 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSplatter: Enabling Cross-Device Efficient Gaussian Splatting in Web Browsers via WebGPU
Feb 03, 2026We present WebSplatter, an end-to-end GPU rendering pipeline for the heterogeneous web ecosystem. Unlike naive ports, WebSplatter introduces a wait-free hierarchical radix sort that circumvents the lack of global atomics in WebGPU, ensuring deterministic execution across diverse hardware. Furthermore, we propose an opacity-aware geometry culling stage that dynamically prunes splats before rasterization, significantly reducing overdraw and peak memory footprint. Evaluation demonstrates that WebSplatter consistently achieves 1.2$\times$ to 4.5$\times$ speedups over state-of-the-art web viewers.
LAM: Large Avatar Model for One-shot Animatable Gaussian Head
Feb 25, 2025We present LAM, an innovative Large Avatar Model for animatable Gaussian head reconstruction from a single image. Unlike previous methods that require extensive training on captured video sequences or rely on auxiliary neural networks for animation and rendering during inference, our approach generates Gaussian heads that are immediately animatable and renderable. Specifically, LAM creates an animatable Gaussian head in a single forward pass, enabling reenactment and rendering without additional networks or post-processing steps. This capability allows for seamless integration into existing rendering pipelines, ensuring real-time animation and rendering across a wide range of platforms, including mobile phones. The centerpiece of our framework is the canonical Gaussian attributes generator, which utilizes FLAME canonical points as queries. These points interact with multi-scale image features through a Transformer to accurately predict Gaussian attributes in the canonical space. The reconstructed canonical Gaussian avatar can then be animated utilizing standard linear blend skinning (LBS) with corrective blendshapes as the FLAME model did and rendered in real-time on various platforms. Our experimental results demonstrate that LAM outperforms state-of-the-art methods on existing benchmarks.
Malignancy-Aware Follow-Up Volume Prediction for Lung Nodules
Jun 24, 2020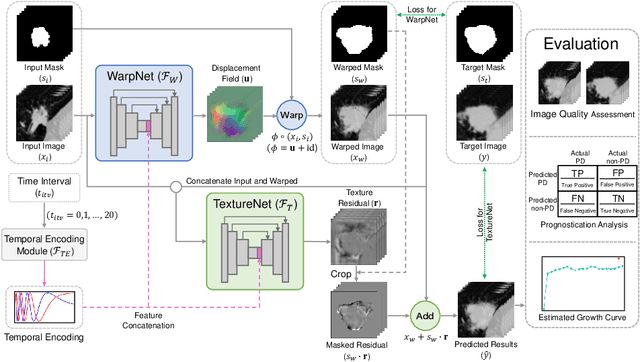
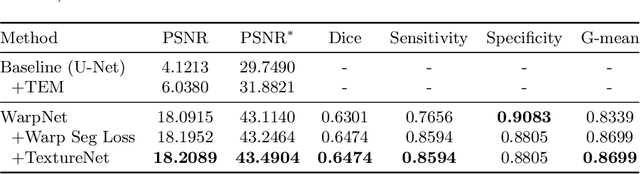

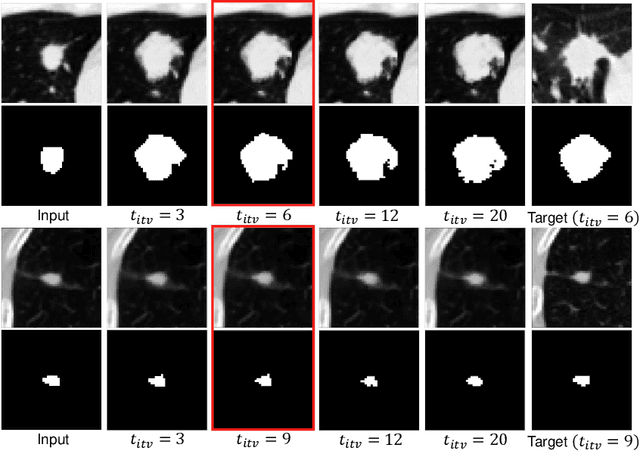
Follow-up serves an important role in the management of pulmonary nodules for lung cancer. Imaging diagnostic guidelines with expert consensus have been made to help radiologists make clinical decision for each patient. However, tumor growth is such a complicated process that it is difficult to stratify high-risk nodules from low-risk ones based on morphologic characteristics. On the other hand, recent deep learning studies using convolutional neural networks (CNNs) to predict the malignancy score of nodules, only provides clinicians with black-box predictions. To this end, we propose a unified framework, named Nodule Follow-Up Prediction Network (NoFoNet), which predicts the growth of pulmonary nodules with high-quality visual appearances and accurate quantitative malignancy scores, given any time interval from baseline observations. It is achieved by predicting future displacement field of each voxel with a WarpNet. A TextureNet is further developed to refine textural details of WarpNet outputs. We also introduce techniques including Temporal Encoding Module and Warp Segmentation Loss to encourage time-aware and malignancy-aware representation learning. We build an in-house follow-up dataset from two medical centers to validate the effectiveness of the proposed method. NoFoNet~significantly outperforms direct prediction by a U-Net in terms of visual quality; more importantly, it demonstrates accurate differentiating performance between high- and low-risk nodules. Our promising results suggest the potentials in computer aided intervention for lung nodule management.
AlignShift: Bridging the Gap of Imaging Thickness in 3D Anisotropic Volumes
May 05, 2020

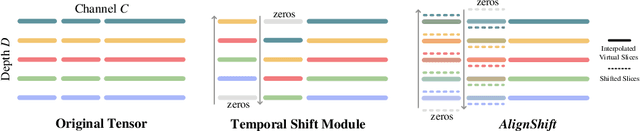
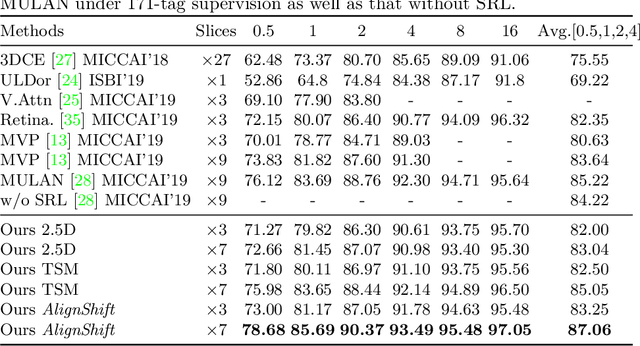
This paper addresses a fundamental challenge in 3D medical image processing: how to deal with imaging thickness. For anisotropic medical volumes, there is a significant performance gap between thin-slice (mostly 1mm) and thick-slice (mostly 5mm) volumes. Prior arts tend to use 3D approaches for the thin-slice and 2D approaches for the thick-slice, respectively. We aim at a unified approach for both thin- and thick-slice medical volumes. Inspired by recent advances in video analysis, we propose AlignShift, a novel parameter-free operator to convert theoretically any 2D pretrained network into thickness-aware 3D network. Remarkably, the converted networks behave like 3D for the thin-slice, nevertheless degenerate to 2D for the thick-slice adaptively. The unified thickness-aware representation learning is achieved by shifting and fusing aligned "virtual slices" as per the input imaging thickness. Extensive experiments on public large-scale DeepLesion benchmark, consisting of 32K lesions for universal lesion detection, validate the effectiveness of our method, which outperforms previous state of the art by considerable margins, without whistles and bells. More importantly, to our knowledge, this is the first method that bridges the performance gap between thin- and thick-slice volumes by a unified framework. To improve research reproducibility, our code in PyTorch is open source at https://github.com/M3DV/AlignShift.