 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
PanoLAM: Large Avatar Model for Gaussian Full-Head Synthesis from One-shot Unposed Image
Sep 09, 2025



We present a feed-forward framework for Gaussian full-head synthesis from a single unposed image. Unlike previous work that relies on time-consuming GAN inversion and test-time optimization, our framework can reconstruct the Gaussian full-head model given a single unposed image in a single forward pass. This enables fast reconstruction and rendering during inference. To mitigate the lack of large-scale 3D head assets, we propose a large-scale synthetic dataset from trained 3D GANs and train our framework using only synthetic data. For efficient high-fidelity generation, we introduce a coarse-to-fine Gaussian head generation pipeline, where sparse points from the FLAME model interact with the image features by transformer blocks for feature extraction and coarse shape reconstruction, which are then densified for high-fidelity reconstruction. To fully leverage the prior knowledge residing in pretrained 3D GANs for effective reconstruction, we propose a dual-branch framework that effectively aggregates the structured spherical triplane feature and unstructured point-based features for more effective Gaussian head reconstruction. Experimental results show the effectiveness of our framework towards existing work.
PF-LHM: 3D Animatable Avatar Reconstruction from Pose-free Articulated Human Images
Jun 16, 2025Reconstructing an animatable 3D human from casually captured images of an articulated subject without camera or human pose information is a practical yet challenging task due to view misalignment, occlusions, and the absence of structural priors. While optimization-based methods can produce high-fidelity results from monocular or multi-view videos, they require accurate pose estimation and slow iterative optimization, limiting scalability in unconstrained scenarios. Recent feed-forward approaches enable efficient single-image reconstruction but struggle to effectively leverage multiple input images to reduce ambiguity and improve reconstruction accuracy. To address these challenges, we propose PF-LHM, a large human reconstruction model that generates high-quality 3D avatars in seconds from one or multiple casually captured pose-free images. Our approach introduces an efficient Encoder-Decoder Point-Image Transformer architecture, which fuses hierarchical geometric point features and multi-view image features through multimodal attention. The fused features are decoded to recover detailed geometry and appearance, represented using 3D Gaussian splats. Extensive experiments on both real and synthetic datasets demonstrate that our method unifies single- and multi-image 3D human reconstruction, achieving high-fidelity and animatable 3D human avatars without requiring camera and human pose annotations. Code and models will be released to the public.
LAM: Large Avatar Model for One-shot Animatable Gaussian Head
Feb 25, 2025We present LAM, an innovative Large Avatar Model for animatable Gaussian head reconstruction from a single image. Unlike previous methods that require extensive training on captured video sequences or rely on auxiliary neural networks for animation and rendering during inference, our approach generates Gaussian heads that are immediately animatable and renderable. Specifically, LAM creates an animatable Gaussian head in a single forward pass, enabling reenactment and rendering without additional networks or post-processing steps. This capability allows for seamless integration into existing rendering pipelines, ensuring real-time animation and rendering across a wide range of platforms, including mobile phones. The centerpiece of our framework is the canonical Gaussian attributes generator, which utilizes FLAME canonical points as queries. These points interact with multi-scale image features through a Transformer to accurately predict Gaussian attributes in the canonical space. The reconstructed canonical Gaussian avatar can then be animated utilizing standard linear blend skinning (LBS) with corrective blendshapes as the FLAME model did and rendered in real-time on various platforms. Our experimental results demonstrate that LAM outperforms state-of-the-art methods on existing benchmarks.
Is Foreground Prototype Sufficient? Few-Shot Medical Image Segmentation with Background-Fused Prototype
Dec 04, 2024Few-shot Semantic Segmentation(FSS)aim to adapt a pre-trained model to new classes with as few as a single labeled training sample per class. The existing prototypical work used in natural image scenarios biasedly focus on capturing foreground's discrimination while employing a simplistic representation for background, grounded on the inherent observation separation between foreground and background. However, this paradigm is not applicable to medical images where the foreground and background share numerous visual features, necessitating a more detailed description for background. In this paper, we present a new pluggable Background-fused prototype(Bro)approach for FSS in medical images. Instead of finding a commonality of background subjects in support image, Bro incorporates this background with two pivot designs. Specifically, Feature Similarity Calibration(FeaC)initially reduces noise in the support image by employing feature cross-attention with the query image. Subsequently, Hierarchical Channel Adversarial Attention(HiCA)merges the background into comprehensive prototypes. We achieve this by a channel groups-based attention mechanism, where an adversarial Mean-Offset structure encourages a coarse-to-fine fusion. Extensive experiments show that previous state-of-the-art methods, when paired with Bro, experience significant performance improvements. This demonstrates a more integrated way to represent backgrounds specifically for medical image.
AniGS: Animatable Gaussian Avatar from a Single Image with Inconsistent Gaussian Reconstruction
Dec 03, 2024



Generating animatable human avatars from a single image is essential for various digital human modeling applications. Existing 3D reconstruction methods often struggle to capture fine details in animatable models, while generative approaches for controllable animation, though avoiding explicit 3D modeling, suffer from viewpoint inconsistencies in extreme poses and computational inefficiencies. In this paper, we address these challenges by leveraging the power of generative models to produce detailed multi-view canonical pose images, which help resolve ambiguities in animatable human reconstruction. We then propose a robust method for 3D reconstruction of inconsistent images, enabling real-time rendering during inference. Specifically, we adapt a transformer-based video generation model to generate multi-view canonical pose images and normal maps, pretraining on a large-scale video dataset to improve generalization. To handle view inconsistencies, we recast the reconstruction problem as a 4D task and introduce an efficient 3D modeling approach using 4D Gaussian Splatting. Experiments demonstrate that our method achieves photorealistic, real-time animation of 3D human avatars from in-the-wild images, showcasing its effectiveness and generalization capability.
LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
Oct 09, 2024



Language plays a vital role in the realm of human motion. Existing methods have largely depended on CLIP text embeddings for motion generation, yet they fall short in effectively aligning language and motion due to CLIP's pretraining on static image-text pairs. This work introduces LaMP, a novel Language-Motion Pretraining model, which transitions from a language-vision to a more suitable language-motion latent space. It addresses key limitations by generating motion-informative text embeddings, significantly enhancing the relevance and semantics of generated motion sequences. With LaMP, we advance three key tasks: text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. For generation, we utilize LaMP to provide the text condition instead of CLIP, and an autoregressive masked prediction is designed to achieve mask modeling without rank collapse in transformers. For retrieval, motion features from LaMP's motion transformer interact with query tokens to retrieve text features from the text transformer, and vice versa. For captioning, we finetune a large language model with the language-informative motion features to develop a strong motion captioning model. In addition, we introduce the LaMP-BertScore metric to assess the alignment of generated motions with textual descriptions. Extensive experimental results on multiple datasets demonstrate substantial improvements over previous methods across all three tasks. The code of our method will be made public.
MoGenTS: Motion Generation based on Spatial-Temporal Joint Modeling
Sep 26, 2024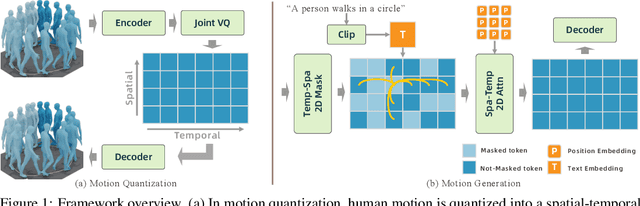
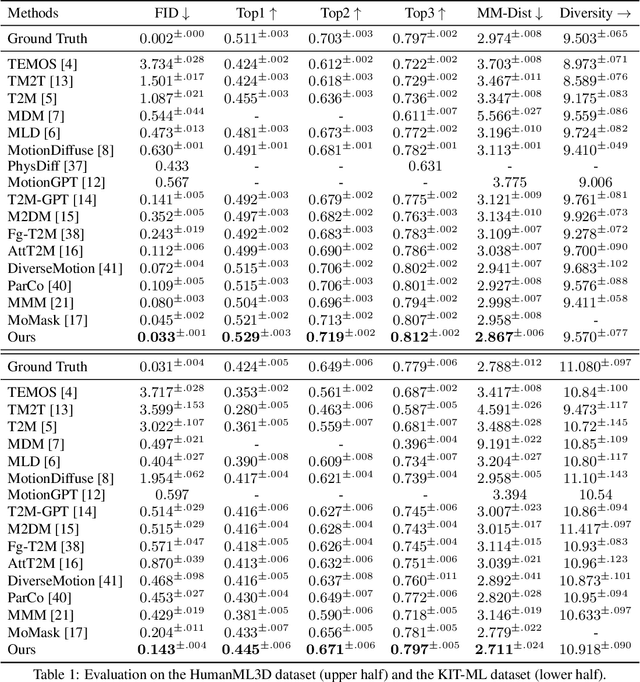
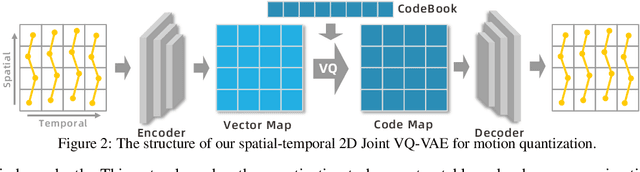
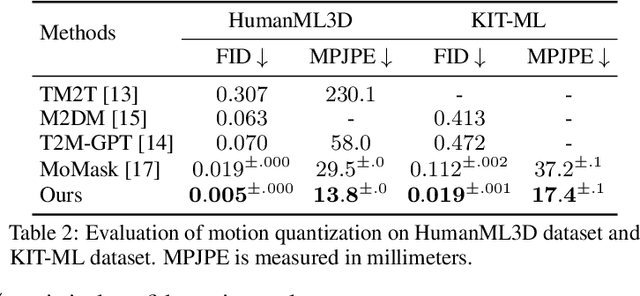
Motion generation from discrete quantization offers many advantages over continuous regression, but at the cost of inevitable approximation errors. Previous methods usually quantize the entire body pose into one code, which not only faces the difficulty in encoding all joints within one vector but also loses the spatial relationship between different joints. Differently, in this work we quantize each individual joint into one vector, which i) simplifies the quantization process as the complexity associated with a single joint is markedly lower than that of the entire pose; ii) maintains a spatial-temporal structure that preserves both the spatial relationships among joints and the temporal movement patterns; iii) yields a 2D token map, which enables the application of various 2D operations widely used in 2D images. Grounded in the 2D motion quantization, we build a spatial-temporal modeling framework, where 2D joint VQVAE, temporal-spatial 2D masking technique, and spatial-temporal 2D attention are proposed to take advantage of spatial-temporal signals among the 2D tokens. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, with a $26.6\%$ decrease of FID on HumanML3D and a $29.9\%$ decrease on KIT-ML.
Atlas Gaussians Diffusion for 3D Generation with Infinite Number of Points
Aug 23, 2024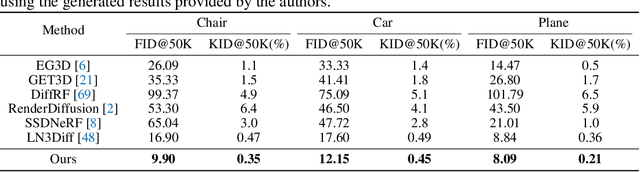
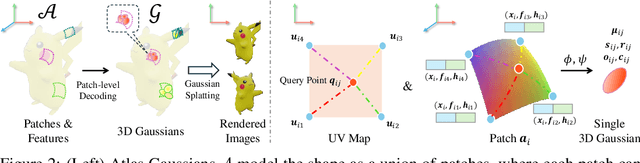
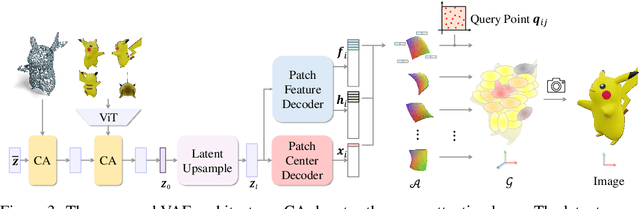
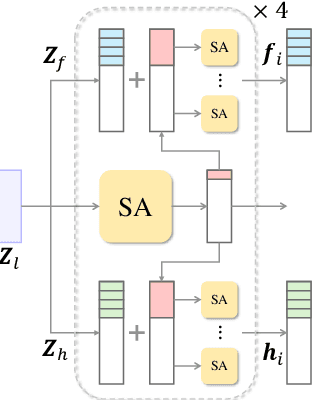
Using the latent diffusion model has proven effective in developing novel 3D generation techniques. To harness the latent diffusion model, a key challenge is designing a high-fidelity and efficient representation that links the latent space and the 3D space. In this paper, we introduce Atlas Gaussians, a novel representation for feed-forward native 3D generation. Atlas Gaussians represent a shape as the union of local patches, and each patch can decode 3D Gaussians. We parameterize a patch as a sequence of feature vectors and design a learnable function to decode 3D Gaussians from the feature vectors. In this process, we incorporate UV-based sampling, enabling the generation of a sufficiently large, and theoretically infinite, number of 3D Gaussian points. The large amount of 3D Gaussians enables high-quality details of generation results. Moreover, due to local awareness of the representation, the transformer-based decoding procedure operates on a patch level, ensuring efficiency. We train a variational autoencoder to learn the Atlas Gaussians representation, and then apply a latent diffusion model on its latent space for learning 3D Generation. Experiments show that our approach outperforms the prior arts of feed-forward native 3D generation.
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Jun 10, 2024



In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.