 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Mar 25, 2025
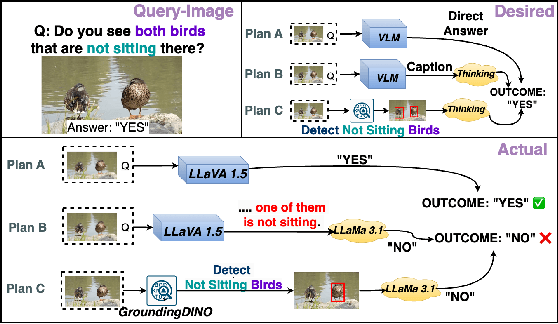
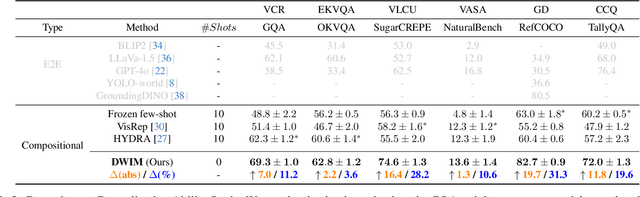
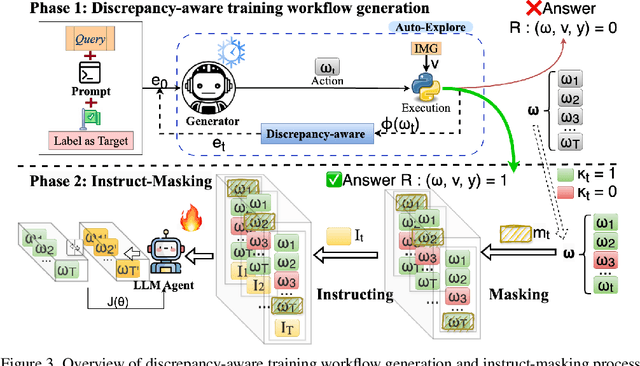
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
LLM-Assist: Enhancing Closed-Loop Planning with Language-Based Reasoning
Dec 30, 2023Although planning is a crucial component of the autonomous driving stack, researchers have yet to develop robust planning algorithms that are capable of safely handling the diverse range of possible driving scenarios. Learning-based planners suffer from overfitting and poor long-tail performance. On the other hand, rule-based planners generalize well, but might fail to handle scenarios that require complex driving maneuvers. To address these limitations, we investigate the possibility of leveraging the common-sense reasoning capabilities of Large Language Models (LLMs) such as GPT4 and Llama2 to generate plans for self-driving vehicles. In particular, we develop a novel hybrid planner that leverages a conventional rule-based planner in conjunction with an LLM-based planner. Guided by commonsense reasoning abilities of LLMs, our approach navigates complex scenarios which existing planners struggle with, produces well-reasoned outputs while also remaining grounded through working alongside the rule-based approach. Through extensive evaluation on the nuPlan benchmark, we achieve state-of-the-art performance, outperforming all existing pure learning- and rule-based methods across most metrics. Our code will be available at https://llmassist.github.io.
DP-Mix: Mixup-based Data Augmentation for Differentially Private Learning
Nov 02, 2023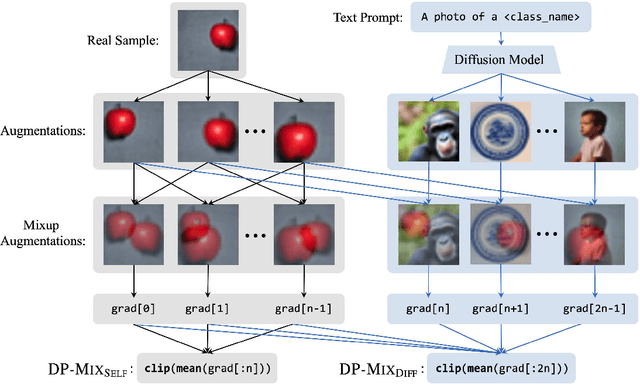

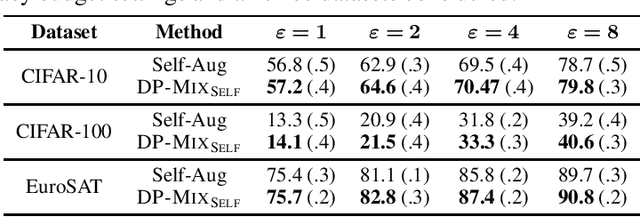
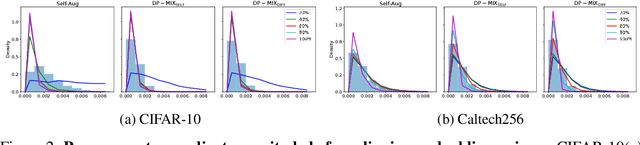
Data augmentation techniques, such as simple image transformations and combinations, are highly effective at improving the generalization of computer vision models, especially when training data is limited. However, such techniques are fundamentally incompatible with differentially private learning approaches, due to the latter's built-in assumption that each training image's contribution to the learned model is bounded. In this paper, we investigate why naive applications of multi-sample data augmentation techniques, such as mixup, fail to achieve good performance and propose two novel data augmentation techniques specifically designed for the constraints of differentially private learning. Our first technique, DP-Mix_Self, achieves SoTA classification performance across a range of datasets and settings by performing mixup on self-augmented data. Our second technique, DP-Mix_Diff, further improves performance by incorporating synthetic data from a pre-trained diffusion model into the mixup process. We open-source the code at https://github.com/wenxuan-Bao/DP-Mix.
OmniLabel: A Challenging Benchmark for Language-Based Object Detection
Apr 22, 2023



Language-based object detection is a promising direction towards building a natural interface to describe objects in images that goes far beyond plain category names. While recent methods show great progress in that direction, proper evaluation is lacking. With OmniLabel, we propose a novel task definition, dataset, and evaluation metric. The task subsumes standard- and open-vocabulary detection as well as referring expressions. With more than 28K unique object descriptions on over 25K images, OmniLabel provides a challenging benchmark with diverse and complex object descriptions in a naturally open-vocabulary setting. Moreover, a key differentiation to existing benchmarks is that our object descriptions can refer to one, multiple or even no object, hence, providing negative examples in free-form text. The proposed evaluation handles the large label space and judges performance via a modified average precision metric, which we validate by evaluating strong language-based baselines. OmniLabel indeed provides a challenging test bed for future research on language-based detection.
STRIVE: Scene Text Replacement In Videos
Sep 06, 2021
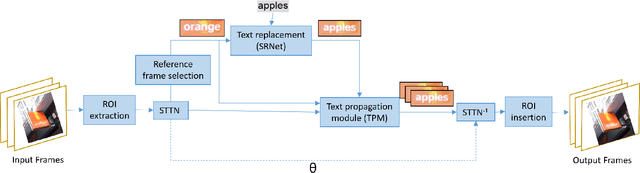
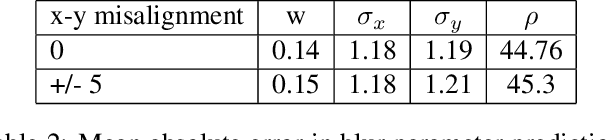
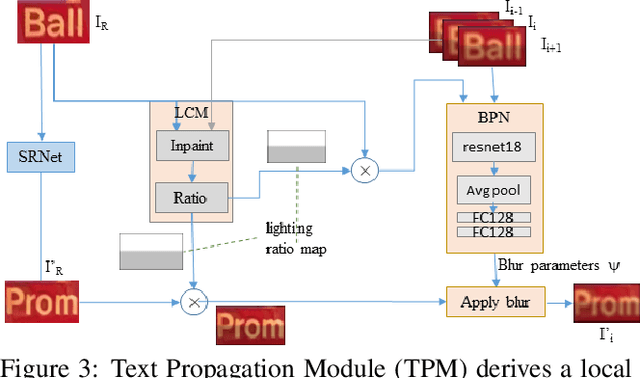
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
Bayesian Semantic Instance Segmentation in Open Set World
Jul 30, 2018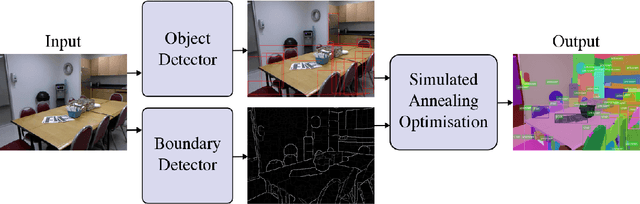
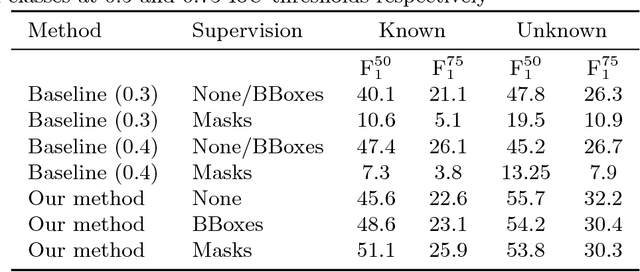


This paper addresses the semantic instance segmentation task in the open-set conditions, where input images can contain known and unknown object classes. The training process of existing semantic instance segmentation methods requires annotation masks for all object instances, which is expensive to acquire or even infeasible in some realistic scenarios, where the number of categories may increase boundlessly. In this paper, we present a novel open-set semantic instance segmentation approach capable of segmenting all known and unknown object classes in images, based on the output of an object detector trained on known object classes. We formulate the problem using a Bayesian framework, where the posterior distribution is approximated with a simulated annealing optimization equipped with an efficient image partition sampler. We show empirically that our method is competitive with state-of-the-art supervised methods on known classes, but also performs well on unknown classes when compared with unsupervised methods.
DeepSetNet: Predicting Sets with Deep Neural Networks
Aug 11, 2017
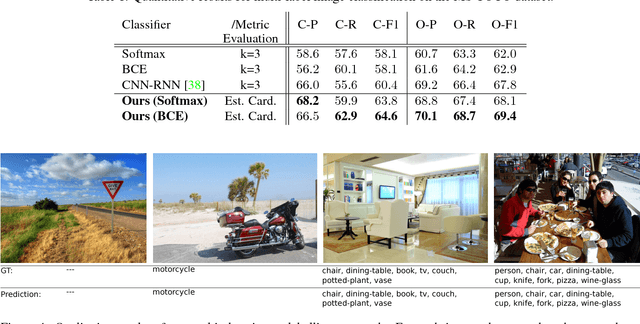
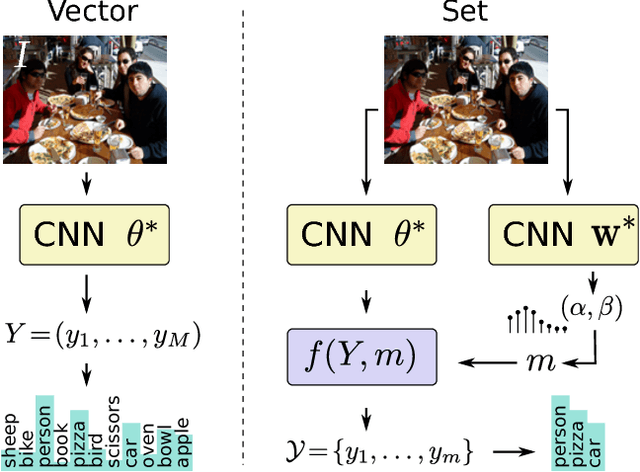

This paper addresses the task of set prediction using deep learning. This is important because the output of many computer vision tasks, including image tagging and object detection, are naturally expressed as sets of entities rather than vectors. As opposed to a vector, the size of a set is not fixed in advance, and it is invariant to the ordering of entities within it. We define a likelihood for a set distribution and learn its parameters using a deep neural network. We also derive a loss for predicting a discrete distribution corresponding to set cardinality. Set prediction is demonstrated on the problem of multi-class image classification. Moreover, we show that the proposed cardinality loss can also trivially be applied to the tasks of object counting and pedestrian detection. Our approach outperforms existing methods in all three cases on standard datasets.
Smart Mining for Deep Metric Learning
Jul 27, 2017
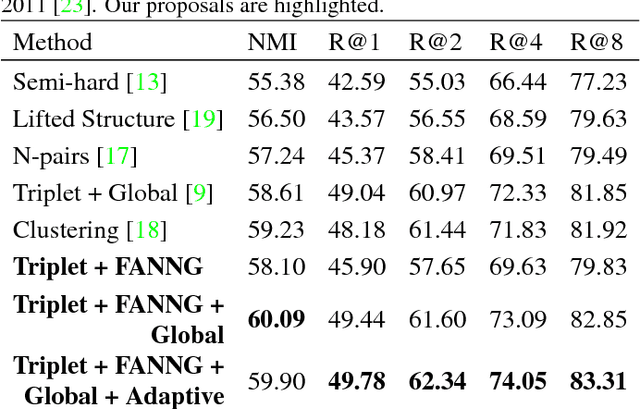
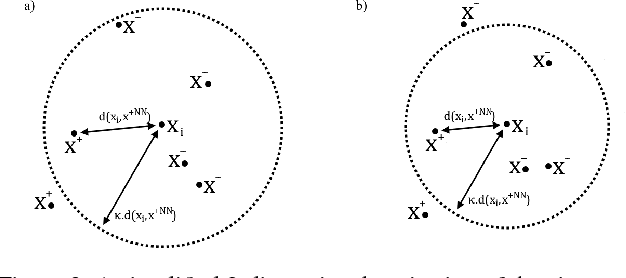
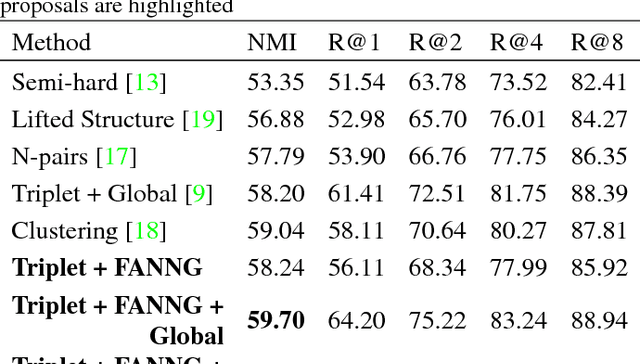
To solve deep metric learning problems and producing feature embeddings, current methodologies will commonly use a triplet model to minimise the relative distance between samples from the same class and maximise the relative distance between samples from different classes. Though successful, the training convergence of this triplet model can be compromised by the fact that the vast majority of the training samples will produce gradients with magnitudes that are close to zero. This issue has motivated the development of methods that explore the global structure of the embedding and other methods that explore hard negative/positive mining. The effectiveness of such mining methods is often associated with intractable computational requirements. In this paper, we propose a novel deep metric learning method that combines the triplet model and the global structure of the embedding space. We rely on a smart mining procedure that produces effective training samples for a low computational cost. In addition, we propose an adaptive controller that automatically adjusts the smart mining hyper-parameters and speeds up the convergence of the training process. We show empirically that our proposed method allows for fast and more accurate training of triplet ConvNets than other competing mining methods. Additionally, we show that our method achieves new state-of-the-art embedding results for CUB-200-2011 and Cars196 datasets.
Learning Local Image Descriptors with Deep Siamese and Triplet Convolutional Networks by Minimising Global Loss Functions
Aug 01, 2016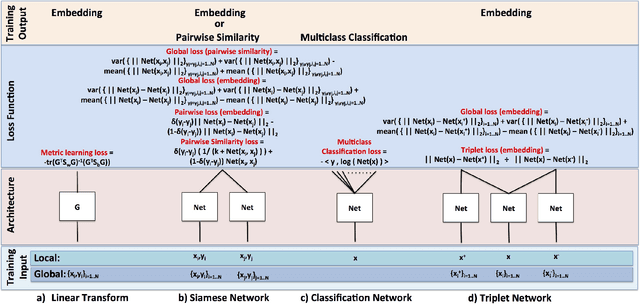
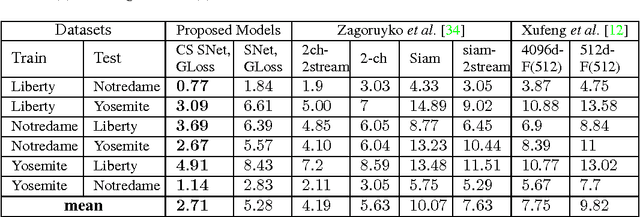
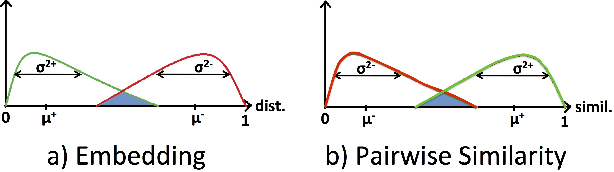

Recent innovations in training deep convolutional neural network (ConvNet) models have motivated the design of new methods to automatically learn local image descriptors. The latest deep ConvNets proposed for this task consist of a siamese network that is trained by penalising misclassification of pairs of local image patches. Current results from machine learning show that replacing this siamese by a triplet network can improve the classification accuracy in several problems, but this has yet to be demonstrated for local image descriptor learning. Moreover, current siamese and triplet networks have been trained with stochastic gradient descent that computes the gradient from individual pairs or triplets of local image patches, which can make them prone to overfitting. In this paper, we first propose the use of triplet networks for the problem of local image descriptor learning. Furthermore, we also propose the use of a global loss that minimises the overall classification error in the training set, which can improve the generalisation capability of the model. Using the UBC benchmark dataset for comparing local image descriptors, we show that the triplet network produces a more accurate embedding than the siamese network in terms of the UBC dataset errors. Moreover, we also demonstrate that a combination of the triplet and global losses produces the best embedding in the field, using this triplet network. Finally, we also show that the use of the central-surround siamese network trained with the global loss produces the best result of the field on the UBC dataset. Pre-trained models are available online at https://github.com/vijaykbg/deep-patchmatch