 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-subject Open-set Personalization in Video Generation
Jan 10, 2025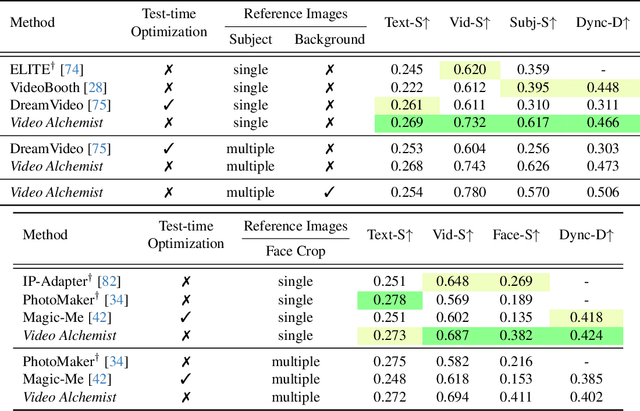
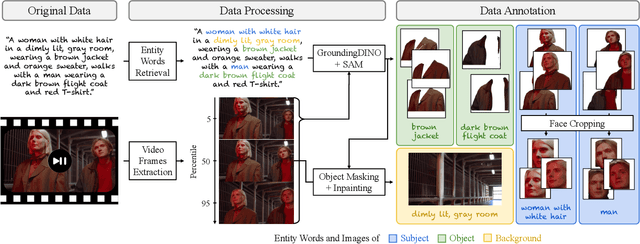
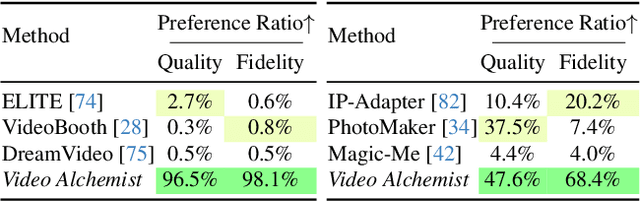
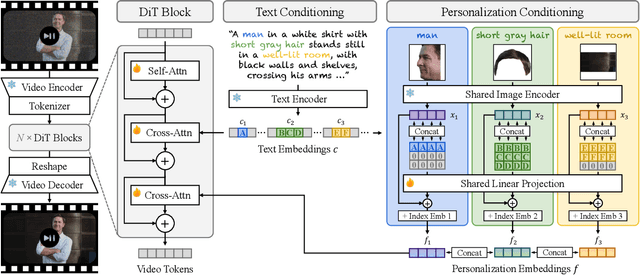
Video personalization methods allow us to synthesize videos with specific concepts such as people, pets, and places. However, existing methods often focus on limited domains, require time-consuming optimization per subject, or support only a single subject. We present Video Alchemist $-$ a video model with built-in multi-subject, open-set personalization capabilities for both foreground objects and background, eliminating the need for time-consuming test-time optimization. Our model is built on a new Diffusion Transformer module that fuses each conditional reference image and its corresponding subject-level text prompt with cross-attention layers. Developing such a large model presents two main challenges: dataset and evaluation. First, as paired datasets of reference images and videos are extremely hard to collect, we sample selected video frames as reference images and synthesize a clip of the target video. However, while models can easily denoise training videos given reference frames, they fail to generalize to new contexts. To mitigate this issue, we design a new automatic data construction pipeline with extensive image augmentations. Second, evaluating open-set video personalization is a challenge in itself. To address this, we introduce a personalization benchmark that focuses on accurate subject fidelity and supports diverse personalization scenarios. Finally, our extensive experiments show that our method significantly outperforms existing personalization methods in both quantitative and qualitative evaluations.
Mind the Time: Temporally-Controlled Multi-Event Video Generation
Dec 06, 2024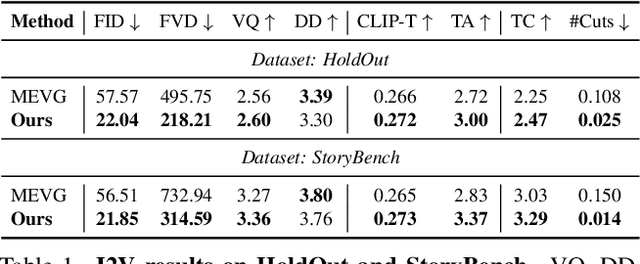

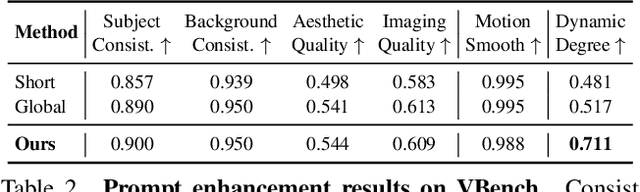
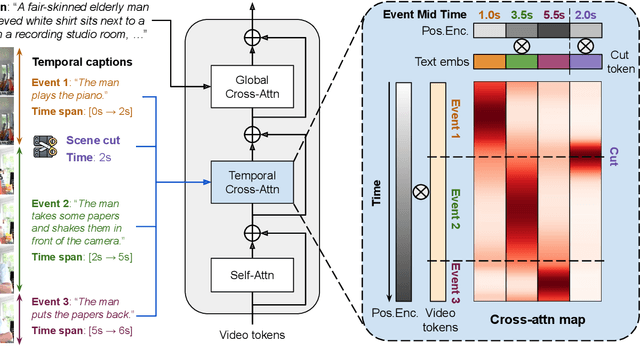
Real-world videos consist of sequences of events. Generating such sequences with precise temporal control is infeasible with existing video generators that rely on a single paragraph of text as input. When tasked with generating multiple events described using a single prompt, such methods often ignore some of the events or fail to arrange them in the correct order. To address this limitation, we present MinT, a multi-event video generator with temporal control. Our key insight is to bind each event to a specific period in the generated video, which allows the model to focus on one event at a time. To enable time-aware interactions between event captions and video tokens, we design a time-based positional encoding method, dubbed ReRoPE. This encoding helps to guide the cross-attention operation. By fine-tuning a pre-trained video diffusion transformer on temporally grounded data, our approach produces coherent videos with smoothly connected events. For the first time in the literature, our model offers control over the timing of events in generated videos. Extensive experiments demonstrate that MinT outperforms existing open-source models by a large margin.
VIMI: Grounding Video Generation through Multi-modal Instruction
Jul 08, 2024



Existing text-to-video diffusion models rely solely on text-only encoders for their pretraining. This limitation stems from the absence of large-scale multimodal prompt video datasets, resulting in a lack of visual grounding and restricting their versatility and application in multimodal integration. To address this, we construct a large-scale multimodal prompt dataset by employing retrieval methods to pair in-context examples with the given text prompts and then utilize a two-stage training strategy to enable diverse video generation tasks within the same model. In the first stage, we propose a multimodal conditional video generation framework for pretraining on these augmented datasets, establishing a foundational model for grounded video generation. Secondly, we finetune the model from the first stage on three video generation tasks, incorporating multi-modal instructions. This process further refines the model's ability to handle diverse inputs and tasks, ensuring seamless integration of multi-modal information. After this two-stage train-ing process, VIMI demonstrates multimodal understanding capabilities, producing contextually rich and personalized videos grounded in the provided inputs, as shown in Figure 1. Compared to previous visual grounded video generation methods, VIMI can synthesize consistent and temporally coherent videos with large motion while retaining the semantic control. Lastly, VIMI also achieves state-of-the-art text-to-video generation results on UCF101 benchmark.
VIA: A Spatiotemporal Video Adaptation Framework for Global and Local Video Editing
Jun 18, 2024



Video editing stands as a cornerstone of digital media, from entertainment and education to professional communication. However, previous methods often overlook the necessity of comprehensively understanding both global and local contexts, leading to inaccurate and inconsistency edits in the spatiotemporal dimension, especially for long videos. In this paper, we introduce VIA, a unified spatiotemporal VIdeo Adaptation framework for global and local video editing, pushing the limits of consistently editing minute-long videos. First, to ensure local consistency within individual frames, the foundation of VIA is a novel test-time editing adaptation method, which adapts a pre-trained image editing model for improving consistency between potential editing directions and the text instruction, and adapts masked latent variables for precise local control. Furthermore, to maintain global consistency over the video sequence, we introduce spatiotemporal adaptation that adapts consistent attention variables in key frames and strategically applies them across the whole sequence to realize the editing effects. Extensive experiments demonstrate that, compared to baseline methods, our VIA approach produces edits that are more faithful to the source videos, more coherent in the spatiotemporal context, and more precise in local control. More importantly, we show that VIA can achieve consistent long video editing in minutes, unlocking the potentials for advanced video editing tasks over long video sequences.
MoA: Mixture-of-Attention for Subject-Context Disentanglement in Personalized Image Generation
Apr 17, 2024We introduce a new architecture for personalization of text-to-image diffusion models, coined Mixture-of-Attention (MoA). Inspired by the Mixture-of-Experts mechanism utilized in large language models (LLMs), MoA distributes the generation workload between two attention pathways: a personalized branch and a non-personalized prior branch. MoA is designed to retain the original model's prior by fixing its attention layers in the prior branch, while minimally intervening in the generation process with the personalized branch that learns to embed subjects in the layout and context generated by the prior branch. A novel routing mechanism manages the distribution of pixels in each layer across these branches to optimize the blend of personalized and generic content creation. Once trained, MoA facilitates the creation of high-quality, personalized images featuring multiple subjects with compositions and interactions as diverse as those generated by the original model. Crucially, MoA enhances the distinction between the model's pre-existing capability and the newly augmented personalized intervention, thereby offering a more disentangled subject-context control that was previously unattainable. Project page: https://snap-research.github.io/mixture-of-attention
Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
Feb 29, 2024



The quality of the data and annotation upper-bounds the quality of a downstream model. While there exist large text corpora and image-text pairs, high-quality video-text data is much harder to collect. First of all, manual labeling is more time-consuming, as it requires an annotator to watch an entire video. Second, videos have a temporal dimension, consisting of several scenes stacked together, and showing multiple actions. Accordingly, to establish a video dataset with high-quality captions, we propose an automatic approach leveraging multimodal inputs, such as textual video description, subtitles, and individual video frames. Specifically, we curate 3.8M high-resolution videos from the publicly available HD-VILA-100M dataset. We then split them into semantically consistent video clips, and apply multiple cross-modality teacher models to obtain captions for each video. Next, we finetune a retrieval model on a small subset where the best caption of each video is manually selected and then employ the model in the whole dataset to select the best caption as the annotation. In this way, we get 70M videos paired with high-quality text captions. We dub the dataset as Panda-70M. We show the value of the proposed dataset on three downstream tasks: video captioning, video and text retrieval, and text-driven video generation. The models trained on the proposed data score substantially better on the majority of metrics across all the tasks.
Evaluating Very Long-Term Conversational Memory of LLM Agents
Feb 27, 2024Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in long-context large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very long-term dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LoCoMo, a dataset of very long-term conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LoCoMo, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks. Our experimental results indicate that LLMs exhibit challenges in understanding lengthy conversations and comprehending long-range temporal and causal dynamics within dialogues. Employing strategies like long-context LLMs or RAG can offer improvements but these models still substantially lag behind human performance.
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis
Feb 22, 2024



Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net - a workhorse behind image generation - scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods. See our website at https://snap-research.github.io/snapvideo/.
AToM: Amortized Text-to-Mesh using 2D Diffusion
Feb 01, 2024We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail time-consuming per-prompt optimization and commonly output representations other than polygonal meshes, AToM directly generates high-quality textured meshes in less than 1 second with around 10 times reduction in the training cost, and generalizes to unseen prompts. Our key idea is a novel triplane-based text-to-mesh architecture with a two-stage amortized optimization strategy that ensures stable training and enables scalability. Through extensive experiments on various prompt benchmarks, AToM significantly outperforms state-of-the-art amortized approaches with over 4 times higher accuracy (in DF415 dataset) and produces more distinguishable and higher-quality 3D outputs. AToM demonstrates strong generalizability, offering finegrained 3D assets for unseen interpolated prompts without further optimization during inference, unlike per-prompt solutions.
PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning
Nov 15, 2023Instruction tuning has remarkably advanced large language models (LLMs) in understanding and responding to diverse human instructions. Despite the success in high-resource languages, its application in lower-resource ones faces challenges due to the imbalanced foundational abilities of LLMs across different languages, stemming from the uneven language distribution in their pre-training data. To tackle this issue, we propose pivot language guided generation (PLUG), an approach that utilizes a high-resource language, primarily English, as the pivot to enhance instruction tuning in lower-resource languages. It trains the model to first process instructions in the pivot language, and then produce responses in the target language. To evaluate our approach, we introduce a benchmark, X-AlpacaEval, of instructions in 4 languages (Chinese, Korean, Italian, and Spanish), each annotated by professional translators. Our approach demonstrates a significant improvement in the instruction-following abilities of LLMs by 29% on average, compared to directly responding in the target language alone. Further experiments validate the versatility of our approach by employing alternative pivot languages beyond English to assist languages where LLMs exhibit lower proficiency.