 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFCo-Nav: Efficient Zero-Shot Visual Language Navigation via Collaboration of Slow LLM and Fast Attributed Graph Alignment
Mar 02, 2026Recent advances in large vision-language models (VLMs) and large language models (LLMs) have enabled zero-shot approaches to visual language navigation (VLN), where an agent follows natural language instructions using only ego perception and reasoning. However, existing zero-shot methods typically construct a naive observation graph and perform per-step VLM-LLM inference on it, resulting in high latency and computation costs that limit real-time deployment. To address this, we present SFCo-Nav, an efficient zero-shot VLN framework inspired by the principle of slow-fast cognitive collaboration. SFCo-Nav integrates three key modules: 1) a slow LLM-based planner that produces a strategic chain of subgoals, each linked to an imagined object graph; 2) a fast reactive navigator for real-time object graph construction and subgoal execution; and 3) a lightweight asynchronous slow-fast bridge aligns advanced structured, attributed imagined and perceived graphs to estimate navigation confidence, triggering the slow LLM planner only when necessary. To the best of our knowledge, SFCo-Nav is the first slow-fast collaboration zero-shot VLN system supporting asynchronous LLM triggering according to the internal confidence. Evaluated on the public R2R and REVERIE benchmarks, SFCo-Nav matches or exceeds prior state-of-the-art zero-shot VLN success rates while cutting total token consumption per trajectory by over 50% and running more than 3.5 times faster. Finally, we demonstrate SFCo-Nav on a legged robot in a hotel suite, showcasing its efficiency and practicality in indoor environments.
VGGT-MPR: VGGT-Enhanced Multimodal Place Recognition in Autonomous Driving Environments
Feb 23, 2026In autonomous driving, robust place recognition is critical for global localization and loop closure detection. While inter-modality fusion of camera and LiDAR data in multimodal place recognition (MPR) has shown promise in overcoming the limitations of unimodal counterparts, existing MPR methods basically attend to hand-crafted fusion strategies and heavily parameterized backbones that require costly retraining. To address this, we propose VGGT-MPR, a multimodal place recognition framework that adopts the Visual Geometry Grounded Transformer (VGGT) as a unified geometric engine for both global retrieval and re-ranking. In the global retrieval stage, VGGT extracts geometrically-rich visual embeddings through prior depth-aware and point map supervision, and densifies sparse LiDAR point clouds with predicted depth maps to improve structural representation. This enhances the discriminative ability of fused multimodal features and produces global descriptors for fast retrieval. Beyond global retrieval, we design a training-free re-ranking mechanism that exploits VGGT's cross-view keypoint-tracking capability. By combining mask-guided keypoint extraction with confidence-aware correspondence scoring, our proposed re-ranking mechanism effectively refines retrieval results without additional parameter optimization. Extensive experiments on large-scale autonomous driving benchmarks and our self-collected data demonstrate that VGGT-MPR achieves state-of-the-art performance, exhibiting strong robustness to severe environmental changes, viewpoint shifts, and occlusions. Our code and data will be made publicly available.
M-SEVIQ: A Multi-band Stereo Event Visual-Inertial Quadruped-based Dataset for Perception under Rapid Motion and Challenging Illumination
Jan 06, 2026Agile locomotion in legged robots poses significant challenges for visual perception. Traditional frame-based cameras often fail in these scenarios for producing blurred images, particularly under low-light conditions. In contrast, event cameras capture changes in brightness asynchronously, offering low latency, high temporal resolution, and high dynamic range. These advantages make them suitable for robust perception during rapid motion and under challenging illumination. However, existing event camera datasets exhibit limitations in stereo configurations and multi-band sensing domains under various illumination conditions. To address this gap, we present M-SEVIQ, a multi-band stereo event visual and inertial quadruped dataset collected using a Unitree Go2 equipped with stereo event cameras, a frame-based camera, an inertial measurement unit (IMU), and joint encoders. This dataset contains more than 30 real-world sequences captured across different velocity levels, illumination wavelengths, and lighting conditions. In addition, comprehensive calibration data, including intrinsic, extrinsic, and temporal alignments, are provided to facilitate accurate sensor fusion and benchmarking. Our M-SEVIQ can be used to support research in agile robot perception, sensor fusion, semantic segmentation and multi-modal vision in challenging environments.
360-GeoGS: Geometrically Consistent Feed-Forward 3D Gaussian Splatting Reconstruction for 360 Images
Jan 05, 20263D scene reconstruction is fundamental for spatial intelligence applications such as AR, robotics, and digital twins. Traditional multi-view stereo struggles with sparse viewpoints or low-texture regions, while neural rendering approaches, though capable of producing high-quality results, require per-scene optimization and lack real-time efficiency. Explicit 3D Gaussian Splatting (3DGS) enables efficient rendering, but most feed-forward variants focus on visual quality rather than geometric consistency, limiting accurate surface reconstruction and overall reliability in spatial perception tasks. This paper presents a novel feed-forward 3DGS framework for 360 images, capable of generating geometrically consistent Gaussian primitives while maintaining high rendering quality. A Depth-Normal geometric regularization is introduced to couple rendered depth gradients with normal information, supervising Gaussian rotation, scale, and position to improve point cloud and surface accuracy. Experimental results show that the proposed method maintains high rendering quality while significantly improving geometric consistency, providing an effective solution for 3D reconstruction in spatial perception tasks.
XGrid-Mapping: Explicit Implicit Hybrid Grid Submaps for Efficient Incremental Neural LiDAR Mapping
Dec 24, 2025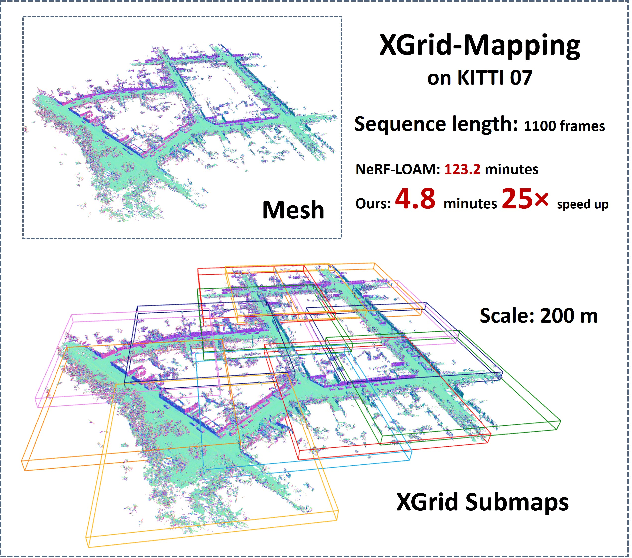
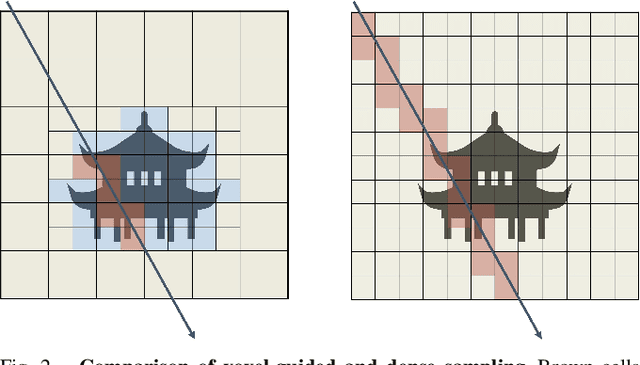
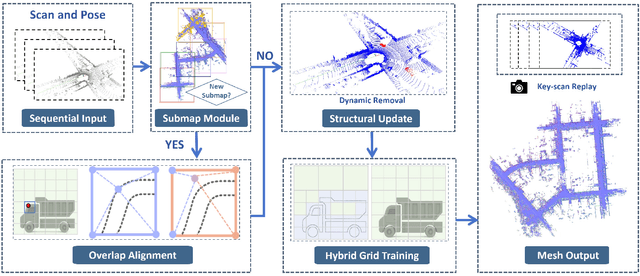
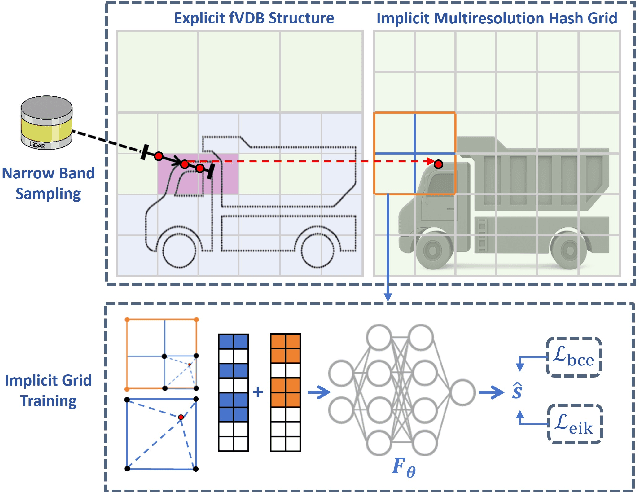
Large-scale incremental mapping is fundamental to the development of robust and reliable autonomous systems, as it underpins incremental environmental understanding with sequential inputs for navigation and decision-making. LiDAR is widely used for this purpose due to its accuracy and robustness. Recently, neural LiDAR mapping has shown impressive performance; however, most approaches rely on dense implicit representations and underutilize geometric structure, while existing voxel-guided methods struggle to achieve real-time performance. To address these challenges, we propose XGrid-Mapping, a hybrid grid framework that jointly exploits explicit and implicit representations for efficient neural LiDAR mapping. Specifically, the strategy combines a sparse grid, providing geometric priors and structural guidance, with an implicit dense grid that enriches scene representation. By coupling the VDB structure with a submap-based organization, the framework reduces computational load and enables efficient incremental mapping on a large scale. To mitigate discontinuities across submaps, we introduce a distillation-based overlap alignment strategy, in which preceding submaps supervise subsequent ones to ensure consistency in overlapping regions. To further enhance robustness and sampling efficiency, we incorporate a dynamic removal module. Extensive experiments show that our approach delivers superior mapping quality while overcoming the efficiency limitations of voxel-guided methods, thereby outperforming existing state-of-the-art mapping methods.
RadarLLM: Empowering Large Language Models to Understand Human Motion from Millimeter-wave Point Cloud Sequence
Apr 14, 2025Millimeter-wave radar provides a privacy-preserving solution for human motion analysis, yet its sparse point clouds pose significant challenges for semantic understanding. We present Radar-LLM, the first framework that leverages large language models (LLMs) for human motion understanding using millimeter-wave radar as the sensing modality. Our approach introduces two key innovations: (1) a motion-guided radar tokenizer based on our Aggregate VQ-VAE architecture that incorporates deformable body templates and masked trajectory modeling to encode spatiotemporal point clouds into compact semantic tokens, and (2) a radar-aware language model that establishes cross-modal alignment between radar and text in a shared embedding space. To address data scarcity, we introduce a physics-aware synthesis pipeline that generates realistic radar-text pairs from motion-text datasets. Extensive experiments demonstrate that Radar-LLM achieves state-of-the-art performance across both synthetic and real-world benchmarks, enabling accurate translation of millimeter-wave signals to natural language descriptions. This breakthrough facilitates comprehensive motion understanding in privacy-sensitive applications like healthcare and smart homes. We will release the full implementation to support further research on https://inowlzy.github.io/RadarLLM/.
Suite-IN++: A FlexiWear BodyNet Integrating Global and Local Motion Features from Apple Suite for Robust Inertial Navigation
Apr 01, 2025



The proliferation of wearable technology has established multi-device ecosystems comprising smartphones, smartwatches, and headphones as critical enablers for ubiquitous pedestrian localization. However, traditional pedestrian dead reckoning (PDR) struggles with diverse motion modes, while data-driven methods, despite improving accuracy, often lack robustness due to their reliance on a single-device setup. Therefore, a promising solution is to fully leverage existing wearable devices to form a flexiwear bodynet for robust and accurate pedestrian localization. This paper presents Suite-IN++, a deep learning framework for flexiwear bodynet-based pedestrian localization. Suite-IN++ integrates motion data from wearable devices on different body parts, using contrastive learning to separate global and local motion features. It fuses global features based on the data reliability of each device to capture overall motion trends and employs an attention mechanism to uncover cross-device correlations in local features, extracting motion details helpful for accurate localization. To evaluate our method, we construct a real-life flexiwear bodynet dataset, incorporating Apple Suite (iPhone, Apple Watch, and AirPods) across diverse walking modes and device configurations. Experimental results demonstrate that Suite-IN++ achieves superior localization accuracy and robustness, significantly outperforming state-of-the-art models in real-life pedestrian tracking scenarios.
A2I-Calib: An Anti-noise Active Multi-IMU Spatial-temporal Calibration Framework for Legged Robots
Mar 10, 2025



Recently, multi-node inertial measurement unit (IMU)-based odometry for legged robots has gained attention due to its cost-effectiveness, power efficiency, and high accuracy. However, the spatial and temporal misalignment between foot-end motion derived from forward kinematics and foot IMU measurements can introduce inconsistent constraints, resulting in odometry drift. Therefore, accurate spatial-temporal calibration is crucial for the multi-IMU systems. Although existing multi-IMU calibration methods have addressed passive single-rigid-body sensor calibration, they are inadequate for legged systems. This is due to the insufficient excitation from traditional gaits for calibration, and enlarged sensitivity to IMU noise during kinematic chain transformations. To address these challenges, we propose A$^2$I-Calib, an anti-noise active multi-IMU calibration framework enabling autonomous spatial-temporal calibration for arbitrary foot-mounted IMUs. Our A$^2$I-Calib includes: 1) an anti-noise trajectory generator leveraging a proposed basis function selection theorem to minimize the condition number in correlation analysis, thus reducing noise sensitivity, and 2) a reinforcement learning (RL)-based controller that ensures robust execution of calibration motions. Furthermore, A$^2$I-Calib is validated on simulation and real-world quadruped robot platforms with various multi-IMU settings, which demonstrates a significant reduction in noise sensitivity and calibration errors, thereby improving the overall multi-IMU odometry performance.
THE-SEAN: A Heart Rate Variation-Inspired Temporally High-Order Event-Based Visual Odometry with Self-Supervised Spiking Event Accumulation Networks
Mar 07, 2025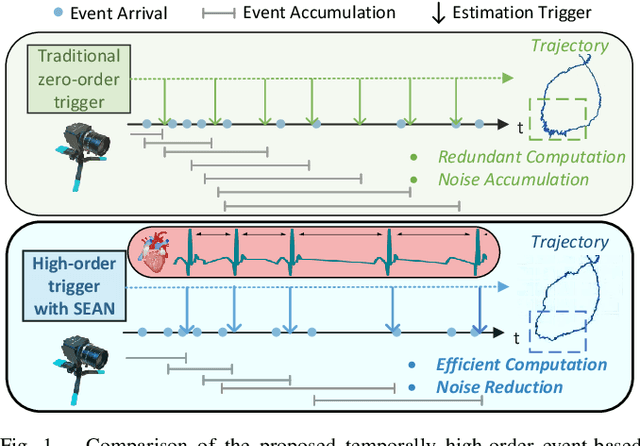
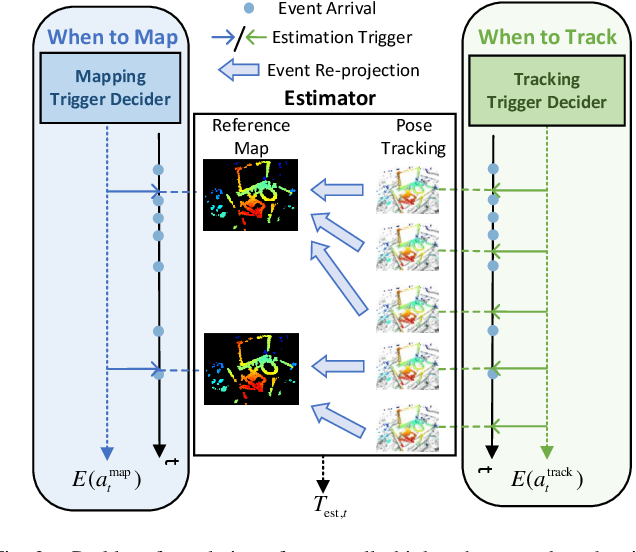
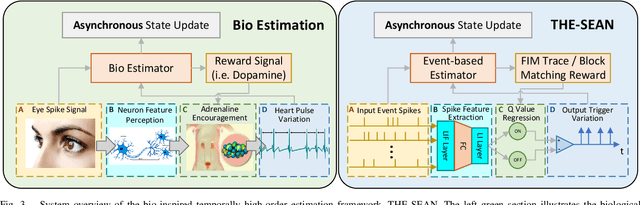
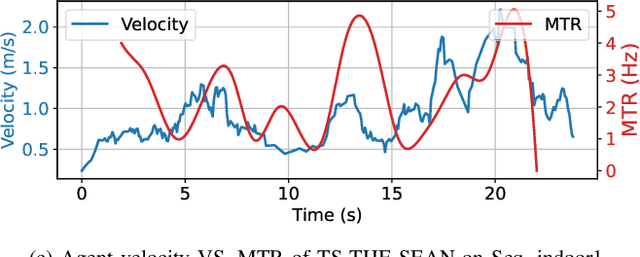
Event-based visual odometry has recently gained attention for its high accuracy and real-time performance in fast-motion systems. Unlike traditional synchronous estimators that rely on constant-frequency (zero-order) triggers, event-based visual odometry can actively accumulate information to generate temporally high-order estimation triggers. However, existing methods primarily focus on adaptive event representation after estimation triggers, neglecting the decision-making process for efficient temporal triggering itself. This oversight leads to the computational redundancy and noise accumulation. In this paper, we introduce a temporally high-order event-based visual odometry with spiking event accumulation networks (THE-SEAN). To the best of our knowledge, it is the first event-based visual odometry capable of dynamically adjusting its estimation trigger decision in response to motion and environmental changes. Inspired by biological systems that regulate hormone secretion to modulate heart rate, a self-supervised spiking neural network is designed to generate estimation triggers. This spiking network extracts temporal features to produce triggers, with rewards based on block matching points and Fisher information matrix (FIM) trace acquired from the estimator itself. Finally, THE-SEAN is evaluated across several open datasets, thereby demonstrating average improvements of 13\% in estimation accuracy, 9\% in smoothness, and 38\% in triggering efficiency compared to the state-of-the-art methods.
mmDEAR: mmWave Point Cloud Density Enhancement for Accurate Human Body Reconstruction
Mar 04, 2025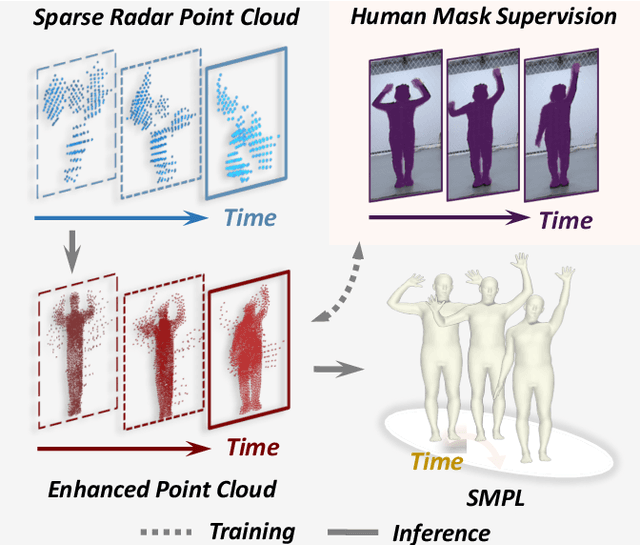

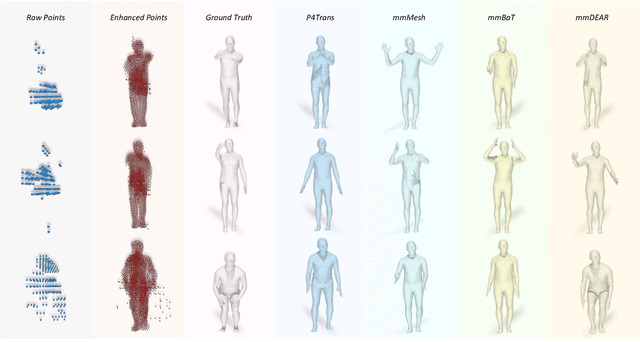
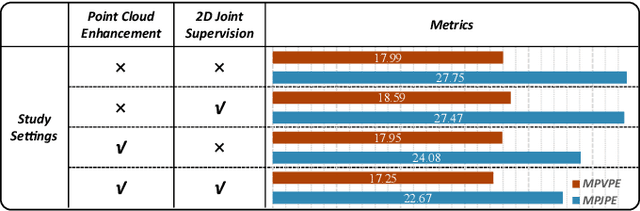
Millimeter-wave (mmWave) radar offers robust sensing capabilities in diverse environments, making it a highly promising solution for human body reconstruction due to its privacy-friendly and non-intrusive nature. However, the significant sparsity of mmWave point clouds limits the estimation accuracy. To overcome this challenge, we propose a two-stage deep learning framework that enhances mmWave point clouds and improves human body reconstruction accuracy. Our method includes a mmWave point cloud enhancement module that densifies the raw data by leveraging temporal features and a multi-stage completion network, followed by a 2D-3D fusion module that extracts both 2D and 3D motion features to refine SMPL parameters. The mmWave point cloud enhancement module learns the detailed shape and posture information from 2D human masks in single-view images. However, image-based supervision is involved only during the training phase, and the inference relies solely on sparse point clouds to maintain privacy. Experiments on multiple datasets demonstrate that our approach outperforms state-of-the-art methods, with the enhanced point clouds further improving performance when integrated into existing models.