 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATA: A Trainable Hierarchical Automaton System for Multi-Agent Visual Reasoning
Jan 27, 2026Recent vision-language models have strong perceptual ability but their implicit reasoning is hard to explain and easily generates hallucinations on complex queries. Compositional methods improve interpretability, but most rely on a single agent or hand-crafted pipeline and cannot decide when to collaborate across complementary agents or compete among overlapping ones. We introduce MATA (Multi-Agent hierarchical Trainable Automaton), a multi-agent system presented as a hierarchical finite-state automaton for visual reasoning whose top-level transitions are chosen by a trainable hyper agent. Each agent corresponds to a state in the hyper automaton, and runs a small rule-based sub-automaton for reliable micro-control. All agents read and write a shared memory, yielding transparent execution history. To supervise the hyper agent's transition policy, we build transition-trajectory trees and transform to memory-to-next-state pairs, forming the MATA-SFT-90K dataset for supervised finetuning (SFT). The finetuned LLM as the transition policy understands the query and the capacity of agents, and it can efficiently choose the optimal agent to solve the task. Across multiple visual reasoning benchmarks, MATA achieves the state-of-the-art results compared with monolithic and compositional baselines. The code and dataset are available at https://github.com/ControlNet/MATA.
DexAvatar: 3D Sign Language Reconstruction with Hand and Body Pose Priors
Dec 24, 2025



The trend in sign language generation is centered around data-driven generative methods that require vast amounts of precise 2D and 3D human pose data to achieve an acceptable generation quality. However, currently, most sign language datasets are video-based and limited to automatically reconstructed 2D human poses (i.e., keypoints) and lack accurate 3D information. Furthermore, existing state-of-the-art for automatic 3D human pose estimation from sign language videos is prone to self-occlusion, noise, and motion blur effects, resulting in poor reconstruction quality. In response to this, we introduce DexAvatar, a novel framework to reconstruct bio-mechanically accurate fine-grained hand articulations and body movements from in-the-wild monocular sign language videos, guided by learned 3D hand and body priors. DexAvatar achieves strong performance in the SGNify motion capture dataset, the only benchmark available for this task, reaching an improvement of 35.11% in the estimation of body and hand poses compared to the state-of-the-art. The official website of this work is: https://github.com/kaustesseract/DexAvatar.
Do Blind Spots Matter for Word-Referent Mapping? A Computational Study with Infant Egocentric Video
Nov 13, 2025
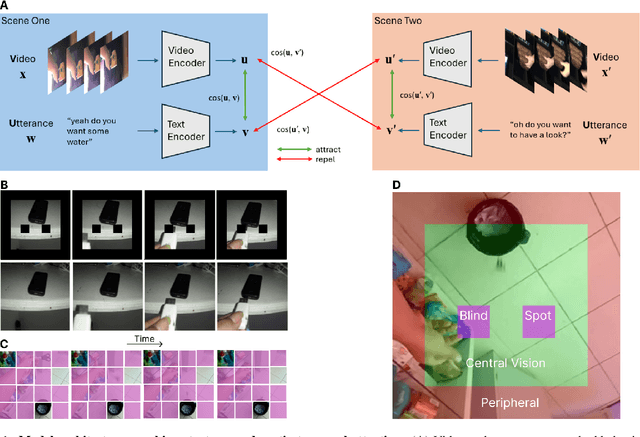


Typically, children start to learn their first words between 6 and 9 months, linking spoken utterances to their visual referents. Without prior knowledge, a word encountered for the first time can be interpreted in countless ways; it might refer to any of the objects in the environment, their components, or attributes. Using longitudinal, egocentric, and ecologically valid data from the experience of one child, in this work, we propose a self-supervised and biologically plausible strategy to learn strong visual representations. Our masked autoencoder-based visual backbone incorporates knowledge about the blind spot in human eyes to define a novel masking strategy. This mask and reconstruct approach attempts to mimic the way the human brain fills the gaps in the eyes' field of view. This represents a significant shift from standard random masking strategies, which are difficult to justify from a biological perspective. The pretrained encoder is utilized in a contrastive learning-based video-text model capable of acquiring word-referent mappings. Extensive evaluation suggests that the proposed biologically plausible masking strategy is at least as effective as random masking for learning word-referent mappings from cross-situational and temporally extended episodes.
Explain Before You Answer: A Survey on Compositional Visual Reasoning
Aug 24, 2025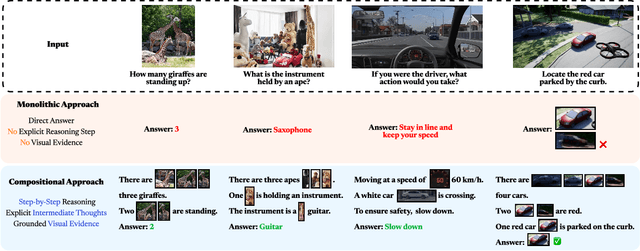
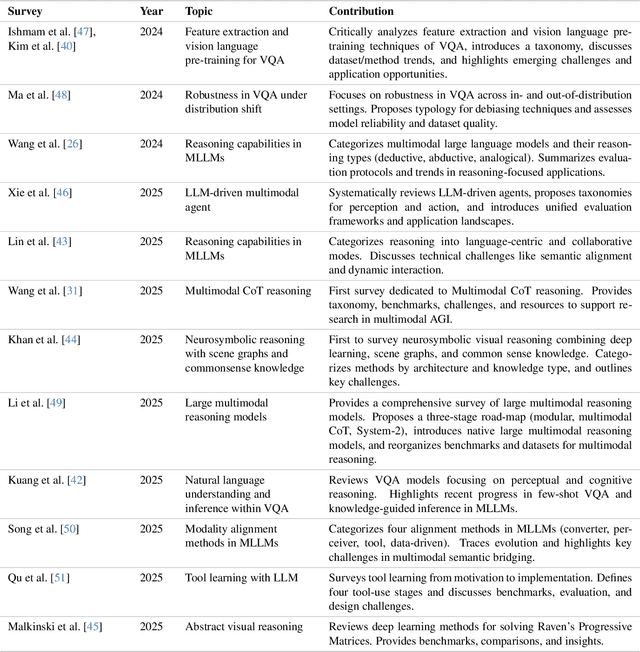
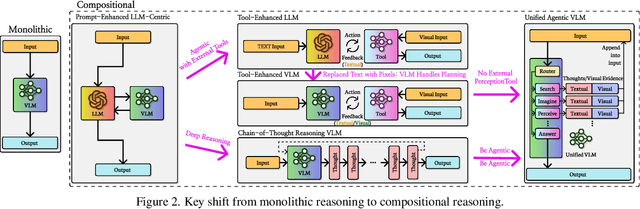
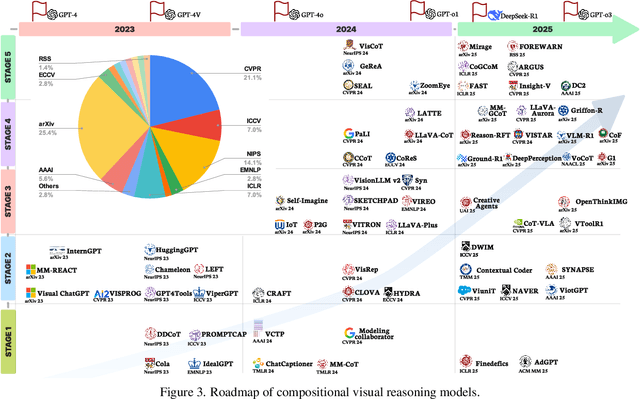
Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
JRDB-Reasoning: A Difficulty-Graded Benchmark for Visual Reasoning in Robotics
Aug 14, 2025Recent advances in Vision-Language Models (VLMs) and large language models (LLMs) have greatly enhanced visual reasoning, a key capability for embodied AI agents like robots. However, existing visual reasoning benchmarks often suffer from several limitations: they lack a clear definition of reasoning complexity, offer have no control to generate questions over varying difficulty and task customization, and fail to provide structured, step-by-step reasoning annotations (workflows). To bridge these gaps, we formalize reasoning complexity, introduce an adaptive query engine that generates customizable questions of varying complexity with detailed intermediate annotations, and extend the JRDB dataset with human-object interaction and geometric relationship annotations to create JRDB-Reasoning, a benchmark tailored for visual reasoning in human-crowded environments. Our engine and benchmark enable fine-grained evaluation of visual reasoning frameworks and dynamic assessment of visual-language models across reasoning levels.
AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Jul 28, 2025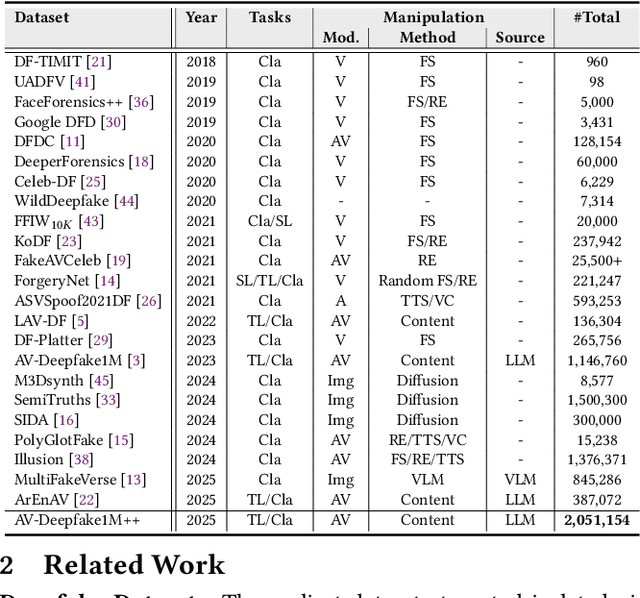
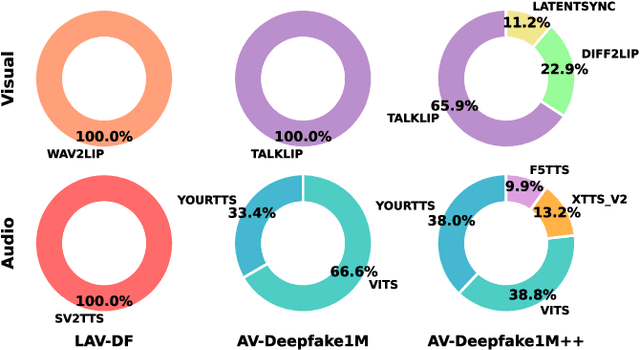
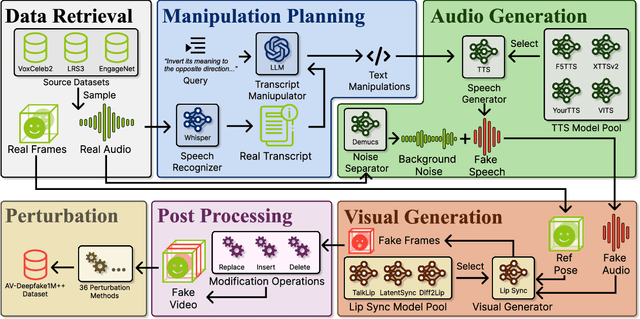
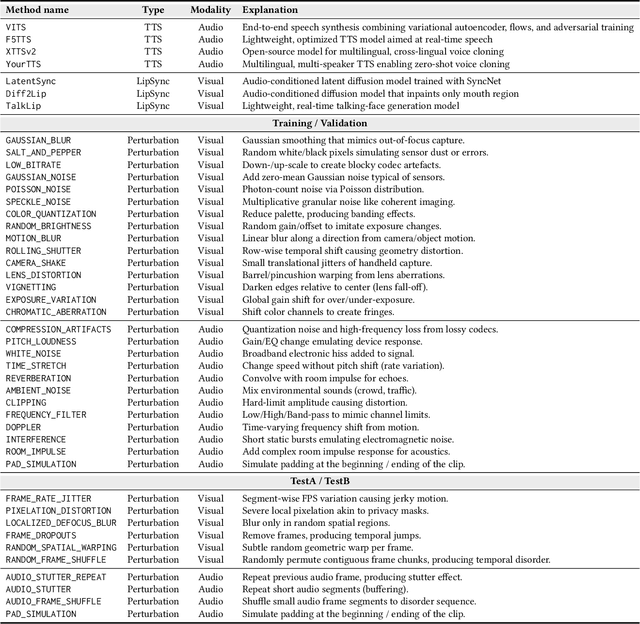
The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
M-MRE: Extending the Mutual Reinforcement Effect to Multimodal Information Extraction
Apr 24, 2025Mutual Reinforcement Effect (MRE) is an emerging subfield at the intersection of information extraction and model interpretability. MRE aims to leverage the mutual understanding between tasks of different granularities, enhancing the performance of both coarse-grained and fine-grained tasks through joint modeling. While MRE has been explored and validated in the textual domain, its applicability to visual and multimodal domains remains unexplored. In this work, we extend MRE to the multimodal information extraction domain for the first time. Specifically, we introduce a new task: Multimodal Mutual Reinforcement Effect (M-MRE), and construct a corresponding dataset to support this task. To address the challenges posed by M-MRE, we further propose a Prompt Format Adapter (PFA) that is fully compatible with various Large Vision-Language Models (LVLMs). Experimental results demonstrate that MRE can also be observed in the M-MRE task, a multimodal text-image understanding scenario. This provides strong evidence that MRE facilitates mutual gains across three interrelated tasks, confirming its generalizability beyond the textual domain.
DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Mar 25, 2025
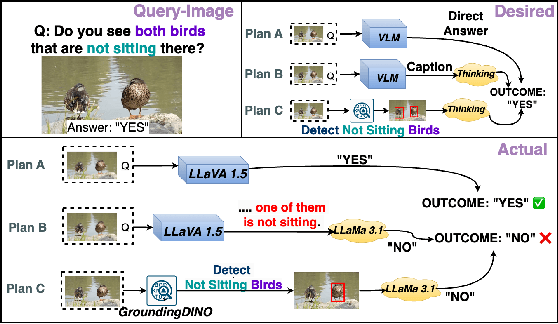
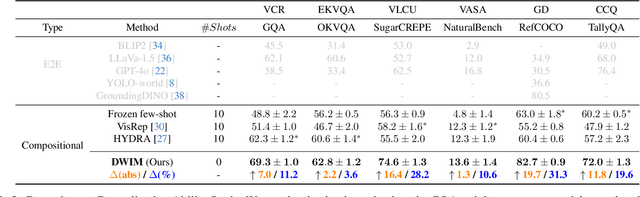
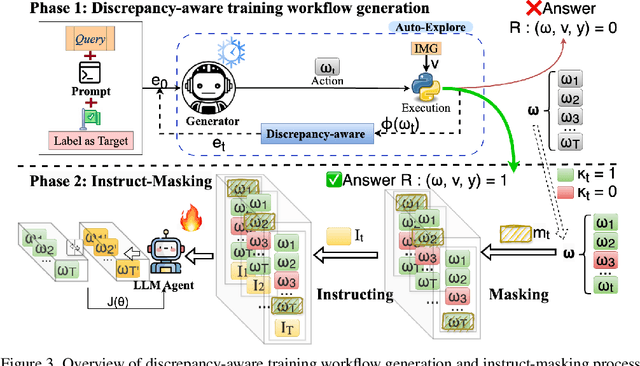
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.
NEUSIS: A Compositional Neuro-Symbolic Framework for Autonomous Perception, Reasoning, and Planning in Complex UAV Search Missions
Sep 16, 2024



This paper addresses the problem of autonomous UAV search missions, where a UAV must locate specific Entities of Interest (EOIs) within a time limit, based on brief descriptions in large, hazard-prone environments with keep-out zones. The UAV must perceive, reason, and make decisions with limited and uncertain information. We propose NEUSIS, a compositional neuro-symbolic system designed for interpretable UAV search and navigation in realistic scenarios. NEUSIS integrates neuro-symbolic visual perception, reasoning, and grounding (GRiD) to process raw sensory inputs, maintains a probabilistic world model for environment representation, and uses a hierarchical planning component (SNaC) for efficient path planning. Experimental results from simulated urban search missions using AirSim and Unreal Engine show that NEUSIS outperforms a state-of-the-art (SOTA) vision-language model and a SOTA search planning model in success rate, search efficiency, and 3D localization. These results demonstrate the effectiveness of our compositional neuro-symbolic approach in handling complex, real-world scenarios, making it a promising solution for autonomous UAV systems in search missions.
1M-Deepfakes Detection Challenge
Sep 11, 2024



The detection and localization of deepfake content, particularly when small fake segments are seamlessly mixed with real videos, remains a significant challenge in the field of digital media security. Based on the recently released AV-Deepfake1M dataset, which contains more than 1 million manipulated videos across more than 2,000 subjects, we introduce the 1M-Deepfakes Detection Challenge. This challenge is designed to engage the research community in developing advanced methods for detecting and localizing deepfake manipulations within the large-scale high-realistic audio-visual dataset. The participants can access the AV-Deepfake1M dataset and are required to submit their inference results for evaluation across the metrics for detection or localization tasks. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection and localization systems. Evaluation scripts, baseline models, and accompanying code will be available on https://github.com/ControlNet/AV-Deepfake1M.