred intrinsic properties. By using multi-view and material information cues together with a scalable denoising scheme, our method consistently and efficiently relights dense multi-view data of objects with diverse material compositions. We show that our 2D relighting prediction quality exceeds previous state-of-the-art relighting priors that directly relight from images. We further demonstrate that LightSwitch matches or outperforms state-of-the-art diffusion inverse rendering methods in relighting synthetic and real objects in as little as 2 minutes.
DemoDiffusion: One-Shot Human Imitation using pre-trained Diffusion Policy
Jun 25, 2025



We propose DemoDiffusion, a simple and scalable method for enabling robots to perform manipulation tasks in natural environments by imitating a single human demonstration. Our approach is based on two key insights. First, the hand motion in a human demonstration provides a useful prior for the robot's end-effector trajectory, which we can convert into a rough open-loop robot motion trajectory via kinematic retargeting. Second, while this retargeted motion captures the overall structure of the task, it may not align well with plausible robot actions in-context. To address this, we leverage a pre-trained generalist diffusion policy to modify the trajectory, ensuring it both follows the human motion and remains within the distribution of plausible robot actions. Our approach avoids the need for online reinforcement learning or paired human-robot data, enabling robust adaptation to new tasks and scenes with minimal manual effort. Experiments in both simulation and real-world settings show that DemoDiffusion outperforms both the base policy and the retargeted trajectory, enabling the robot to succeed even on tasks where the pre-trained generalist policy fails entirely. Project page: https://demodiffusion.github.io/
UniPhy: Learning a Unified Constitutive Model for Inverse Physics Simulation
May 22, 2025We propose UniPhy, a common latent-conditioned neural constitutive model that can encode the physical properties of diverse materials. At inference UniPhy allows `inverse simulation' i.e. inferring material properties by optimizing the scene-specific latent to match the available observations via differentiable simulation. In contrast to existing methods that treat such inference as system identification, UniPhy does not rely on user-specified material type information. Compared to prior neural constitutive modeling approaches which learn instance specific networks, the shared training across materials improves both, robustness and accuracy of the estimates. We train UniPhy using simulated trajectories across diverse geometries and materials -- elastic, plasticine, sand, and fluids (Newtonian & non-Newtonian). At inference, given an object with unknown material properties, UniPhy can infer the material properties via latent optimization to match the motion observations, and can then allow re-simulating the object under diverse scenarios. We compare UniPhy against prior inverse simulation methods, and show that the inference from UniPhy enables more accurate replay and re-simulation under novel conditions.
DiffusionSfM: Predicting Structure and Motion via Ray Origin and Endpoint Diffusion
May 08, 2025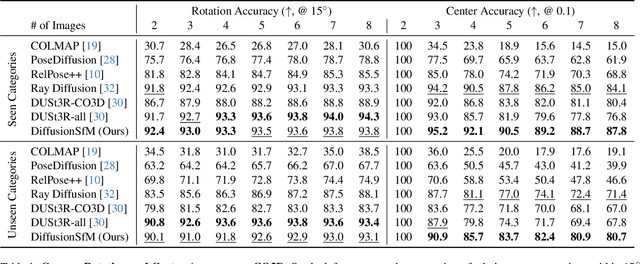
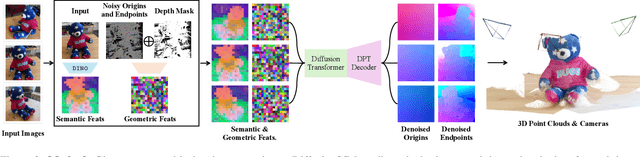

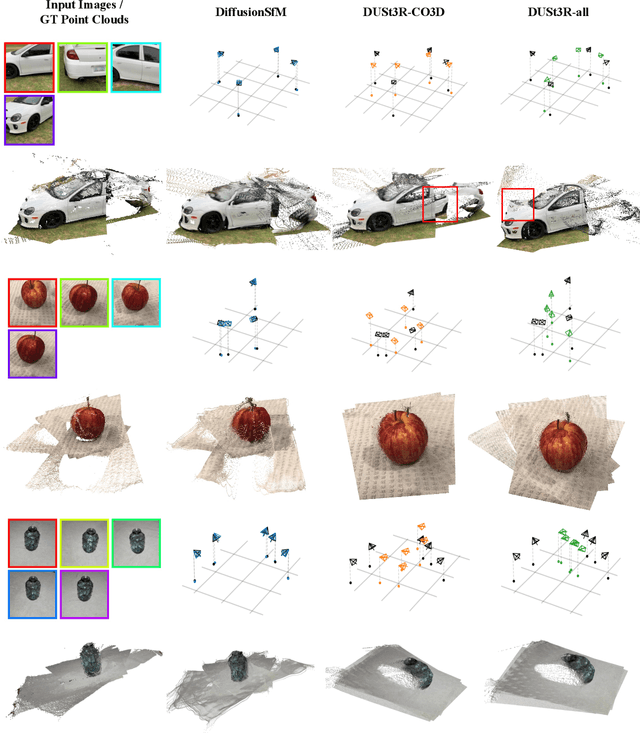
Current Structure-from-Motion (SfM) methods typically follow a two-stage pipeline, combining learned or geometric pairwise reasoning with a subsequent global optimization step. In contrast, we propose a data-driven multi-view reasoning approach that directly infers 3D scene geometry and camera poses from multi-view images. Our framework, DiffusionSfM, parameterizes scene geometry and cameras as pixel-wise ray origins and endpoints in a global frame and employs a transformer-based denoising diffusion model to predict them from multi-view inputs. To address practical challenges in training diffusion models with missing data and unbounded scene coordinates, we introduce specialized mechanisms that ensure robust learning. We empirically validate DiffusionSfM on both synthetic and real datasets, demonstrating that it outperforms classical and learning-based approaches while naturally modeling uncertainty.