 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
LHM: Large Animatable Human Reconstruction Model from a Single Image in Seconds
Mar 13, 2025Animatable 3D human reconstruction from a single image is a challenging problem due to the ambiguity in decoupling geometry, appearance, and deformation. Recent advances in 3D human reconstruction mainly focus on static human modeling, and the reliance of using synthetic 3D scans for training limits their generalization ability. Conversely, optimization-based video methods achieve higher fidelity but demand controlled capture conditions and computationally intensive refinement processes. Motivated by the emergence of large reconstruction models for efficient static reconstruction, we propose LHM (Large Animatable Human Reconstruction Model) to infer high-fidelity avatars represented as 3D Gaussian splatting in a feed-forward pass. Our model leverages a multimodal transformer architecture to effectively encode the human body positional features and image features with attention mechanism, enabling detailed preservation of clothing geometry and texture. To further boost the face identity preservation and fine detail recovery, we propose a head feature pyramid encoding scheme to aggregate multi-scale features of the head regions. Extensive experiments demonstrate that our LHM generates plausible animatable human in seconds without post-processing for face and hands, outperforming existing methods in both reconstruction accuracy and generalization ability.
AniGS: Animatable Gaussian Avatar from a Single Image with Inconsistent Gaussian Reconstruction
Dec 03, 2024



Generating animatable human avatars from a single image is essential for various digital human modeling applications. Existing 3D reconstruction methods often struggle to capture fine details in animatable models, while generative approaches for controllable animation, though avoiding explicit 3D modeling, suffer from viewpoint inconsistencies in extreme poses and computational inefficiencies. In this paper, we address these challenges by leveraging the power of generative models to produce detailed multi-view canonical pose images, which help resolve ambiguities in animatable human reconstruction. We then propose a robust method for 3D reconstruction of inconsistent images, enabling real-time rendering during inference. Specifically, we adapt a transformer-based video generation model to generate multi-view canonical pose images and normal maps, pretraining on a large-scale video dataset to improve generalization. To handle view inconsistencies, we recast the reconstruction problem as a 4D task and introduce an efficient 3D modeling approach using 4D Gaussian Splatting. Experiments demonstrate that our method achieves photorealistic, real-time animation of 3D human avatars from in-the-wild images, showcasing its effectiveness and generalization capability.
Music Genre Classification with ResNet and Bi-GRU Using Visual Spectrograms
Jul 20, 2023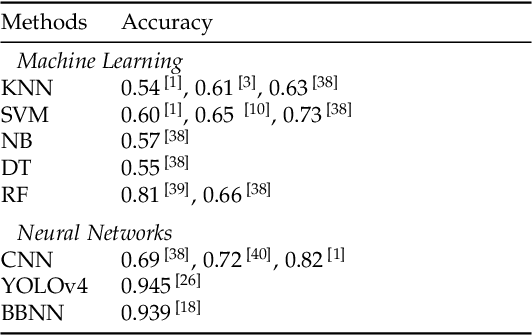

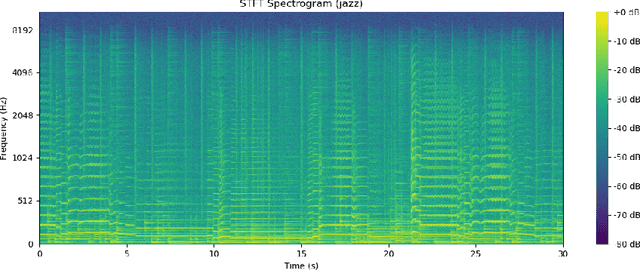
Music recommendation systems have emerged as a vital component to enhance user experience and satisfaction for the music streaming services, which dominates music consumption. The key challenge in improving these recommender systems lies in comprehending the complexity of music data, specifically for the underpinning music genre classification. The limitations of manual genre classification have highlighted the need for a more advanced system, namely the Automatic Music Genre Classification (AMGC) system. While traditional machine learning techniques have shown potential in genre classification, they heavily rely on manually engineered features and feature selection, failing to capture the full complexity of music data. On the other hand, deep learning classification architectures like the traditional Convolutional Neural Networks (CNN) are effective in capturing the spatial hierarchies but struggle to capture the temporal dynamics inherent in music data. To address these challenges, this study proposes a novel approach using visual spectrograms as input, and propose a hybrid model that combines the strength of the Residual neural Network (ResNet) and the Gated Recurrent Unit (GRU). This model is designed to provide a more comprehensive analysis of music data, offering the potential to improve the music recommender systems through achieving a more comprehensive analysis of music data and hence potentially more accurate genre classification.
Machine-Learning Prediction of the Computed Band Gaps of Double Perovskite Materials
Jan 04, 2023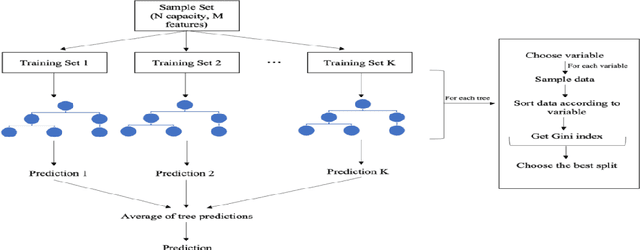

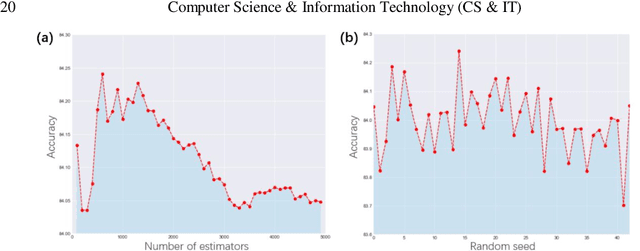
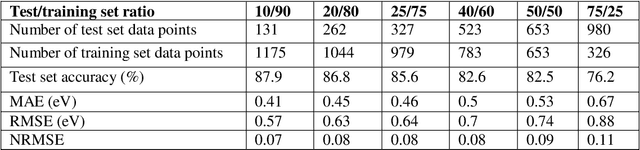
Prediction of the electronic structure of functional materials is essential for the engineering of new devices. Conventional electronic structure prediction methods based on density functional theory (DFT) suffer from not only high computational cost, but also limited accuracy arising from the approximations of the exchange-correlation functional. Surrogate methods based on machine learning have garnered much attention as a viable alternative to bypass these limitations, especially in the prediction of solid-state band gaps, which motivated this research study. Herein, we construct a random forest regression model for band gaps of double perovskite materials, using a dataset of 1306 band gaps computed with the GLLBSC (Gritsenko, van Leeuwen, van Lenthe, and Baerends solid correlation) functional. Among the 20 physical features employed, we find that the bulk modulus, superconductivity temperature, and cation electronegativity exhibit the highest importance scores, consistent with the physics of the underlying electronic structure. Using the top 10 features, a model accuracy of 85.6% with a root mean square error of 0.64 eV is obtained, comparable to previous studies. Our results are significant in the sense that they attest to the potential of machine learning regressions for the rapid screening of promising candidate functional materials.
Multi-objective beetle antennae search algorithm
Feb 24, 2020



In engineering optimization problems, multiple objectives with a large number of variables under highly nonlinear constraints are usually required to be simultaneously optimized. Significant computing effort are required to find the Pareto front of a nonlinear multi-objective optimization problem. Swarm intelligence based metaheuristic algorithms have been successfully applied to solve multi-objective optimization problems. Recently, an individual intelligence based algorithm called beetle antennae search algorithm was proposed. This algorithm was proved to be more computationally efficient. Therefore, we extended this algorithm to solve multi-objective optimization problems. The proposed multi-objective beetle antennae search algorithm is tested using four well-selected benchmark functions and its performance is compared with other multi-objective optimization algorithms. The results show that the proposed multi-objective beetle antennae search algorithm has higher computational efficiency with satisfactory accuracy.
Structured3D: A Large Photo-realistic Dataset for Structured 3D Modeling
Aug 01, 2019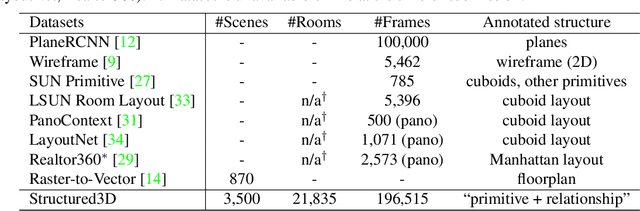



Recently, there has been growing interest in developing learning-based methods to detect and utilize salient semi-global or global structures, such as junctions, lines, planes, cuboids, smooth surfaces, and all types of symmetries, for 3D scene modeling and understanding. However, the ground truth annotations are often obtained via human labor, which is particularly challenging and inefficient for such tasks due to the large number of 3D structure instances (e.g., line segments) and other factors such as viewpoints and occlusions. In this paper, we present a new synthetic dataset, Structured3D, with the aim to providing large-scale photo-realistic images with rich 3D structure annotations for a wide spectrum of structured 3D modeling tasks. We take advantage of the availability of millions of professional interior designs and automatically extract 3D structures from them. We generate high-quality images with an industry-leading rendering engine. We use our synthetic dataset in combination with real images to train deep neural networks for room layout estimation and demonstrate improved performance on benchmark datasets.