 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPhy: Learning a Unified Constitutive Model for Inverse Physics Simulation
May 22, 2025We propose UniPhy, a common latent-conditioned neural constitutive model that can encode the physical properties of diverse materials. At inference UniPhy allows `inverse simulation' i.e. inferring material properties by optimizing the scene-specific latent to match the available observations via differentiable simulation. In contrast to existing methods that treat such inference as system identification, UniPhy does not rely on user-specified material type information. Compared to prior neural constitutive modeling approaches which learn instance specific networks, the shared training across materials improves both, robustness and accuracy of the estimates. We train UniPhy using simulated trajectories across diverse geometries and materials -- elastic, plasticine, sand, and fluids (Newtonian & non-Newtonian). At inference, given an object with unknown material properties, UniPhy can infer the material properties via latent optimization to match the motion observations, and can then allow re-simulating the object under diverse scenarios. We compare UniPhy against prior inverse simulation methods, and show that the inference from UniPhy enables more accurate replay and re-simulation under novel conditions.
Cube: A Roblox View of 3D Intelligence
Mar 19, 2025



Foundation models trained on vast amounts of data have demonstrated remarkable reasoning and generation capabilities in the domains of text, images, audio and video. Our goal at Roblox is to build such a foundation model for 3D intelligence, a model that can support developers in producing all aspects of a Roblox experience, from generating 3D objects and scenes to rigging characters for animation to producing programmatic scripts describing object behaviors. We discuss three key design requirements for such a 3D foundation model and then present our first step towards building such a model. We expect that 3D geometric shapes will be a core data type and describe our solution for 3D shape tokenizer. We show how our tokenization scheme can be used in applications for text-to-shape generation, shape-to-text generation and text-to-scene generation. We demonstrate how these applications can collaborate with existing large language models (LLMs) to perform scene analysis and reasoning. We conclude with a discussion outlining our path to building a fully unified foundation model for 3D intelligence.
PrEditor3D: Fast and Precise 3D Shape Editing
Dec 09, 2024We propose a training-free approach to 3D editing that enables the editing of a single shape within a few minutes. The edited 3D mesh aligns well with the prompts, and remains identical for regions that are not intended to be altered. To this end, we first project the 3D object onto 4-view images and perform synchronized multi-view image editing along with user-guided text prompts and user-provided rough masks. However, the targeted regions to be edited are ambiguous due to projection from 3D to 2D. To ensure precise editing only in intended regions, we develop a 3D segmentation pipeline that detects edited areas in 3D space, followed by a merging algorithm to seamlessly integrate edited 3D regions with the original input. Extensive experiments demonstrate the superiority of our method over previous approaches, enabling fast, high-quality editing while preserving unintended regions.
4Real-Video: Learning Generalizable Photo-Realistic 4D Video Diffusion
Dec 05, 2024



We propose 4Real-Video, a novel framework for generating 4D videos, organized as a grid of video frames with both time and viewpoint axes. In this grid, each row contains frames sharing the same timestep, while each column contains frames from the same viewpoint. We propose a novel two-stream architecture. One stream performs viewpoint updates on columns, and the other stream performs temporal updates on rows. After each diffusion transformer layer, a synchronization layer exchanges information between the two token streams. We propose two implementations of the synchronization layer, using either hard or soft synchronization. This feedforward architecture improves upon previous work in three ways: higher inference speed, enhanced visual quality (measured by FVD, CLIP, and VideoScore), and improved temporal and viewpoint consistency (measured by VideoScore and Dust3R-Confidence).
DELTA: Dense Efficient Long-range 3D Tracking for any video
Oct 31, 2024Tracking dense 3D motion from monocular videos remains challenging, particularly when aiming for pixel-level precision over long sequences. We introduce \Approach, a novel method that efficiently tracks every pixel in 3D space, enabling accurate motion estimation across entire videos. Our approach leverages a joint global-local attention mechanism for reduced-resolution tracking, followed by a transformer-based upsampler to achieve high-resolution predictions. Unlike existing methods, which are limited by computational inefficiency or sparse tracking, \Approach delivers dense 3D tracking at scale, running over 8x faster than previous methods while achieving state-of-the-art accuracy. Furthermore, we explore the impact of depth representation on tracking performance and identify log-depth as the optimal choice. Extensive experiments demonstrate the superiority of \Approach on multiple benchmarks, achieving new state-of-the-art results in both 2D and 3D dense tracking tasks. Our method provides a robust solution for applications requiring fine-grained, long-term motion tracking in 3D space.
Pixel-Aligned Multi-View Generation with Depth Guided Decoder
Aug 26, 2024
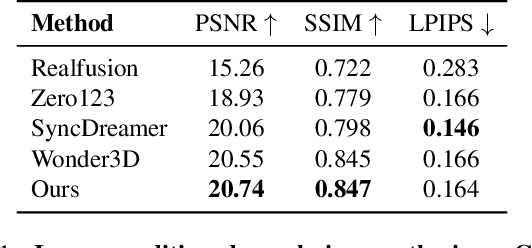
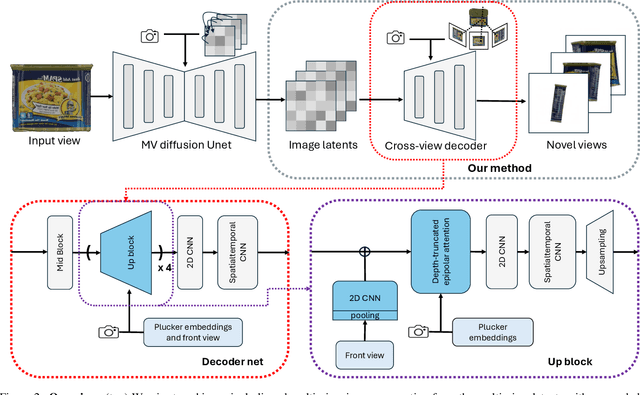

The task of image-to-multi-view generation refers to generating novel views of an instance from a single image. Recent methods achieve this by extending text-to-image latent diffusion models to multi-view version, which contains an VAE image encoder and a U-Net diffusion model. Specifically, these generation methods usually fix VAE and finetune the U-Net only. However, the significant downscaling of the latent vectors computed from the input images and independent decoding leads to notable pixel-level misalignment across multiple views. To address this, we propose a novel method for pixel-level image-to-multi-view generation. Unlike prior work, we incorporate attention layers across multi-view images in the VAE decoder of a latent video diffusion model. Specifically, we introduce a depth-truncated epipolar attention, enabling the model to focus on spatially adjacent regions while remaining memory efficient. Applying depth-truncated attn is challenging during inference as the ground-truth depth is usually difficult to obtain and pre-trained depth estimation models is hard to provide accurate depth. Thus, to enhance the generalization to inaccurate depth when ground truth depth is missing, we perturb depth inputs during training. During inference, we employ a rapid multi-view to 3D reconstruction approach, NeuS, to obtain coarse depth for the depth-truncated epipolar attention. Our model enables better pixel alignment across multi-view images. Moreover, we demonstrate the efficacy of our approach in improving downstream multi-view to 3D reconstruction tasks.
4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models
Jun 11, 2024



Existing dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets. As a result, the generated scenes are often object-centric and lack photorealism. To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets. Our method begins by generating a reference video using the video generation model. We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video. To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections. We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video. The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation.
GTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement
Jun 09, 2024We propose a novel approach for 3D mesh reconstruction from multi-view images. Our method takes inspiration from large reconstruction models like LRM that use a transformer-based triplane generator and a Neural Radiance Field (NeRF) model trained on multi-view images. However, in our method, we introduce several important modifications that allow us to significantly enhance 3D reconstruction quality. First of all, we examine the original LRM architecture and find several shortcomings. Subsequently, we introduce respective modifications to the LRM architecture, which lead to improved multi-view image representation and more computationally efficient training. Second, in order to improve geometry reconstruction and enable supervision at full image resolution, we extract meshes from the NeRF field in a differentiable manner and fine-tune the NeRF model through mesh rendering. These modifications allow us to achieve state-of-the-art performance on both 2D and 3D evaluation metrics, such as a PSNR of 28.67 on Google Scanned Objects (GSO) dataset. Despite these superior results, our feed-forward model still struggles to reconstruct complex textures, such as text and portraits on assets. To address this, we introduce a lightweight per-instance texture refinement procedure. This procedure fine-tunes the triplane representation and the NeRF color estimation model on the mesh surface using the input multi-view images in just 4 seconds. This refinement improves the PSNR to 29.79 and achieves faithful reconstruction of complex textures, such as text. Additionally, our approach enables various downstream applications, including text- or image-to-3D generation.
AToM: Amortized Text-to-Mesh using 2D Diffusion
Feb 01, 2024We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail time-consuming per-prompt optimization and commonly output representations other than polygonal meshes, AToM directly generates high-quality textured meshes in less than 1 second with around 10 times reduction in the training cost, and generalizes to unseen prompts. Our key idea is a novel triplane-based text-to-mesh architecture with a two-stage amortized optimization strategy that ensures stable training and enables scalability. Through extensive experiments on various prompt benchmarks, AToM significantly outperforms state-of-the-art amortized approaches with over 4 times higher accuracy (in DF415 dataset) and produces more distinguishable and higher-quality 3D outputs. AToM demonstrates strong generalizability, offering finegrained 3D assets for unseen interpolated prompts without further optimization during inference, unlike per-prompt solutions.
Diffusion Priors for Dynamic View Synthesis from Monocular Videos
Jan 10, 2024Dynamic novel view synthesis aims to capture the temporal evolution of visual content within videos. Existing methods struggle to distinguishing between motion and structure, particularly in scenarios where camera poses are either unknown or constrained compared to object motion. Furthermore, with information solely from reference images, it is extremely challenging to hallucinate unseen regions that are occluded or partially observed in the given videos. To address these issues, we first finetune a pretrained RGB-D diffusion model on the video frames using a customization technique. Subsequently, we distill the knowledge from the finetuned model to a 4D representations encompassing both dynamic and static Neural Radiance Fields (NeRF) components. The proposed pipeline achieves geometric consistency while preserving the scene identity. We perform thorough experiments to evaluate the efficacy of the proposed method qualitatively and quantitatively. Our results demonstrate the robustness and utility of our approach in challenging cases, further advancing dynamic novel view synthesis.