 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCMat: Multiview-Consistent and Physically Accurate PBR Material Generation
Dec 18, 2024



Existing 2D methods utilize UNet-based diffusion models to generate multi-view physically-based rendering (PBR) maps but struggle with multi-view inconsistency, while some 3D methods directly generate UV maps, encountering generalization issues due to the limited 3D data. To address these problems, we propose a two-stage approach, including multi-view generation and UV materials refinement. In the generation stage, we adopt a Diffusion Transformer (DiT) model to generate PBR materials, where both the specially designed multi-branch DiT and reference-based DiT blocks adopt a global attention mechanism to promote feature interaction and fusion between different views, thereby improving multi-view consistency. In addition, we adopt a PBR-based diffusion loss to ensure that the generated materials align with realistic physical principles. In the refinement stage, we propose a material-refined DiT that performs inpainting in empty areas and enhances details in UV space. Except for the normal condition, this refinement also takes the material map from the generation stage as an additional condition to reduce the learning difficulty and improve generalization. Extensive experiments show that our method achieves state-of-the-art performance in texturing 3D objects with PBR materials and provides significant advantages for graphics relighting applications. Project Page: https://lingtengqiu.github.io/2024/MCMat/
AniGS: Animatable Gaussian Avatar from a Single Image with Inconsistent Gaussian Reconstruction
Dec 03, 2024



Generating animatable human avatars from a single image is essential for various digital human modeling applications. Existing 3D reconstruction methods often struggle to capture fine details in animatable models, while generative approaches for controllable animation, though avoiding explicit 3D modeling, suffer from viewpoint inconsistencies in extreme poses and computational inefficiencies. In this paper, we address these challenges by leveraging the power of generative models to produce detailed multi-view canonical pose images, which help resolve ambiguities in animatable human reconstruction. We then propose a robust method for 3D reconstruction of inconsistent images, enabling real-time rendering during inference. Specifically, we adapt a transformer-based video generation model to generate multi-view canonical pose images and normal maps, pretraining on a large-scale video dataset to improve generalization. To handle view inconsistencies, we recast the reconstruction problem as a 4D task and introduce an efficient 3D modeling approach using 4D Gaussian Splatting. Experiments demonstrate that our method achieves photorealistic, real-time animation of 3D human avatars from in-the-wild images, showcasing its effectiveness and generalization capability.
LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
Oct 09, 2024



Language plays a vital role in the realm of human motion. Existing methods have largely depended on CLIP text embeddings for motion generation, yet they fall short in effectively aligning language and motion due to CLIP's pretraining on static image-text pairs. This work introduces LaMP, a novel Language-Motion Pretraining model, which transitions from a language-vision to a more suitable language-motion latent space. It addresses key limitations by generating motion-informative text embeddings, significantly enhancing the relevance and semantics of generated motion sequences. With LaMP, we advance three key tasks: text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. For generation, we utilize LaMP to provide the text condition instead of CLIP, and an autoregressive masked prediction is designed to achieve mask modeling without rank collapse in transformers. For retrieval, motion features from LaMP's motion transformer interact with query tokens to retrieve text features from the text transformer, and vice versa. For captioning, we finetune a large language model with the language-informative motion features to develop a strong motion captioning model. In addition, we introduce the LaMP-BertScore metric to assess the alignment of generated motions with textual descriptions. Extensive experimental results on multiple datasets demonstrate substantial improvements over previous methods across all three tasks. The code of our method will be made public.
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Mar 21, 2024
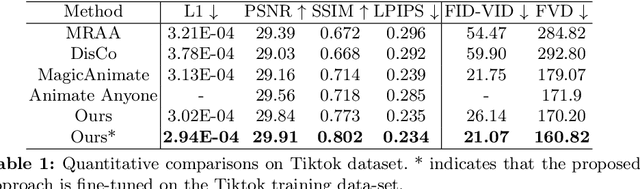
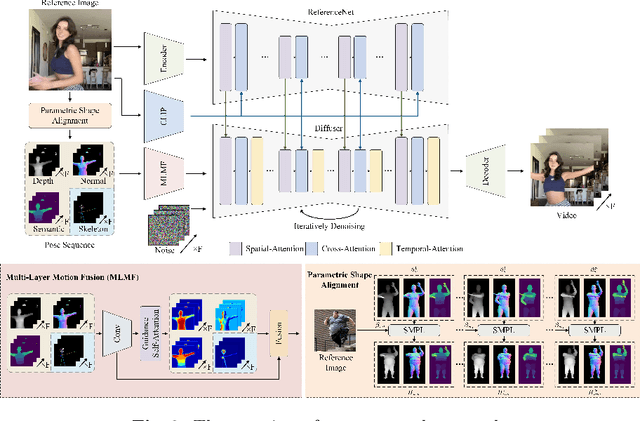
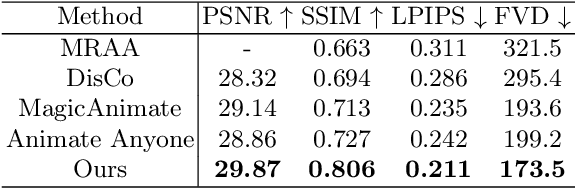
In this study, we introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enhance shape alignment and motion guidance in curernt human generative techniques. The methodology utilizes the SMPL(Skinned Multi-Person Linear) model as the 3D human parametric model to establish a unified representation of body shape and pose. This facilitates the accurate capture of intricate human geometry and motion characteristics from source videos. Specifically, we incorporate rendered depth images, normal maps, and semantic maps obtained from SMPL sequences, alongside skeleton-based motion guidance, to enrich the conditions to the latent diffusion model with comprehensive 3D shape and detailed pose attributes. A multi-layer motion fusion module, integrating self-attention mechanisms, is employed to fuse the shape and motion latent representations in the spatial domain. By representing the 3D human parametric model as the motion guidance, we can perform parametric shape alignment of the human body between the reference image and the source video motion. Experimental evaluations conducted on benchmark datasets demonstrate the methodology's superior ability to generate high-quality human animations that accurately capture both pose and shape variations. Furthermore, our approach also exhibits superior generalization capabilities on the proposed wild dataset. Project page: https://fudan-generative-vision.github.io/champ.