 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarLLM: Empowering Large Language Models to Understand Human Motion from Millimeter-wave Point Cloud Sequence
Apr 14, 2025Millimeter-wave radar provides a privacy-preserving solution for human motion analysis, yet its sparse point clouds pose significant challenges for semantic understanding. We present Radar-LLM, the first framework that leverages large language models (LLMs) for human motion understanding using millimeter-wave radar as the sensing modality. Our approach introduces two key innovations: (1) a motion-guided radar tokenizer based on our Aggregate VQ-VAE architecture that incorporates deformable body templates and masked trajectory modeling to encode spatiotemporal point clouds into compact semantic tokens, and (2) a radar-aware language model that establishes cross-modal alignment between radar and text in a shared embedding space. To address data scarcity, we introduce a physics-aware synthesis pipeline that generates realistic radar-text pairs from motion-text datasets. Extensive experiments demonstrate that Radar-LLM achieves state-of-the-art performance across both synthetic and real-world benchmarks, enabling accurate translation of millimeter-wave signals to natural language descriptions. This breakthrough facilitates comprehensive motion understanding in privacy-sensitive applications like healthcare and smart homes. We will release the full implementation to support further research on https://inowlzy.github.io/RadarLLM/.
mmDEAR: mmWave Point Cloud Density Enhancement for Accurate Human Body Reconstruction
Mar 04, 2025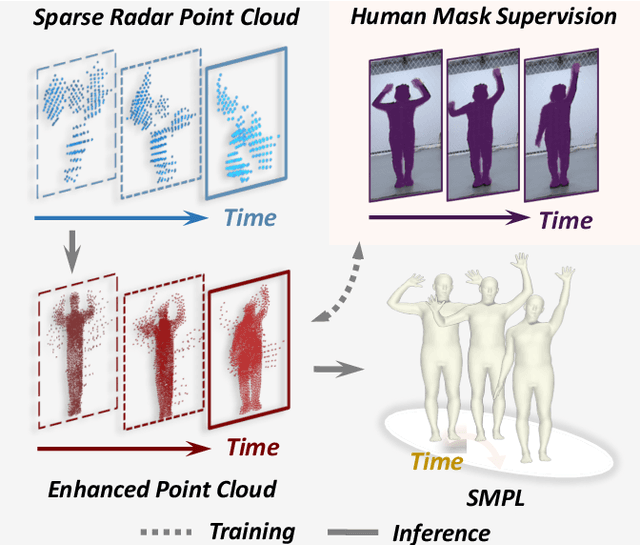

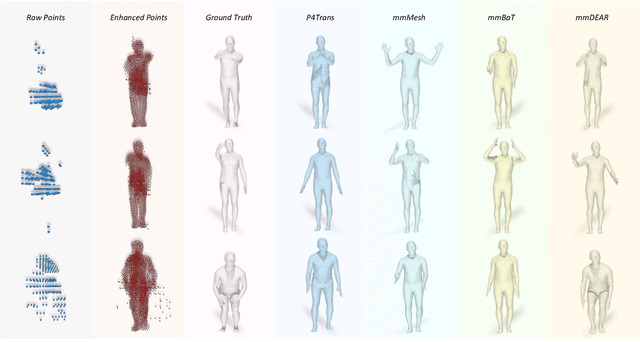
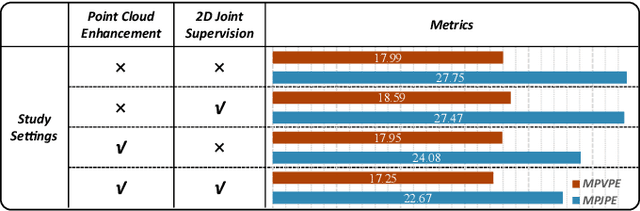
Millimeter-wave (mmWave) radar offers robust sensing capabilities in diverse environments, making it a highly promising solution for human body reconstruction due to its privacy-friendly and non-intrusive nature. However, the significant sparsity of mmWave point clouds limits the estimation accuracy. To overcome this challenge, we propose a two-stage deep learning framework that enhances mmWave point clouds and improves human body reconstruction accuracy. Our method includes a mmWave point cloud enhancement module that densifies the raw data by leveraging temporal features and a multi-stage completion network, followed by a 2D-3D fusion module that extracts both 2D and 3D motion features to refine SMPL parameters. The mmWave point cloud enhancement module learns the detailed shape and posture information from 2D human masks in single-view images. However, image-based supervision is involved only during the training phase, and the inference relies solely on sparse point clouds to maintain privacy. Experiments on multiple datasets demonstrate that our approach outperforms state-of-the-art methods, with the enhanced point clouds further improving performance when integrated into existing models.
Suite-IN: Aggregating Motion Features from Apple Suite for Robust Inertial Navigation
Nov 12, 2024



With the rapid development of wearable technology, devices like smartphones, smartwatches, and headphones equipped with IMUs have become essential for applications such as pedestrian positioning. However, traditional pedestrian dead reckoning (PDR) methods struggle with diverse motion patterns, while recent data-driven approaches, though improving accuracy, often lack robustness due to reliance on a single device.In our work, we attempt to enhance the positioning performance using the low-cost commodity IMUs embedded in the wearable devices. We propose a multi-device deep learning framework named Suite-IN, aggregating motion data from Apple Suite for inertial navigation. Motion data captured by sensors on different body parts contains both local and global motion information, making it essential to reduce the negative effects of localized movements and extract global motion representations from multiple devices.
SMART: Scene-motion-aware human action recognition framework for mental disorder group
Jun 07, 2024



Patients with mental disorders often exhibit risky abnormal actions, such as climbing walls or hitting windows, necessitating intelligent video behavior monitoring for smart healthcare with the rising Internet of Things (IoT) technology. However, the development of vision-based Human Action Recognition (HAR) for these actions is hindered by the lack of specialized algorithms and datasets. In this paper, we innovatively propose to build a vision-based HAR dataset including abnormal actions often occurring in the mental disorder group and then introduce a novel Scene-Motion-aware Action Recognition Technology framework, named SMART, consisting of two technical modules. First, we propose a scene perception module to extract human motion trajectory and human-scene interaction features, which introduces additional scene information for a supplementary semantic representation of the above actions. Second, the multi-stage fusion module fuses the skeleton motion, motion trajectory, and human-scene interaction features, enhancing the semantic association between the skeleton motion and the above supplementary representation, thus generating a comprehensive representation with both human motion and scene information. The effectiveness of our proposed method has been validated on our self-collected HAR dataset (MentalHAD), achieving 94.9% and 93.1% accuracy in un-seen subjects and scenes and outperforming state-of-the-art approaches by 6.5% and 13.2%, respectively. The demonstrated subject- and scene- generalizability makes it possible for SMART's migration to practical deployment in smart healthcare systems for mental disorder patients in medical settings. The code and dataset will be released publicly for further research: https://github.com/Inowlzy/SMART.git.