 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Executable Functional Abstractions: Inferring Generative Programs for Advanced Math Problems
Apr 14, 2025Scientists often infer abstract procedures from specific instances of problems and use the abstractions to generate new, related instances. For example, programs encoding the formal rules and properties of a system have been useful in fields ranging from RL (procedural environments) to physics (simulation engines). These programs can be seen as functions which execute to different outputs based on their parameterizations (e.g., gridworld configuration or initial physical conditions). We introduce the term EFA (Executable Functional Abstraction) to denote such programs for math problems. EFA-like constructs have been shown to be useful for math reasoning as problem generators for stress-testing models. However, prior work has been limited to abstractions for grade-school math (whose simple rules are easy to encode in programs), while generating EFAs for advanced math has thus far required human engineering. We explore the automatic construction of EFAs for advanced math problems. We operationalize the task of automatically constructing EFAs as a program synthesis task, and develop EFAGen, which conditions an LLM on a seed math problem and its step-by-step solution to generate candidate EFA programs that are faithful to the generalized problem and solution class underlying the seed problem. Furthermore, we formalize properties any valid EFA must possess in terms of executable unit tests, and show how the tests can be used as verifiable rewards to train LLMs to become better writers of EFAs. We demonstrate that EFAs constructed by EFAGen behave rationally by remaining faithful to seed problems, produce learnable problem variations, and that EFAGen can infer EFAs across multiple diverse sources of competition-level math problems. Finally, we show downstream uses of model-written EFAs e.g. finding problem variations that are harder or easier for a learner to solve, as well as data generation.
DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Mar 25, 2025
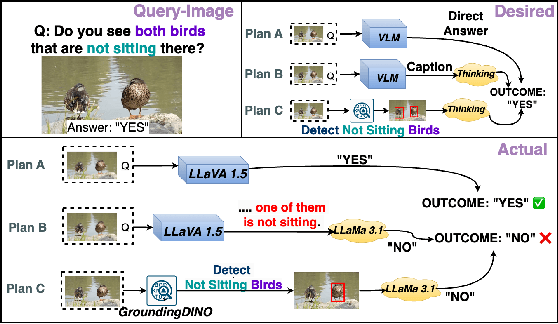
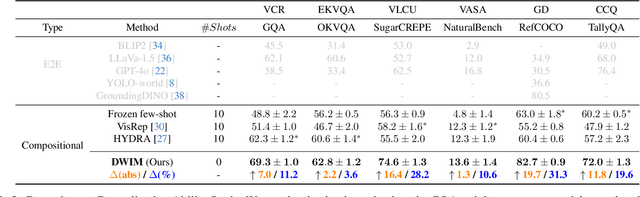
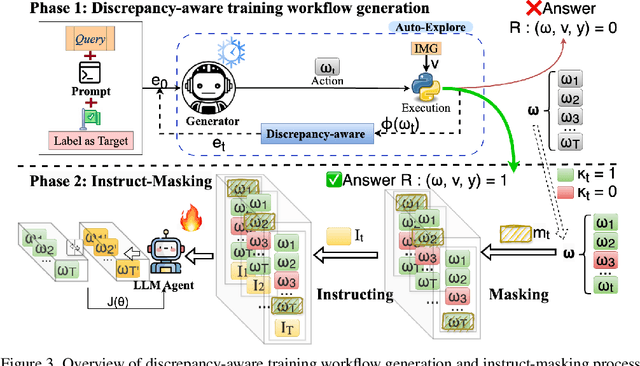
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
MutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
Feb 21, 2025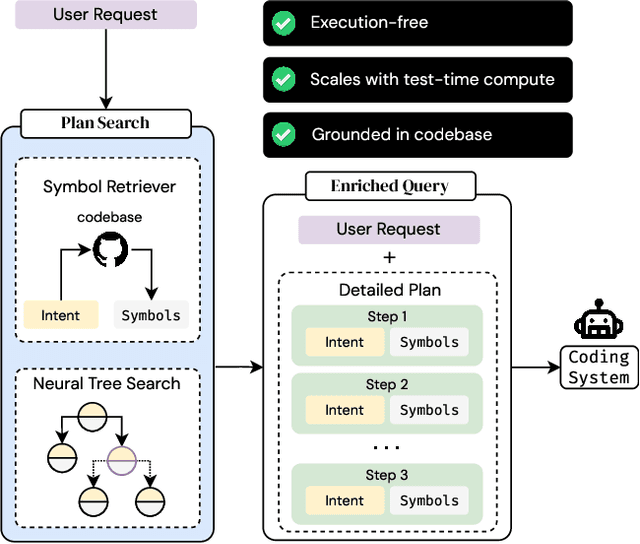



When a human requests an LLM to complete a coding task using functionality from a large code repository, how do we provide context from the repo to the LLM? One approach is to add the entire repo to the LLM's context window. However, most tasks involve only fraction of symbols from a repo, longer contexts are detrimental to the LLM's reasoning abilities, and context windows are not unlimited. Alternatively, we could emulate the human ability to navigate a large repo, pick out the right functionality, and form a plan to solve the task. We propose MutaGReP (Mutation-guided Grounded Repository Plan Search), an approach to search for plans that decompose a user request into natural language steps grounded in the codebase. MutaGReP performs neural tree search in plan space, exploring by mutating plans and using a symbol retriever for grounding. On the challenging LongCodeArena benchmark, our plans use less than 5% of the 128K context window for GPT-4o but rival the coding performance of GPT-4o with a context window filled with the repo. Plans produced by MutaGReP allow Qwen 2.5 Coder 32B and 72B to match the performance of GPT-4o with full repo context and enable progress on the hardest LongCodeArena tasks. Project page: zaidkhan.me/MutaGReP
Learning to Generate Unit Tests for Automated Debugging
Feb 03, 2025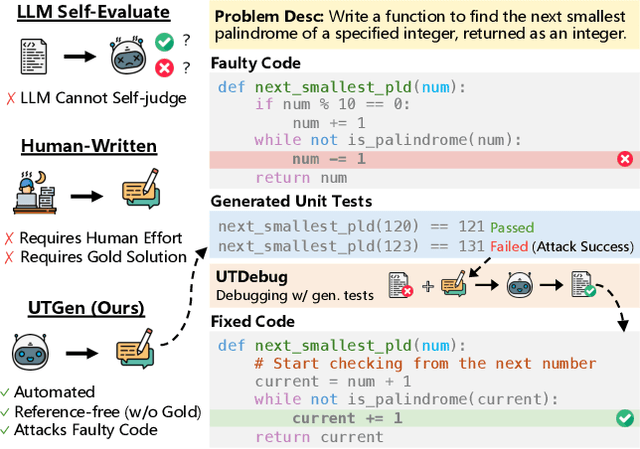

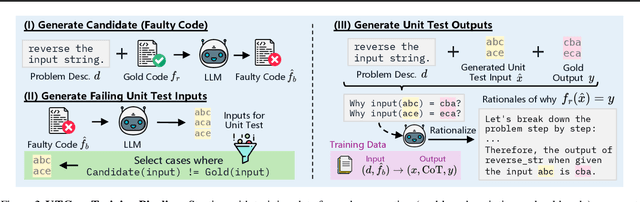

Unit tests (UTs) play an instrumental role in assessing code correctness as well as providing feedback to a large language model (LLM) as it iteratively debugs faulty code, motivating automated test generation. However, we uncover a trade-off between generating unit test inputs that reveal errors when given a faulty code and correctly predicting the unit test output without access to the gold solution. To address this trade-off, we propose UTGen, which teaches LLMs to generate unit test inputs that reveal errors along with their correct expected outputs based on task descriptions and candidate code. We integrate UTGen into UTDebug, a robust debugging pipeline that uses generated tests to help LLMs debug effectively. Since model-generated tests can provide noisy signals (e.g., from incorrectly predicted outputs), UTDebug (i) scales UTGen via test-time compute to improve UT output prediction, and (ii) validates and back-tracks edits based on multiple generated UTs to avoid overfitting. We show that UTGen outperforms UT generation baselines by 7.59% based on a metric measuring the presence of both error-revealing UT inputs and correct UT outputs. When used with UTDebug, we find that feedback from UTGen's unit tests improves pass@1 accuracy of Qwen-2.5 7B on HumanEvalFix and our own harder debugging split of MBPP+ by over 3% and 12.35% (respectively) over other LLM-based UT generation baselines.
DataEnvGym: Data Generation Agents in Teacher Environments with Student Feedback
Oct 08, 2024The process of creating training data to teach models is currently driven by humans, who manually analyze model weaknesses and plan how to create data that improves a student model. Recent approaches using LLMs as annotators reduce human effort, but still require humans to interpret feedback from evaluations and control the LLM to produce data the student needs. Automating this labor-intensive process by creating autonomous data generation agents - or teachers - is desirable, but requires environments that can simulate the feedback-driven, iterative, closed loop of data creation. To enable rapid and scalable testing for such agents and their modules, we introduce DataEnvGym, a testbed of teacher environments for data generation agents. DataEnvGym frames data generation as a sequential decision-making task, involving an agent consisting of a data generation policy (which generates a plan for creating training data) and a data generation engine (which transforms the plan into data), inside an environment that provides student feedback. The agent's goal is to improve student performance. Students are iteratively trained and evaluated on generated data, with their feedback (in the form of errors or weak skills) being reported to the agent after each iteration. DataEnvGym includes multiple teacher environment instantiations across 3 levels of structure in the state representation and action space. More structured environments are based on inferred skills and offer more interpretability and curriculum control. We support 3 diverse tasks (math, code, and VQA) and test multiple students and teachers. Example agents in our teaching environments can iteratively improve students across tasks and settings. Moreover, we show that environments teach different skill levels and test variants of key modules, pointing to future work in improving data generation agents, engines, and feedback mechanisms.
Consistency and Uncertainty: Identifying Unreliable Responses From Black-Box Vision-Language Models for Selective Visual Question Answering
Apr 16, 2024



The goal of selective prediction is to allow an a model to abstain when it may not be able to deliver a reliable prediction, which is important in safety-critical contexts. Existing approaches to selective prediction typically require access to the internals of a model, require retraining a model or study only unimodal models. However, the most powerful models (e.g. GPT-4) are typically only available as black boxes with inaccessible internals, are not retrainable by end-users, and are frequently used for multimodal tasks. We study the possibility of selective prediction for vision-language models in a realistic, black-box setting. We propose using the principle of \textit{neighborhood consistency} to identify unreliable responses from a black-box vision-language model in question answering tasks. We hypothesize that given only a visual question and model response, the consistency of the model's responses over the neighborhood of a visual question will indicate reliability. It is impossible to directly sample neighbors in feature space in a black-box setting. Instead, we show that it is possible to use a smaller proxy model to approximately sample from the neighborhood. We find that neighborhood consistency can be used to identify model responses to visual questions that are likely unreliable, even in adversarial settings or settings that are out-of-distribution to the proxy model.
Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
Apr 06, 2024



Visual program synthesis is a promising approach to exploit the reasoning abilities of large language models for compositional computer vision tasks. Previous work has used few-shot prompting with frozen LLMs to synthesize visual programs. Training an LLM to write better visual programs is an attractive prospect, but it is unclear how to accomplish this. No dataset of visual programs for training exists, and acquisition of a visual program dataset cannot be easily crowdsourced due to the need for expert annotators. To get around the lack of direct supervision, we explore improving the program synthesis abilities of an LLM using feedback from interactive experience. We propose a method where we exploit existing annotations for a vision-language task to improvise a coarse reward signal for that task, treat the LLM as a policy, and apply reinforced self-training to improve the visual program synthesis ability of the LLM for that task. We describe a series of experiments on object detection, compositional visual question answering, and image-text retrieval, and show that in each case, the self-trained LLM outperforms or performs on par with few-shot frozen LLMs that are an order of magnitude larger. Website: https://zaidkhan.me/ViReP
Exploring Question Decomposition for Zero-Shot VQA
Oct 25, 2023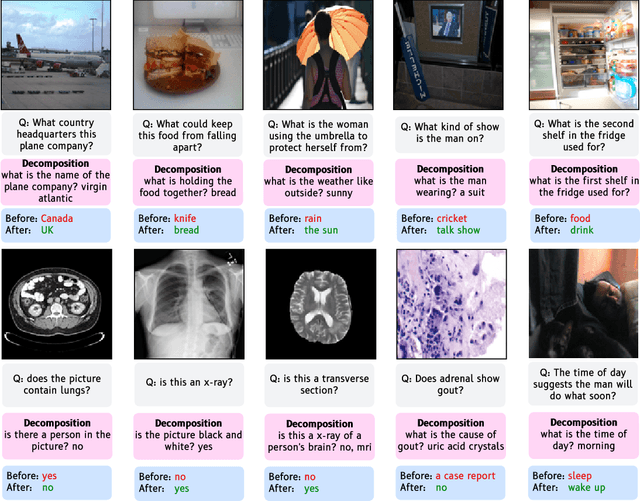
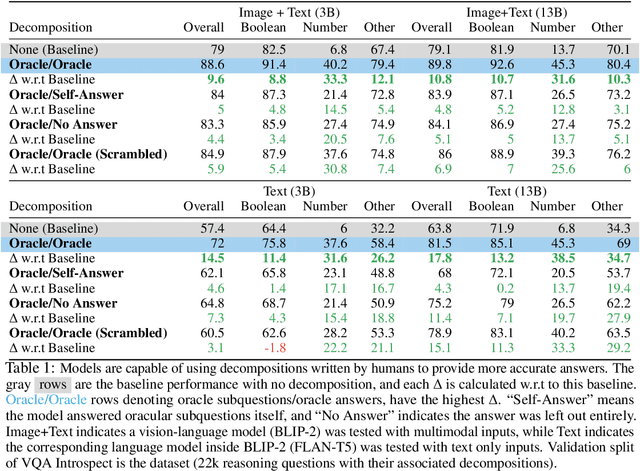
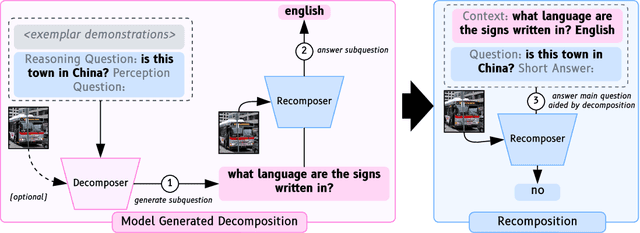
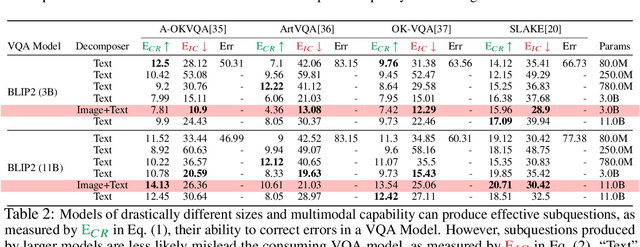
Visual question answering (VQA) has traditionally been treated as a single-step task where each question receives the same amount of effort, unlike natural human question-answering strategies. We explore a question decomposition strategy for VQA to overcome this limitation. We probe the ability of recently developed large vision-language models to use human-written decompositions and produce their own decompositions of visual questions, finding they are capable of learning both tasks from demonstrations alone. However, we show that naive application of model-written decompositions can hurt performance. We introduce a model-driven selective decomposition approach for second-guessing predictions and correcting errors, and validate its effectiveness on eight VQA tasks across three domains, showing consistent improvements in accuracy, including improvements of >20% on medical VQA datasets and boosting the zero-shot performance of BLIP-2 above chance on a VQA reformulation of the challenging Winoground task. Project Site: https://zaidkhan.me/decomposition-0shot-vqa/
Q: How to Specialize Large Vision-Language Models to Data-Scarce VQA Tasks? A: Self-Train on Unlabeled Images!
Jun 06, 2023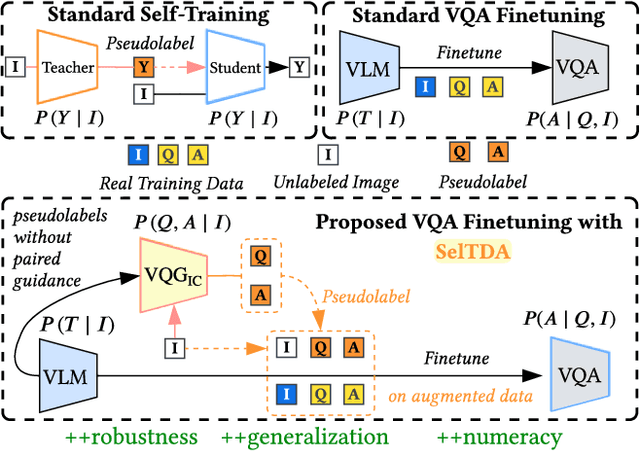
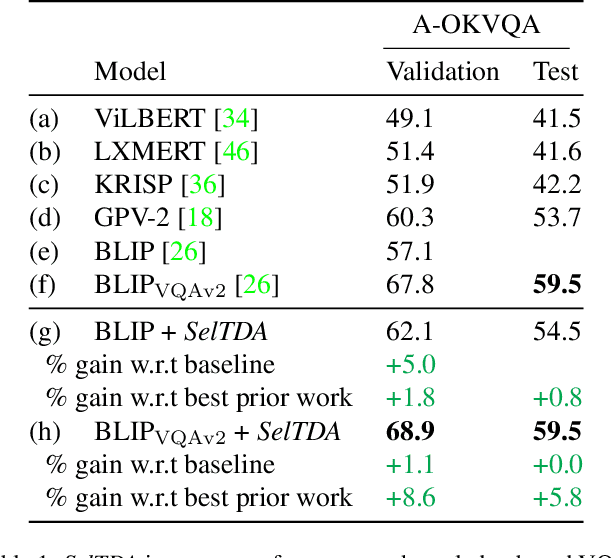
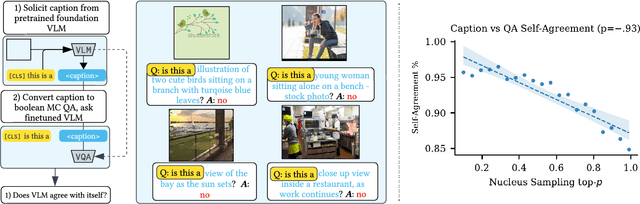
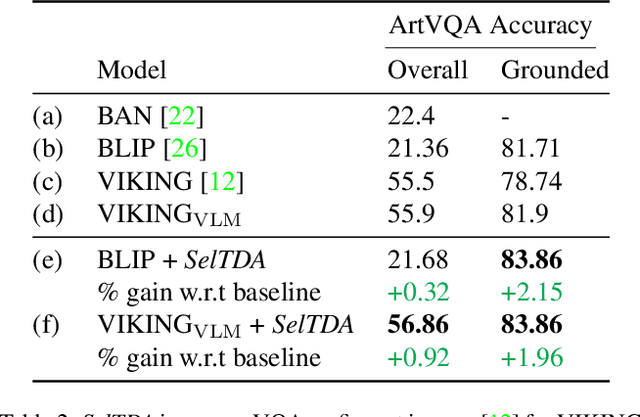
Finetuning a large vision language model (VLM) on a target dataset after large scale pretraining is a dominant paradigm in visual question answering (VQA). Datasets for specialized tasks such as knowledge-based VQA or VQA in non natural-image domains are orders of magnitude smaller than those for general-purpose VQA. While collecting additional labels for specialized tasks or domains can be challenging, unlabeled images are often available. We introduce SelTDA (Self-Taught Data Augmentation), a strategy for finetuning large VLMs on small-scale VQA datasets. SelTDA uses the VLM and target dataset to build a teacher model that can generate question-answer pseudolabels directly conditioned on an image alone, allowing us to pseudolabel unlabeled images. SelTDA then finetunes the initial VLM on the original dataset augmented with freshly pseudolabeled images. We describe a series of experiments showing that our self-taught data augmentation increases robustness to adversarially searched questions, counterfactual examples and rephrasings, improves domain generalization, and results in greater retention of numerical reasoning skills. The proposed strategy requires no additional annotations or architectural modifications, and is compatible with any modern encoder-decoder multimodal transformer. Code available at https://github.com/codezakh/SelTDA.