 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Nov 06, 2025Humanoid soccer poses a representative challenge for embodied intelligence, requiring robots to operate within a tightly coupled perception-action loop. However, existing systems typically rely on decoupled modules, resulting in delayed responses and incoherent behaviors in dynamic environments, while real-world perceptual limitations further exacerbate these issues. In this work, we present a unified reinforcement learning-based controller that enables humanoid robots to acquire reactive soccer skills through the direct integration of visual perception and motion control. Our approach extends Adversarial Motion Priors to perceptual settings in real-world dynamic environments, bridging motion imitation and visually grounded dynamic control. We introduce an encoder-decoder architecture combined with a virtual perception system that models real-world visual characteristics, allowing the policy to recover privileged states from imperfect observations and establish active coordination between perception and action. The resulting controller demonstrates strong reactivity, consistently executing coherent and robust soccer behaviors across various scenarios, including real RoboCup matches.
RadarLLM: Empowering Large Language Models to Understand Human Motion from Millimeter-wave Point Cloud Sequence
Apr 14, 2025Millimeter-wave radar provides a privacy-preserving solution for human motion analysis, yet its sparse point clouds pose significant challenges for semantic understanding. We present Radar-LLM, the first framework that leverages large language models (LLMs) for human motion understanding using millimeter-wave radar as the sensing modality. Our approach introduces two key innovations: (1) a motion-guided radar tokenizer based on our Aggregate VQ-VAE architecture that incorporates deformable body templates and masked trajectory modeling to encode spatiotemporal point clouds into compact semantic tokens, and (2) a radar-aware language model that establishes cross-modal alignment between radar and text in a shared embedding space. To address data scarcity, we introduce a physics-aware synthesis pipeline that generates realistic radar-text pairs from motion-text datasets. Extensive experiments demonstrate that Radar-LLM achieves state-of-the-art performance across both synthetic and real-world benchmarks, enabling accurate translation of millimeter-wave signals to natural language descriptions. This breakthrough facilitates comprehensive motion understanding in privacy-sensitive applications like healthcare and smart homes. We will release the full implementation to support further research on https://inowlzy.github.io/RadarLLM/.
PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
Nov 11, 2019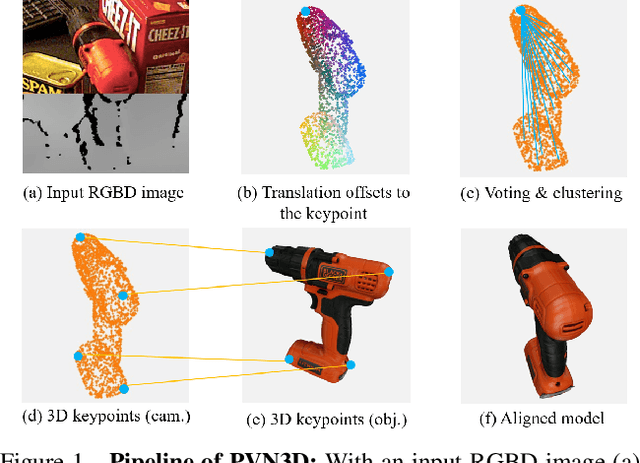
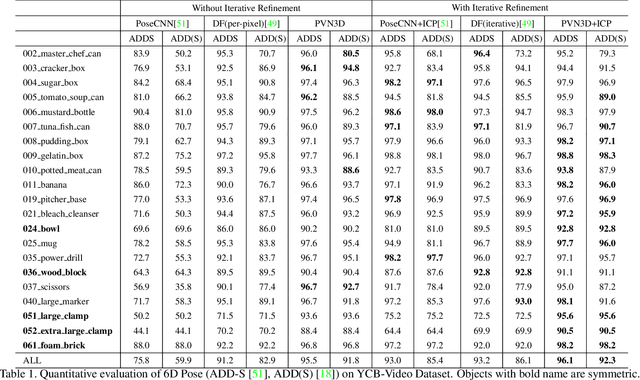
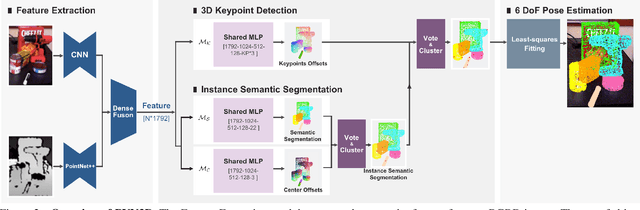
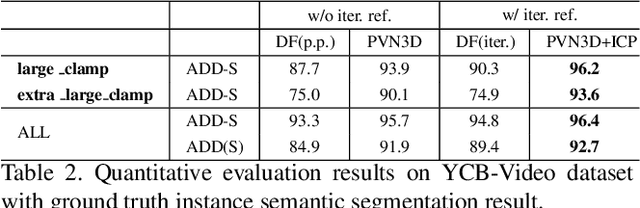
In this work, we present a novel data-driven method for robust 6DoF object pose estimation from a single RGBD image. Unlike previous methods that directly regressing pose parameters, we tackle this challenging task with a keypoint-based approach. Specifically, we propose a deep Hough voting network to detect 3D keypoints of objects and then estimate the 6D pose parameters within a least-squares fitting manner. Our method is a natural extension of 2D-keypoint approaches that successfully work on RGB based 6DoF estimation. It allows us to fully utilize the geometric constraint of rigid objects with the extra depth information and is easy for a network to learn and optimize. Extensive experiments were conducted to demonstrate the effectiveness of 3D-keypoint detection in the 6D pose estimation task. Experimental results also show our method outperforms the state-of-the-art methods by large margins on several benchmarks.