 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Camera Positional Encoding for Controlled Video Generation
Dec 08, 2025Transformers have emerged as a universal backbone across 3D perception, video generation, and world models for autonomous driving and embodied AI, where understanding camera geometry is essential for grounding visual observations in three-dimensional space. However, existing camera encoding methods often rely on simplified pinhole assumptions, restricting generalization across the diverse intrinsics and lens distortions in real-world cameras. We introduce Relative Ray Encoding, a geometry-consistent representation that unifies complete camera information, including 6-DoF poses, intrinsics, and lens distortions. To evaluate its capability under diverse controllability demands, we adopt camera-controlled text-to-video generation as a testbed task. Within this setting, we further identify pitch and roll as two components effective for Absolute Orientation Encoding, enabling full control over the initial camera orientation. Together, these designs form UCPE (Unified Camera Positional Encoding), which integrates into a pretrained video Diffusion Transformer through a lightweight spatial attention adapter, adding less than 1% trainable parameters while achieving state-of-the-art camera controllability and visual fidelity. To facilitate systematic training and evaluation, we construct a large video dataset covering a wide range of camera motions and lens types. Extensive experiments validate the effectiveness of UCPE in camera-controllable video generation and highlight its potential as a general camera representation for Transformers across future multi-view, video, and 3D tasks. Code will be available at https://github.com/chengzhag/UCPE.
Enhancing Vehicle Detection under Adverse Weather Conditions with Contrastive Learning
Sep 26, 2025Aside from common challenges in remote sensing like small, sparse targets and computation cost limitations, detecting vehicles from UAV images in the Nordic regions faces strong visibility challenges and domain shifts caused by diverse levels of snow coverage. Although annotated data are expensive, unannotated data is cheaper to obtain by simply flying the drones. In this work, we proposed a sideload-CL-adaptation framework that enables the use of unannotated data to improve vehicle detection using lightweight models. Specifically, we propose to train a CNN-based representation extractor through contrastive learning on the unannotated data in the pretraining stage, and then sideload it to a frozen YOLO11n backbone in the fine-tuning stage. To find a robust sideload-CL-adaptation, we conducted extensive experiments to compare various fusion methods and granularity. Our proposed sideload-CL-adaptation model improves the detection performance by 3.8% to 9.5% in terms of mAP50 on the NVD dataset.
Hier-SLAM++: Neuro-Symbolic Semantic SLAM with a Hierarchically Categorical Gaussian Splatting
Feb 20, 2025
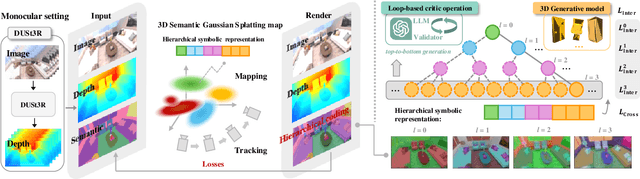
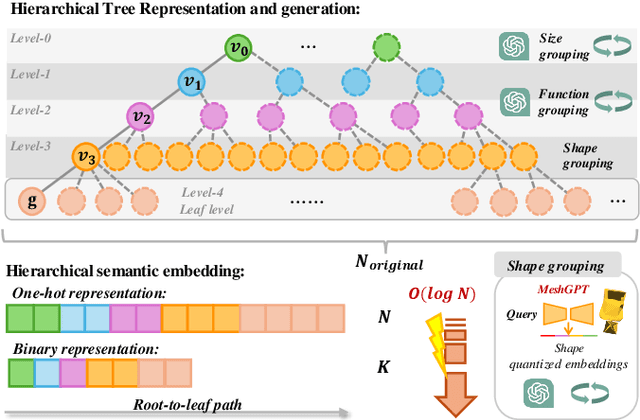

We propose Hier-SLAM++, a comprehensive Neuro-Symbolic semantic 3D Gaussian Splatting SLAM method with both RGB-D and monocular input featuring an advanced hierarchical categorical representation, which enables accurate pose estimation as well as global 3D semantic mapping. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making scene understanding particularly challenging and costly. To address this problem, we introduce a novel and general hierarchical representation that encodes both semantic and geometric information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs) as well as the 3D generative model. By utilizing the proposed hierarchical tree structure, semantic information is symbolically represented and learned in an end-to-end manner. We further introduce a novel semantic loss designed to optimize hierarchical semantic information through both inter-level and cross-level optimization. Additionally, we propose an improved SLAM system to support both RGB-D and monocular inputs using a feed-forward model. To the best of our knowledge, this is the first semantic monocular Gaussian Splatting SLAM system, significantly reducing sensor requirements for 3D semantic understanding and broadening the applicability of semantic Gaussian SLAM system. We conduct experiments on both synthetic and real-world datasets, demonstrating superior or on-par performance with state-of-the-art NeRF-based and Gaussian-based SLAM systems, while significantly reducing storage and training time requirements.
NEUSIS: A Compositional Neuro-Symbolic Framework for Autonomous Perception, Reasoning, and Planning in Complex UAV Search Missions
Sep 16, 2024



This paper addresses the problem of autonomous UAV search missions, where a UAV must locate specific Entities of Interest (EOIs) within a time limit, based on brief descriptions in large, hazard-prone environments with keep-out zones. The UAV must perceive, reason, and make decisions with limited and uncertain information. We propose NEUSIS, a compositional neuro-symbolic system designed for interpretable UAV search and navigation in realistic scenarios. NEUSIS integrates neuro-symbolic visual perception, reasoning, and grounding (GRiD) to process raw sensory inputs, maintains a probabilistic world model for environment representation, and uses a hierarchical planning component (SNaC) for efficient path planning. Experimental results from simulated urban search missions using AirSim and Unreal Engine show that NEUSIS outperforms a state-of-the-art (SOTA) vision-language model and a SOTA search planning model in success rate, search efficiency, and 3D localization. These results demonstrate the effectiveness of our compositional neuro-symbolic approach in handling complex, real-world scenarios, making it a promising solution for autonomous UAV systems in search missions.
TextSLAM: Visual SLAM with Semantic Planar Text Features
May 17, 2023We propose a novel visual SLAM method that integrates text objects tightly by treating them as semantic features via fully exploring their geometric and semantic prior. The text object is modeled as a texture-rich planar patch whose semantic meaning is extracted and updated on the fly for better data association. With the full exploration of locally planar characteristics and semantic meaning of text objects, the SLAM system becomes more accurate and robust even under challenging conditions such as image blurring, large viewpoint changes, and significant illumination variations (day and night). We tested our method in various scenes with the ground truth data. The results show that integrating texture features leads to a more superior SLAM system that can match images across day and night. The reconstructed semantic 3D text map could be useful for navigation and scene understanding in robotic and mixed reality applications. Our project page: https://github.com/SJTU-ViSYS/TextSLAM .
StructDepth: Leveraging the structural regularities for self-supervised indoor depth estimation
Aug 19, 2021

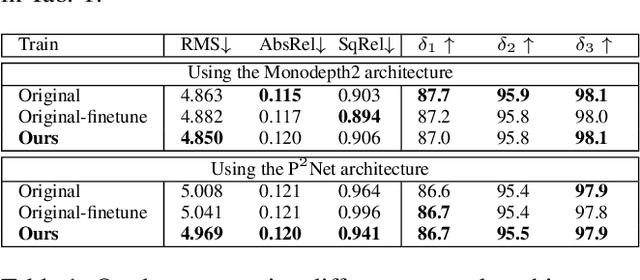
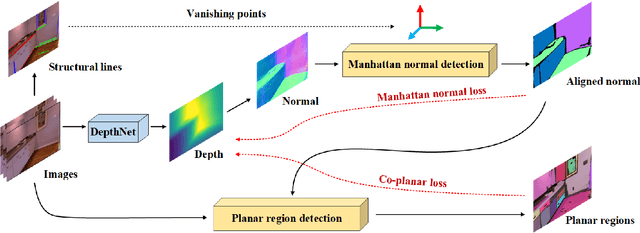
Self-supervised monocular depth estimation has achieved impressive performance on outdoor datasets. Its performance however degrades notably in indoor environments because of the lack of textures. Without rich textures, the photometric consistency is too weak to train a good depth network. Inspired by the early works on indoor modeling, we leverage the structural regularities exhibited in indoor scenes, to train a better depth network. Specifically, we adopt two extra supervisory signals for self-supervised training: 1) the Manhattan normal constraint and 2) the co-planar constraint. The Manhattan normal constraint enforces the major surfaces (the floor, ceiling, and walls) to be aligned with dominant directions. The co-planar constraint states that the 3D points be well fitted by a plane if they are located within the same planar region. To generate the supervisory signals, we adopt two components to classify the major surface normal into dominant directions and detect the planar regions on the fly during training. As the predicted depth becomes more accurate after more training epochs, the supervisory signals also improve and in turn feedback to obtain a better depth model. Through extensive experiments on indoor benchmark datasets, the results show that our network outperforms the state-of-the-art methods. The source code is available at https://github.com/SJTU-ViSYS/StructDepth .
TextSLAM: Visual SLAM with Planar Text Features
Nov 26, 2019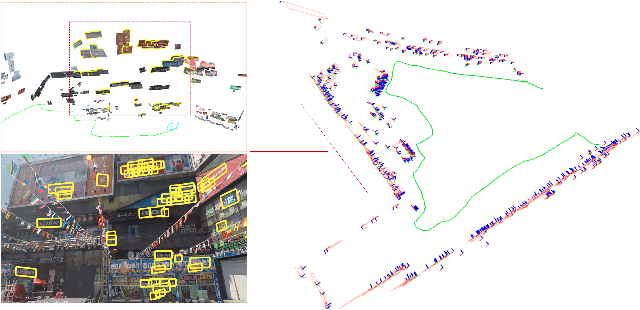
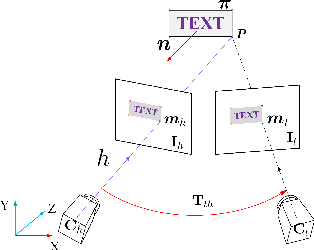
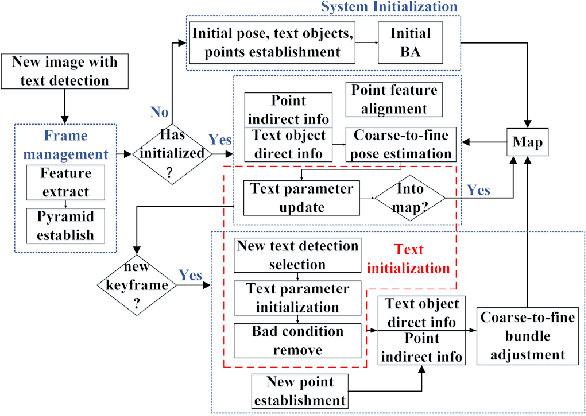

We propose to integrate text objects in man-made scenes tightly into the visual SLAM pipeline. The key idea of our novel text-based visual SLAM is to treat each detected text as a planar feature which is rich of textures and semantic meanings. The text feature is compactly represented by three parameters and integrated into visual SLAM by adopting the illumination-invariant photometric error. We also describe important details involved in implementing a full pipeline of text-based visual SLAM. To our best knowledge, this is the first visual SLAM method tightly coupled with the text features. We tested our method in both indoor and outdoor environments. The results show that with text features, the visual SLAM system becomes more robust and produces much more accurate 3D text maps that could be useful for navigation and scene understanding in robotic or augmented reality applications.