 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Time: Temporally-Controlled Multi-Event Video Generation
Dec 06, 2024

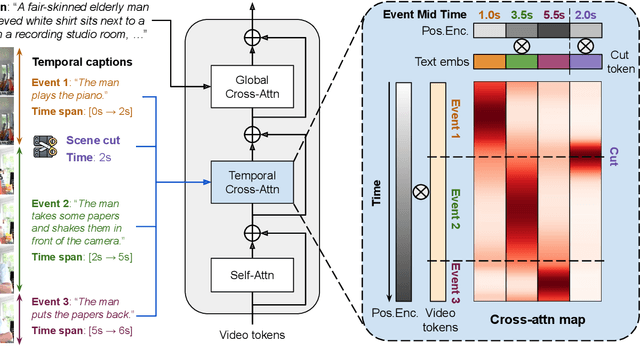
Real-world videos consist of sequences of events. Generating such sequences with precise temporal control is infeasible with existing video generators that rely on a single paragraph of text as input. When tasked with generating multiple events described using a single prompt, such methods often ignore some of the events or fail to arrange them in the correct order. To address this limitation, we present MinT, a multi-event video generator with temporal control. Our key insight is to bind each event to a specific period in the generated video, which allows the model to focus on one event at a time. To enable time-aware interactions between event captions and video tokens, we design a time-based positional encoding method, dubbed ReRoPE. This encoding helps to guide the cross-attention operation. By fine-tuning a pre-trained video diffusion transformer on temporally grounded data, our approach produces coherent videos with smoothly connected events. For the first time in the literature, our model offers control over the timing of events in generated videos. Extensive experiments demonstrate that MinT outperforms existing open-source models by a large margin.
STRIVE: Scene Text Replacement In Videos
Sep 06, 2021
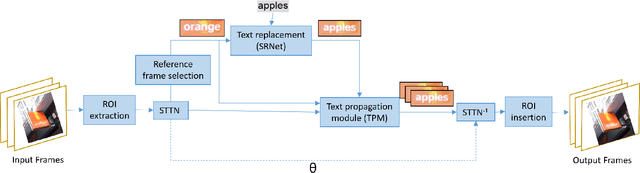
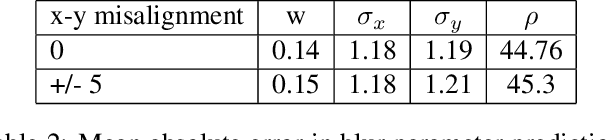
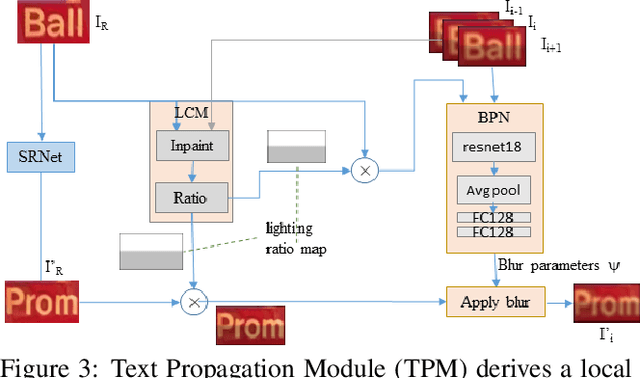
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
Large Scale Multimodal Classification Using an Ensemble of Transformer Models and Co-Attention
Nov 23, 2020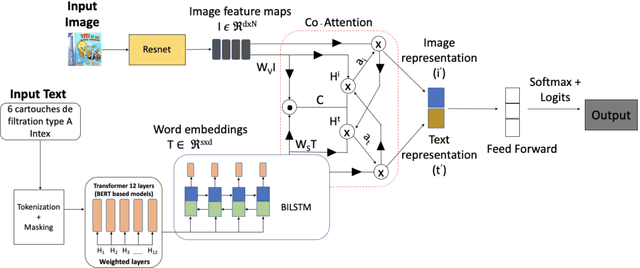


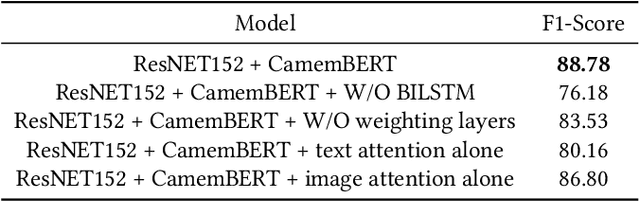
Accurate and efficient product classification is significant for E-commerce applications, as it enables various downstream tasks such as recommendation, retrieval, and pricing. Items often contain textual and visual information, and utilizing both modalities usually outperforms classification utilizing either mode alone. In this paper we describe our methodology and results for the SIGIR eCom Rakuten Data Challenge. We employ a dual attention technique to model image-text relationships using pretrained language and image embeddings. While dual attention has been widely used for Visual Question Answering(VQA) tasks, ours is the first attempt to apply the concept for multimodal classification.