 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Jan 27, 2026Vision-Language-Action (VLA) models have shown promise in robot manipulation but often struggle to generalize to new instructions or complex multi-task scenarios. We identify a critical pathology in current training paradigms where goal-driven data collection creates a dataset bias. In such datasets, language instructions are highly predictable from visual observations alone, causing the conditional mutual information between instructions and actions to vanish, a phenomenon we term Information Collapse. Consequently, models degenerate into vision-only policies that ignore language constraints and fail in out-of-distribution (OOD) settings. To address this, we propose LangForce, a novel framework that enforces instruction following via Bayesian decomposition. By introducing learnable Latent Action Queries, we construct a dual-branch architecture to estimate both a vision-only prior $p(a \mid v)$ and a language-conditioned posterior $π(a \mid v, \ell)$. We then optimize the policy to maximize the conditional Pointwise Mutual Information (PMI) between actions and instructions. This objective effectively penalizes the vision shortcut and rewards actions that explicitly explain the language command. Without requiring new data, LangForce significantly improves generalization. Extensive experiments across on SimplerEnv and RoboCasa demonstrate substantial gains, including an 11.3% improvement on the challenging OOD SimplerEnv benchmark, validating the ability of our approach to robustly ground language in action.
BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Jan 21, 2026Vision-Language-Action (VLA) models have shown promise in robot manipulation but often struggle to generalize to new instructions or complex multi-task scenarios. We identify a critical pathology in current training paradigms where goal-driven data collection creates a dataset bias. In such datasets, language instructions are highly predictable from visual observations alone, causing the conditional mutual information between instructions and actions to vanish, a phenomenon we term Information Collapse. Consequently, models degenerate into vision-only policies that ignore language constraints and fail in out-of-distribution (OOD) settings. To address this, we propose BayesianVLA, a novel framework that enforces instruction following via Bayesian decomposition. By introducing learnable Latent Action Queries, we construct a dual-branch architecture to estimate both a vision-only prior $p(a \mid v)$ and a language-conditioned posterior $π(a \mid v, \ell)$. We then optimize the policy to maximize the conditional Pointwise Mutual Information (PMI) between actions and instructions. This objective effectively penalizes the vision shortcut and rewards actions that explicitly explain the language command. Without requiring new data, BayesianVLA significantly improves generalization. Extensive experiments across on SimplerEnv and RoboCasa demonstrate substantial gains, including an 11.3% improvement on the challenging OOD SimplerEnv benchmark, validating the ability of our approach to robustly ground language in action.
CARLA-Round: A Multi-Factor Simulation Dataset for Roundabout Trajectory Prediction
Jan 17, 2026Accurate trajectory prediction of vehicles at roundabouts is critical for reducing traffic accidents, yet it remains highly challenging due to their circular road geometry, continuous merging and yielding interactions, and absence of traffic signals. Developing accurate prediction algorithms relies on reliable, multimodal, and realistic datasets; however, such datasets for roundabout scenarios are scarce, as real-world data collection is often limited by incomplete observations and entangled factors that are difficult to isolate. We present CARLA-Round, a systematically designed simulation dataset for roundabout trajectory prediction. The dataset varies weather conditions (five types) and traffic density levels (spanning Level-of-Service A-E) in a structured manner, resulting in 25 controlled scenarios. Each scenario incorporates realistic mixtures of driving behaviors and provides explicit annotations that are largely absent from existing datasets. Unlike randomly sampled simulation data, this structured design enables precise analysis of how different conditions influence trajectory prediction performance. Validation experiments using standard baselines (LSTM, GCN, GRU+GCN) reveal traffic density dominates prediction difficulty with strong monotonic effects, while weather shows non-linear impacts. The best model achieves 0.312m ADE on real-world rounD dataset, demonstrating effective sim-to-real transfer. This systematic approach quantifies factor impacts impossible to isolate in confounded real-world datasets. Our CARLA-Round dataset is available at https://github.com/Rebecca689/CARLA-Round.
Anomaly Detection and Generation with Diffusion Models: A Survey
Jun 11, 2025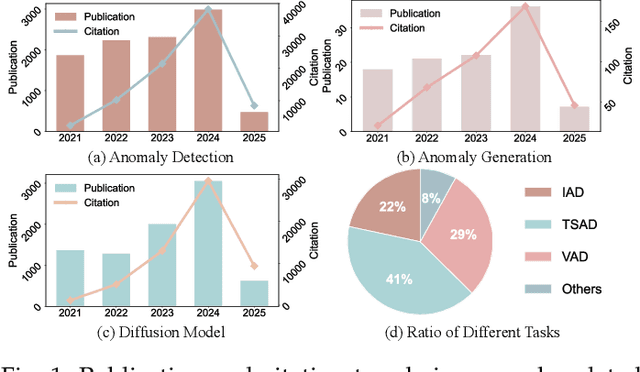

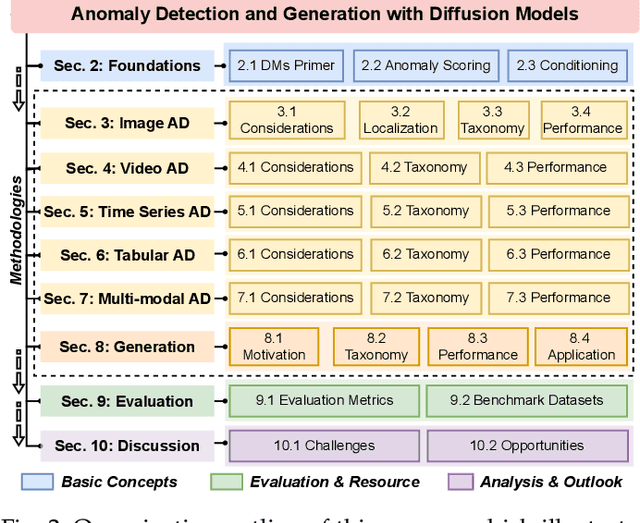

Anomaly detection (AD) plays a pivotal role across diverse domains, including cybersecurity, finance, healthcare, and industrial manufacturing, by identifying unexpected patterns that deviate from established norms in real-world data. Recent advancements in deep learning, specifically diffusion models (DMs), have sparked significant interest due to their ability to learn complex data distributions and generate high-fidelity samples, offering a robust framework for unsupervised AD. In this survey, we comprehensively review anomaly detection and generation with diffusion models (ADGDM), presenting a tutorial-style analysis of the theoretical foundations and practical implementations and spanning images, videos, time series, tabular, and multimodal data. Crucially, unlike existing surveys that often treat anomaly detection and generation as separate problems, we highlight their inherent synergistic relationship. We reveal how DMs enable a reinforcing cycle where generation techniques directly address the fundamental challenge of anomaly data scarcity, while detection methods provide critical feedback to improve generation fidelity and relevance, advancing both capabilities beyond their individual potential. A detailed taxonomy categorizes ADGDM methods based on anomaly scoring mechanisms, conditioning strategies, and architectural designs, analyzing their strengths and limitations. We final discuss key challenges including scalability and computational efficiency, and outline promising future directions such as efficient architectures, conditioning strategies, and integration with foundation models (e.g., visual-language models and large language models). By synthesizing recent advances and outlining open research questions, this survey aims to guide researchers and practitioners in leveraging DMs for innovative AD solutions across diverse applications.
LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
Oct 09, 2024



Language plays a vital role in the realm of human motion. Existing methods have largely depended on CLIP text embeddings for motion generation, yet they fall short in effectively aligning language and motion due to CLIP's pretraining on static image-text pairs. This work introduces LaMP, a novel Language-Motion Pretraining model, which transitions from a language-vision to a more suitable language-motion latent space. It addresses key limitations by generating motion-informative text embeddings, significantly enhancing the relevance and semantics of generated motion sequences. With LaMP, we advance three key tasks: text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. For generation, we utilize LaMP to provide the text condition instead of CLIP, and an autoregressive masked prediction is designed to achieve mask modeling without rank collapse in transformers. For retrieval, motion features from LaMP's motion transformer interact with query tokens to retrieve text features from the text transformer, and vice versa. For captioning, we finetune a large language model with the language-informative motion features to develop a strong motion captioning model. In addition, we introduce the LaMP-BertScore metric to assess the alignment of generated motions with textual descriptions. Extensive experimental results on multiple datasets demonstrate substantial improvements over previous methods across all three tasks. The code of our method will be made public.
DCS-Net: Pioneering Leakage-Free Point Cloud Pretraining Framework with Global Insights
Feb 03, 2024Masked autoencoding and generative pretraining have achieved remarkable success in computer vision and natural language processing, and more recently, they have been extended to the point cloud domain. Nevertheless, existing point cloud models suffer from the issue of information leakage due to the pre-sampling of center points, which leads to trivial proxy tasks for the models. These approaches primarily focus on local feature reconstruction, limiting their ability to capture global patterns within point clouds. In this paper, we argue that the reduced difficulty of pretext tasks hampers the model's capacity to learn expressive representations. To address these limitations, we introduce a novel solution called the Differentiable Center Sampling Network (DCS-Net). It tackles the information leakage problem by incorporating both global feature reconstruction and local feature reconstruction as non-trivial proxy tasks, enabling simultaneous learning of both the global and local patterns within point cloud. Experimental results demonstrate that our method enhances the expressive capacity of existing point cloud models and effectively addresses the issue of information leakage.
MLIP: Enhancing Medical Visual Representation with Divergence Encoder and Knowledge-guided Contrastive Learning
Feb 03, 2024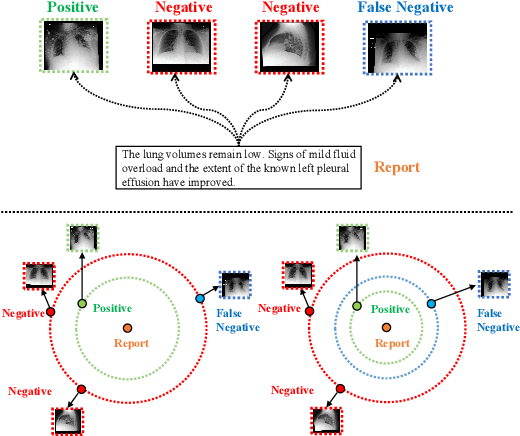



The scarcity of annotated data has sparked significant interest in unsupervised pre-training methods that leverage medical reports as auxiliary signals for medical visual representation learning. However, existing research overlooks the multi-granularity nature of medical visual representation and lacks suitable contrastive learning techniques to improve the models' generalizability across different granularities, leading to the underutilization of image-text information. To address this, we propose MLIP, a novel framework leveraging domain-specific medical knowledge as guiding signals to integrate language information into the visual domain through image-text contrastive learning. Our model includes global contrastive learning with our designed divergence encoder, local token-knowledge-patch alignment contrastive learning, and knowledge-guided category-level contrastive learning with expert knowledge. Experimental evaluations reveal the efficacy of our model in enhancing transfer performance for tasks such as image classification, object detection, and semantic segmentation. Notably, MLIP surpasses state-of-the-art methods even with limited annotated data, highlighting the potential of multimodal pre-training in advancing medical representation learning.
General Point Model with Autoencoding and Autoregressive
Oct 25, 2023The pre-training architectures of large language models encompass various types, including autoencoding models, autoregressive models, and encoder-decoder models. We posit that any modality can potentially benefit from a large language model, as long as it undergoes vector quantization to become discrete tokens. Inspired by GLM, we propose a General Point Model (GPM) which seamlessly integrates autoencoding and autoregressive tasks in point cloud transformer. This model is versatile, allowing fine-tuning for downstream point cloud representation tasks, as well as unconditional and conditional generation tasks. GPM enhances masked prediction in autoencoding through various forms of mask padding tasks, leading to improved performance in point cloud understanding. Additionally, GPM demonstrates highly competitive results in unconditional point cloud generation tasks, even exhibiting the potential for conditional generation tasks by modifying the input's conditional information. Compared to models like Point-BERT, MaskPoint and PointMAE, our GPM achieves superior performance in point cloud understanding tasks. Furthermore, the integration of autoregressive and autoencoding within the same transformer underscores its versatility across different downstream tasks.
MFFN: Multi-view Feature Fusion Network for Camouflaged Object Detection
Oct 19, 2022
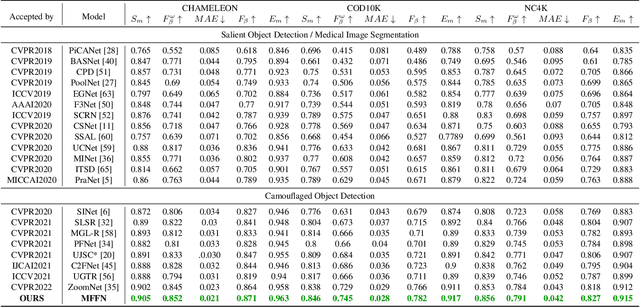
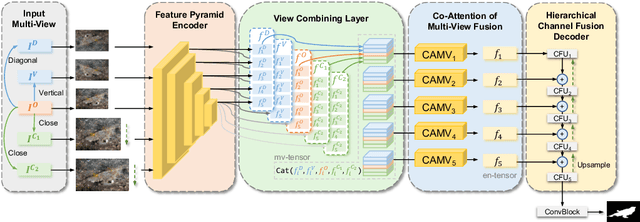

Recent research about camouflaged object detection (COD) aims to segment highly concealed objects hidden in complex surroundings. The tiny, fuzzy camouflaged objects result in visually indistinguishable properties. However, current single-view COD detectors are sensitive to background distractors. Therefore, blurred boundaries and variable shapes of the camouflaged objects are challenging to be fully captured with a single-view detector. To overcome these obstacles, we propose a behavior-inspired framework, called Multi-view Feature Fusion Network (MFFN), which mimics the human behaviors of finding indistinct objects in images, i.e., observing from multiple angles, distances, perspectives. Specifically, the key idea behind it is to generate multiple ways of observation (multi-view) by data augmentation and apply them as inputs. MFFN captures critical boundary and semantic information by comparing and fusing extracted multi-view features. In addition, our MFFN exploits the dependence and interaction between views and channels. Specifically, our methods leverage the complementary information between different views through a two-stage attention module called Co-attention of Multi-view (CAMV). And we design a local-overall module called Channel Fusion Unit (CFU) to explore the channel-wise contextual clues of diverse feature maps in an iterative manner. The experiment results show that our method performs favorably against existing state-of-the-art methods via training with the same data. The code will be available at https://github.com/dwardzheng/MFFN_COD.