 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloseUpShot: Close-up Novel View Synthesis from Sparse-views via Point-conditioned Diffusion Model
Nov 17, 2025Reconstructing 3D scenes and synthesizing novel views from sparse input views is a highly challenging task. Recent advances in video diffusion models have demonstrated strong temporal reasoning capabilities, making them a promising tool for enhancing reconstruction quality under sparse-view settings. However, existing approaches are primarily designed for modest viewpoint variations, which struggle in capturing fine-grained details in close-up scenarios since input information is severely limited. In this paper, we present a diffusion-based framework, called CloseUpShot, for close-up novel view synthesis from sparse inputs via point-conditioned video diffusion. Specifically, we observe that pixel-warping conditioning suffers from severe sparsity and background leakage in close-up settings. To address this, we propose hierarchical warping and occlusion-aware noise suppression, enhancing the quality and completeness of the conditioning images for the video diffusion model. Furthermore, we introduce global structure guidance, which leverages a dense fused point cloud to provide consistent geometric context to the diffusion process, to compensate for the lack of globally consistent 3D constraints in sparse conditioning inputs. Extensive experiments on multiple datasets demonstrate that our method outperforms existing approaches, especially in close-up novel view synthesis, clearly validating the effectiveness of our design.
DAM-VSR: Disentanglement of Appearance and Motion for Video Super-Resolution
Jul 01, 2025


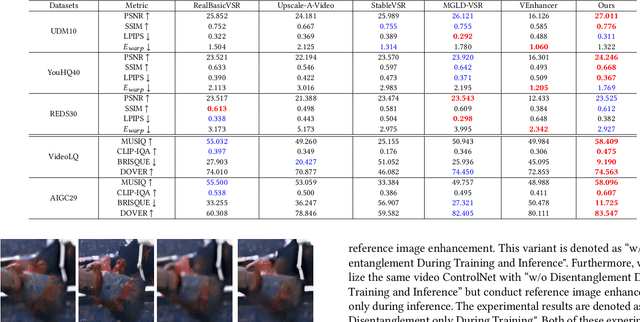
Real-world video super-resolution (VSR) presents significant challenges due to complex and unpredictable degradations. Although some recent methods utilize image diffusion models for VSR and have shown improved detail generation capabilities, they still struggle to produce temporally consistent frames. We attempt to use Stable Video Diffusion (SVD) combined with ControlNet to address this issue. However, due to the intrinsic image-animation characteristics of SVD, it is challenging to generate fine details using only low-quality videos. To tackle this problem, we propose DAM-VSR, an appearance and motion disentanglement framework for VSR. This framework disentangles VSR into appearance enhancement and motion control problems. Specifically, appearance enhancement is achieved through reference image super-resolution, while motion control is achieved through video ControlNet. This disentanglement fully leverages the generative prior of video diffusion models and the detail generation capabilities of image super-resolution models. Furthermore, equipped with the proposed motion-aligned bidirectional sampling strategy, DAM-VSR can conduct VSR on longer input videos. DAM-VSR achieves state-of-the-art performance on real-world data and AIGC data, demonstrating its powerful detail generation capabilities.
PF-LHM: 3D Animatable Avatar Reconstruction from Pose-free Articulated Human Images
Jun 16, 2025Reconstructing an animatable 3D human from casually captured images of an articulated subject without camera or human pose information is a practical yet challenging task due to view misalignment, occlusions, and the absence of structural priors. While optimization-based methods can produce high-fidelity results from monocular or multi-view videos, they require accurate pose estimation and slow iterative optimization, limiting scalability in unconstrained scenarios. Recent feed-forward approaches enable efficient single-image reconstruction but struggle to effectively leverage multiple input images to reduce ambiguity and improve reconstruction accuracy. To address these challenges, we propose PF-LHM, a large human reconstruction model that generates high-quality 3D avatars in seconds from one or multiple casually captured pose-free images. Our approach introduces an efficient Encoder-Decoder Point-Image Transformer architecture, which fuses hierarchical geometric point features and multi-view image features through multimodal attention. The fused features are decoded to recover detailed geometry and appearance, represented using 3D Gaussian splats. Extensive experiments on both real and synthetic datasets demonstrate that our method unifies single- and multi-image 3D human reconstruction, achieving high-fidelity and animatable 3D human avatars without requiring camera and human pose annotations. Code and models will be released to the public.
Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
May 28, 2025



Audio-driven human animation methods, such as talking head and talking body generation, have made remarkable progress in generating synchronized facial movements and appealing visual quality videos. However, existing methods primarily focus on single human animation and struggle with multi-stream audio inputs, facing incorrect binding problems between audio and persons. Additionally, they exhibit limitations in instruction-following capabilities. To solve this problem, in this paper, we propose a novel task: Multi-Person Conversational Video Generation, and introduce a new framework, MultiTalk, to address the challenges during multi-person generation. Specifically, for audio injection, we investigate several schemes and propose the Label Rotary Position Embedding (L-RoPE) method to resolve the audio and person binding problem. Furthermore, during training, we observe that partial parameter training and multi-task training are crucial for preserving the instruction-following ability of the base model. MultiTalk achieves superior performance compared to other methods on several datasets, including talking head, talking body, and multi-person datasets, demonstrating the powerful generation capabilities of our approach.
LHM: Large Animatable Human Reconstruction Model from a Single Image in Seconds
Mar 13, 2025Animatable 3D human reconstruction from a single image is a challenging problem due to the ambiguity in decoupling geometry, appearance, and deformation. Recent advances in 3D human reconstruction mainly focus on static human modeling, and the reliance of using synthetic 3D scans for training limits their generalization ability. Conversely, optimization-based video methods achieve higher fidelity but demand controlled capture conditions and computationally intensive refinement processes. Motivated by the emergence of large reconstruction models for efficient static reconstruction, we propose LHM (Large Animatable Human Reconstruction Model) to infer high-fidelity avatars represented as 3D Gaussian splatting in a feed-forward pass. Our model leverages a multimodal transformer architecture to effectively encode the human body positional features and image features with attention mechanism, enabling detailed preservation of clothing geometry and texture. To further boost the face identity preservation and fine detail recovery, we propose a head feature pyramid encoding scheme to aggregate multi-scale features of the head regions. Extensive experiments demonstrate that our LHM generates plausible animatable human in seconds without post-processing for face and hands, outperforming existing methods in both reconstruction accuracy and generalization ability.
MaterialMVP: Illumination-Invariant Material Generation via Multi-view PBR Diffusion
Mar 13, 2025Physically-based rendering (PBR) has become a cornerstone in modern computer graphics, enabling realistic material representation and lighting interactions in 3D scenes. In this paper, we present MaterialMVP, a novel end-to-end model for generating PBR textures from 3D meshes and image prompts, addressing key challenges in multi-view material synthesis. Our approach leverages Reference Attention to extract and encode informative latent from the input reference images, enabling intuitive and controllable texture generation. We also introduce a Consistency-Regularized Training strategy to enforce stability across varying viewpoints and illumination conditions, ensuring illumination-invariant and geometrically consistent results. Additionally, we propose Dual-Channel Material Generation, which separately optimizes albedo and metallic-roughness (MR) textures while maintaining precise spatial alignment with the input images through Multi-Channel Aligned Attention. Learnable material embeddings are further integrated to capture the distinct properties of albedo and MR. Experimental results demonstrate that our model generates PBR textures with realistic behavior across diverse lighting scenarios, outperforming existing methods in both consistency and quality for scalable 3D asset creation.
AniGS: Animatable Gaussian Avatar from a Single Image with Inconsistent Gaussian Reconstruction
Dec 03, 2024



Generating animatable human avatars from a single image is essential for various digital human modeling applications. Existing 3D reconstruction methods often struggle to capture fine details in animatable models, while generative approaches for controllable animation, though avoiding explicit 3D modeling, suffer from viewpoint inconsistencies in extreme poses and computational inefficiencies. In this paper, we address these challenges by leveraging the power of generative models to produce detailed multi-view canonical pose images, which help resolve ambiguities in animatable human reconstruction. We then propose a robust method for 3D reconstruction of inconsistent images, enabling real-time rendering during inference. Specifically, we adapt a transformer-based video generation model to generate multi-view canonical pose images and normal maps, pretraining on a large-scale video dataset to improve generalization. To handle view inconsistencies, we recast the reconstruction problem as a 4D task and introduce an efficient 3D modeling approach using 4D Gaussian Splatting. Experiments demonstrate that our method achieves photorealistic, real-time animation of 3D human avatars from in-the-wild images, showcasing its effectiveness and generalization capability.
Photometric Inverse Rendering: Shading Cues Modeling and Surface Reflectance Regularization
Aug 13, 2024



This paper addresses the problem of inverse rendering from photometric images. Existing approaches for this problem suffer from the effects of self-shadows, inter-reflections, and lack of constraints on the surface reflectance, leading to inaccurate decomposition of reflectance and illumination due to the ill-posed nature of inverse rendering. In this work, we propose a new method for neural inverse rendering. Our method jointly optimizes the light source position to account for the self-shadows in images, and computes indirect illumination using a differentiable rendering layer and an importance sampling strategy. To enhance surface reflectance decomposition, we introduce a new regularization by distilling DINO features to foster accurate and consistent material decomposition. Extensive experiments on synthetic and real datasets demonstrate that our method outperforms the state-of-the-art methods in reflectance decomposition.
DreamDissector: Learning Disentangled Text-to-3D Generation from 2D Diffusion Priors
Jul 23, 2024
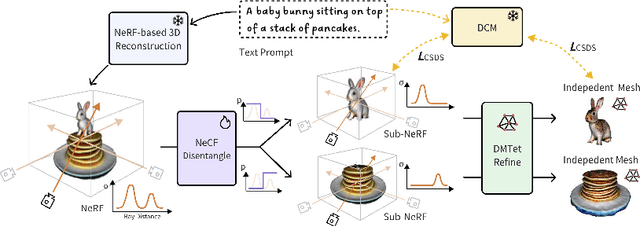
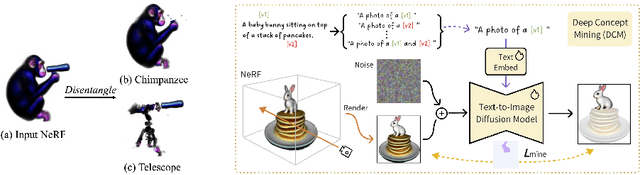

Text-to-3D generation has recently seen significant progress. To enhance its practicality in real-world applications, it is crucial to generate multiple independent objects with interactions, similar to layer-compositing in 2D image editing. However, existing text-to-3D methods struggle with this task, as they are designed to generate either non-independent objects or independent objects lacking spatially plausible interactions. Addressing this, we propose DreamDissector, a text-to-3D method capable of generating multiple independent objects with interactions. DreamDissector accepts a multi-object text-to-3D NeRF as input and produces independent textured meshes. To achieve this, we introduce the Neural Category Field (NeCF) for disentangling the input NeRF. Additionally, we present the Category Score Distillation Sampling (CSDS), facilitated by a Deep Concept Mining (DCM) module, to tackle the concept gap issue in diffusion models. By leveraging NeCF and CSDS, we can effectively derive sub-NeRFs from the original scene. Further refinement enhances geometry and texture. Our experimental results validate the effectiveness of DreamDissector, providing users with novel means to control 3D synthesis at the object level and potentially opening avenues for various creative applications in the future.
SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Apr 08, 2024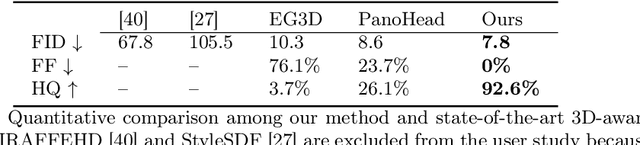

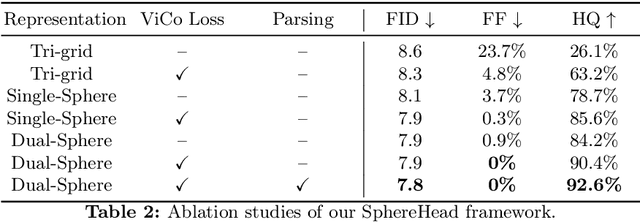
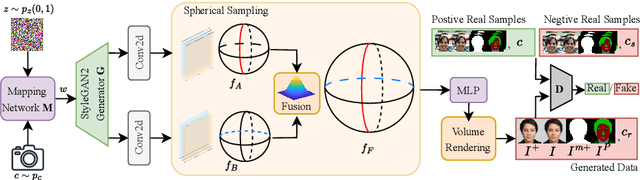
While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing "mirroring" artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate "face" in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.