 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025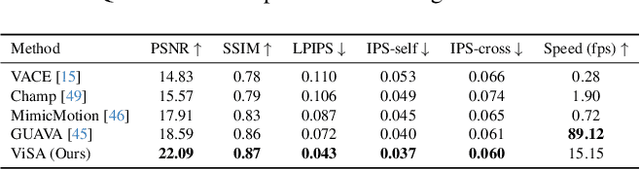
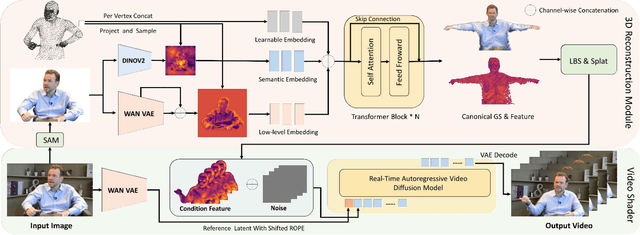
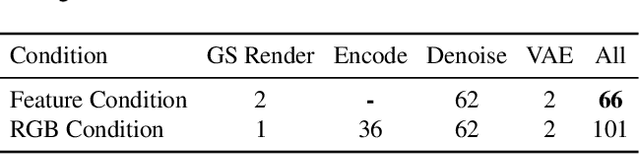
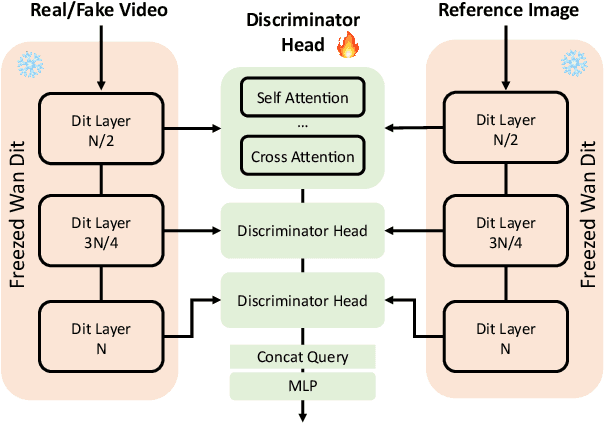
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
PanoLAM: Large Avatar Model for Gaussian Full-Head Synthesis from One-shot Unposed Image
Sep 09, 2025



We present a feed-forward framework for Gaussian full-head synthesis from a single unposed image. Unlike previous work that relies on time-consuming GAN inversion and test-time optimization, our framework can reconstruct the Gaussian full-head model given a single unposed image in a single forward pass. This enables fast reconstruction and rendering during inference. To mitigate the lack of large-scale 3D head assets, we propose a large-scale synthetic dataset from trained 3D GANs and train our framework using only synthetic data. For efficient high-fidelity generation, we introduce a coarse-to-fine Gaussian head generation pipeline, where sparse points from the FLAME model interact with the image features by transformer blocks for feature extraction and coarse shape reconstruction, which are then densified for high-fidelity reconstruction. To fully leverage the prior knowledge residing in pretrained 3D GANs for effective reconstruction, we propose a dual-branch framework that effectively aggregates the structured spherical triplane feature and unstructured point-based features for more effective Gaussian head reconstruction. Experimental results show the effectiveness of our framework towards existing work.
CoProSketch: Controllable and Progressive Sketch Generation with Diffusion Model
Apr 11, 2025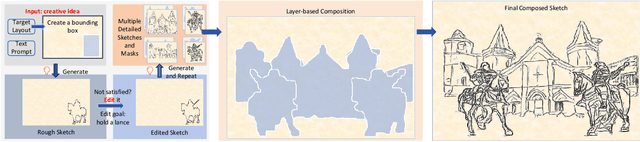
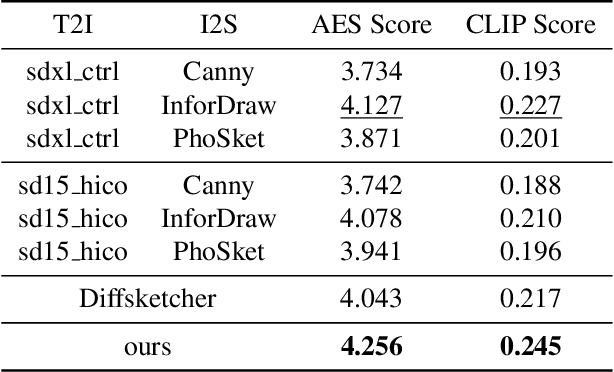
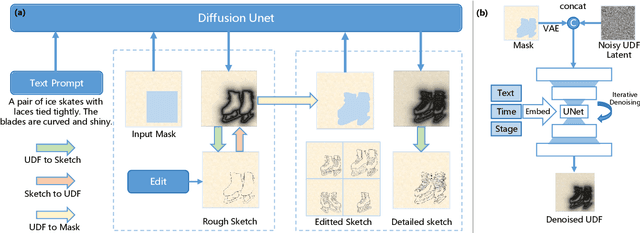
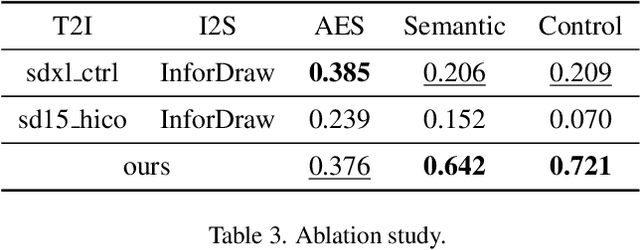
Sketches serve as fundamental blueprints in artistic creation because sketch editing is easier and more intuitive than pixel-level RGB image editing for painting artists, yet sketch generation remains unexplored despite advancements in generative models. We propose a novel framework CoProSketch, providing prominent controllability and details for sketch generation with diffusion models. A straightforward method is fine-tuning a pretrained image generation diffusion model with binarized sketch images. However, we find that the diffusion models fail to generate clear binary images, which makes the produced sketches chaotic. We thus propose to represent the sketches by unsigned distance field (UDF), which is continuous and can be easily decoded to sketches through a lightweight network. With CoProSketch, users generate a rough sketch from a bounding box and a text prompt. The rough sketch can be manually edited and fed back into the model for iterative refinement and will be decoded to a detailed sketch as the final result. Additionally, we curate the first large-scale text-sketch paired dataset as the training data. Experiments demonstrate superior semantic consistency and controllability over baselines, offering a practical solution for integrating user feedback into generative workflows.
LAM: Large Avatar Model for One-shot Animatable Gaussian Head
Feb 25, 2025We present LAM, an innovative Large Avatar Model for animatable Gaussian head reconstruction from a single image. Unlike previous methods that require extensive training on captured video sequences or rely on auxiliary neural networks for animation and rendering during inference, our approach generates Gaussian heads that are immediately animatable and renderable. Specifically, LAM creates an animatable Gaussian head in a single forward pass, enabling reenactment and rendering without additional networks or post-processing steps. This capability allows for seamless integration into existing rendering pipelines, ensuring real-time animation and rendering across a wide range of platforms, including mobile phones. The centerpiece of our framework is the canonical Gaussian attributes generator, which utilizes FLAME canonical points as queries. These points interact with multi-scale image features through a Transformer to accurately predict Gaussian attributes in the canonical space. The reconstructed canonical Gaussian avatar can then be animated utilizing standard linear blend skinning (LBS) with corrective blendshapes as the FLAME model did and rendered in real-time on various platforms. Our experimental results demonstrate that LAM outperforms state-of-the-art methods on existing benchmarks.
MulSMo: Multimodal Stylized Motion Generation by Bidirectional Control Flow
Dec 13, 2024Generating motion sequences conforming to a target style while adhering to the given content prompts requires accommodating both the content and style. In existing methods, the information usually only flows from style to content, which may cause conflict between the style and content, harming the integration. Differently, in this work we build a bidirectional control flow between the style and the content, also adjusting the style towards the content, in which case the style-content collision is alleviated and the dynamics of the style is better preserved in the integration. Moreover, we extend the stylized motion generation from one modality, i.e. the style motion, to multiple modalities including texts and images through contrastive learning, leading to flexible style control on the motion generation. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, while also enabling multimodal signals control. The code of our method will be made publicly available.
LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
Oct 09, 2024



Language plays a vital role in the realm of human motion. Existing methods have largely depended on CLIP text embeddings for motion generation, yet they fall short in effectively aligning language and motion due to CLIP's pretraining on static image-text pairs. This work introduces LaMP, a novel Language-Motion Pretraining model, which transitions from a language-vision to a more suitable language-motion latent space. It addresses key limitations by generating motion-informative text embeddings, significantly enhancing the relevance and semantics of generated motion sequences. With LaMP, we advance three key tasks: text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. For generation, we utilize LaMP to provide the text condition instead of CLIP, and an autoregressive masked prediction is designed to achieve mask modeling without rank collapse in transformers. For retrieval, motion features from LaMP's motion transformer interact with query tokens to retrieve text features from the text transformer, and vice versa. For captioning, we finetune a large language model with the language-informative motion features to develop a strong motion captioning model. In addition, we introduce the LaMP-BertScore metric to assess the alignment of generated motions with textual descriptions. Extensive experimental results on multiple datasets demonstrate substantial improvements over previous methods across all three tasks. The code of our method will be made public.
MoGenTS: Motion Generation based on Spatial-Temporal Joint Modeling
Sep 26, 2024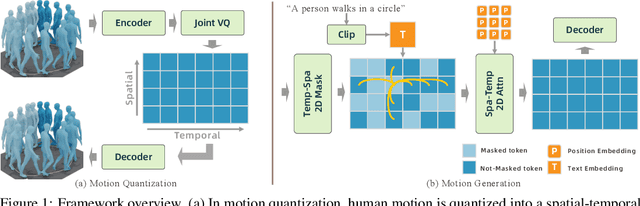
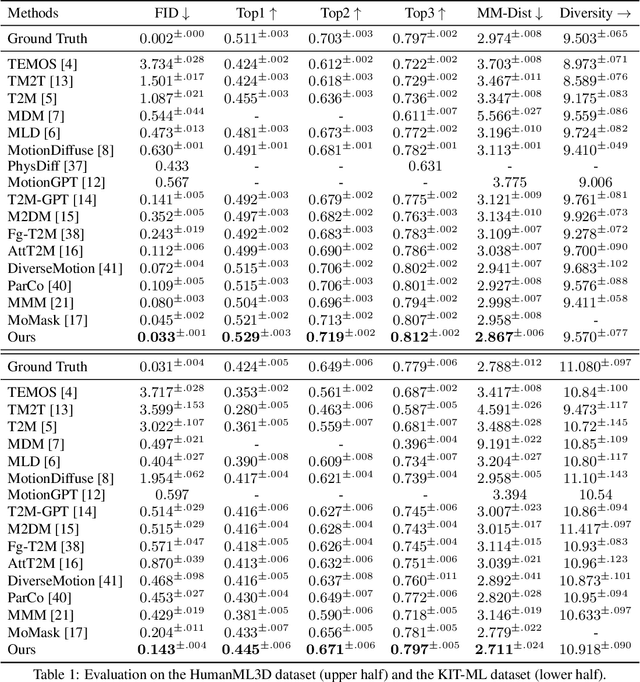
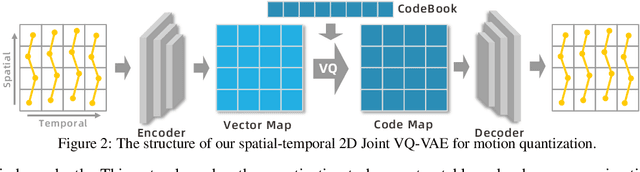
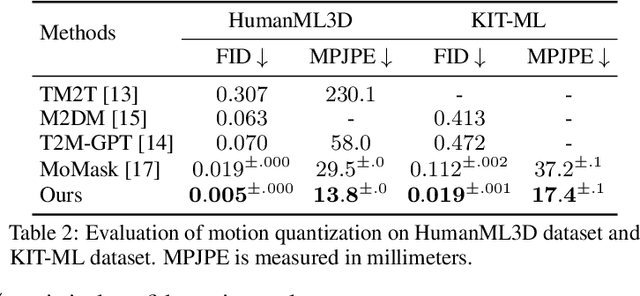
Motion generation from discrete quantization offers many advantages over continuous regression, but at the cost of inevitable approximation errors. Previous methods usually quantize the entire body pose into one code, which not only faces the difficulty in encoding all joints within one vector but also loses the spatial relationship between different joints. Differently, in this work we quantize each individual joint into one vector, which i) simplifies the quantization process as the complexity associated with a single joint is markedly lower than that of the entire pose; ii) maintains a spatial-temporal structure that preserves both the spatial relationships among joints and the temporal movement patterns; iii) yields a 2D token map, which enables the application of various 2D operations widely used in 2D images. Grounded in the 2D motion quantization, we build a spatial-temporal modeling framework, where 2D joint VQVAE, temporal-spatial 2D masking technique, and spatial-temporal 2D attention are proposed to take advantage of spatial-temporal signals among the 2D tokens. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, with a $26.6\%$ decrease of FID on HumanML3D and a $29.9\%$ decrease on KIT-ML.
Gaussian-Informed Continuum for Physical Property Identification and Simulation
Jun 21, 2024This paper studies the problem of estimating physical properties (system identification) through visual observations. To facilitate geometry-aware guidance in physical property estimation, we introduce a novel hybrid framework that leverages 3D Gaussian representation to not only capture explicit shapes but also enable the simulated continuum to deduce implicit shapes during training. We propose a new dynamic 3D Gaussian framework based on motion factorization to recover the object as 3D Gaussian point sets across different time states. Furthermore, we develop a coarse-to-fine filling strategy to generate the density fields of the object from the Gaussian reconstruction, allowing for the extraction of object continuums along with their surfaces and the integration of Gaussian attributes into these continuums. In addition to the extracted object surfaces, the Gaussian-informed continuum also enables the rendering of object masks during simulations, serving as implicit shape guidance for physical property estimation. Extensive experimental evaluations demonstrate that our pipeline achieves state-of-the-art performance across multiple benchmarks and metrics. Additionally, we illustrate the effectiveness of the proposed method through real-world demonstrations, showcasing its practical utility. Our project page is at https://jukgei.github.io/project/gic.
Freditor: High-Fidelity and Transferable NeRF Editing by Frequency Decomposition
Apr 03, 2024



This paper enables high-fidelity, transferable NeRF editing by frequency decomposition. Recent NeRF editing pipelines lift 2D stylization results to 3D scenes while suffering from blurry results, and fail to capture detailed structures caused by the inconsistency between 2D editings. Our critical insight is that low-frequency components of images are more multiview-consistent after editing compared with their high-frequency parts. Moreover, the appearance style is mainly exhibited on the low-frequency components, and the content details especially reside in high-frequency parts. This motivates us to perform editing on low-frequency components, which results in high-fidelity edited scenes. In addition, the editing is performed in the low-frequency feature space, enabling stable intensity control and novel scene transfer. Comprehensive experiments conducted on photorealistic datasets demonstrate the superior performance of high-fidelity and transferable NeRF editing. The project page is at \url{https://aigc3d.github.io/freditor}.
OV9D: Open-Vocabulary Category-Level 9D Object Pose and Size Estimation
Mar 19, 2024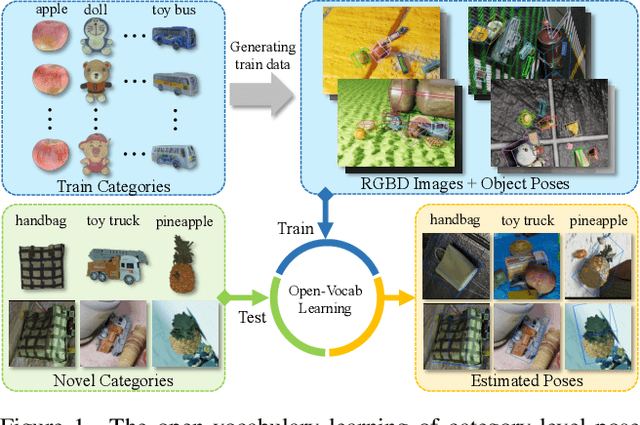
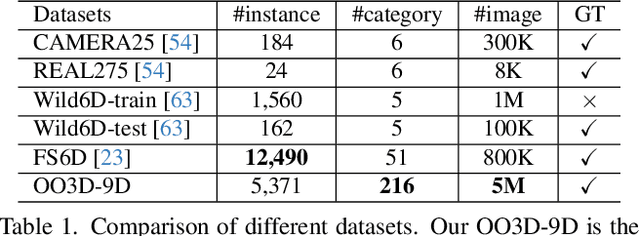

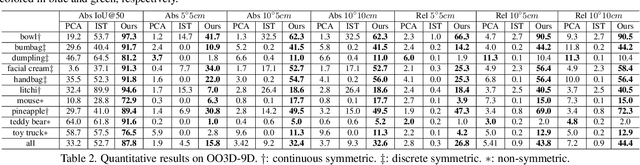
This paper studies a new open-set problem, the open-vocabulary category-level object pose and size estimation. Given human text descriptions of arbitrary novel object categories, the robot agent seeks to predict the position, orientation, and size of the target object in the observed scene image. To enable such generalizability, we first introduce OO3D-9D, a large-scale photorealistic dataset for this task. Derived from OmniObject3D, OO3D-9D is the largest and most diverse dataset in the field of category-level object pose and size estimation. It includes additional annotations for the symmetry axis of each category, which help resolve symmetric ambiguity. Apart from the large-scale dataset, we find another key to enabling such generalizability is leveraging the strong prior knowledge in pre-trained visual-language foundation models. We then propose a framework built on pre-trained DinoV2 and text-to-image stable diffusion models to infer the normalized object coordinate space (NOCS) maps of the target instances. This framework fully leverages the visual semantic prior from DinoV2 and the aligned visual and language knowledge within the text-to-image diffusion model, which enables generalization to various text descriptions of novel categories. Comprehensive quantitative and qualitative experiments demonstrate that the proposed open-vocabulary method, trained on our large-scale synthesized data, significantly outperforms the baseline and can effectively generalize to real-world images of unseen categories. The project page is at https://ov9d.github.io.