 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lossless Ultimate Vision Token Compression for VLMs
Dec 09, 2025Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.
Positional Preservation Embedding for Multimodal Large Language Models
Oct 27, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks, yet often suffer from inefficiencies due to redundant visual tokens. Existing token merging methods reduce sequence length but frequently disrupt spatial layouts and temporal continuity by disregarding positional relationships. In this work, we propose a novel encoding operator dubbed as \textbf{P}ositional \textbf{P}reservation \textbf{E}mbedding (\textbf{PPE}), which has the main hallmark of preservation of spatiotemporal structure during visual token compression. PPE explicitly introduces the disentangled encoding of 3D positions in the token dimension, enabling each compressed token to encapsulate different positions from multiple original tokens. Furthermore, we show that PPE can effectively support cascade clustering -- a progressive token compression strategy that leads to better performance retention. PPE is a parameter-free and generic operator that can be seamlessly integrated into existing token merging methods without any adjustments. Applied to state-of-the-art token merging framework, PPE achieves consistent improvements of $2\%\sim5\%$ across multiple vision-language benchmarks, including MMBench (general vision understanding), TextVQA (layout understanding) and VideoMME (temporal understanding). These results demonstrate that preserving positional cues is critical for efficient and effective MLLM reasoning.
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
Less is More: Focus Attention for Efficient DETR
Jul 24, 2023DETR-like models have significantly boosted the performance of detectors and even outperformed classical convolutional models. However, all tokens are treated equally without discrimination brings a redundant computational burden in the traditional encoder structure. The recent sparsification strategies exploit a subset of informative tokens to reduce attention complexity maintaining performance through the sparse encoder. But these methods tend to rely on unreliable model statistics. Moreover, simply reducing the token population hinders the detection performance to a large extent, limiting the application of these sparse models. We propose Focus-DETR, which focuses attention on more informative tokens for a better trade-off between computation efficiency and model accuracy. Specifically, we reconstruct the encoder with dual attention, which includes a token scoring mechanism that considers both localization and category semantic information of the objects from multi-scale feature maps. We efficiently abandon the background queries and enhance the semantic interaction of the fine-grained object queries based on the scores. Compared with the state-of-the-art sparse DETR-like detectors under the same setting, our Focus-DETR gets comparable complexity while achieving 50.4AP (+2.2) on COCO. The code is available at https://github.com/huawei-noah/noah-research/tree/master/Focus-DETR and https://gitee.com/mindspore/models/tree/master/research/cv/Focus-DETR.
MFFN: Multi-view Feature Fusion Network for Camouflaged Object Detection
Oct 19, 2022
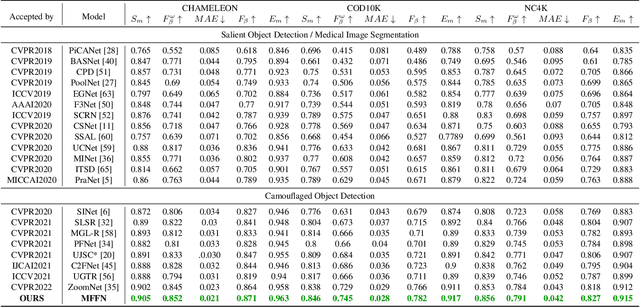
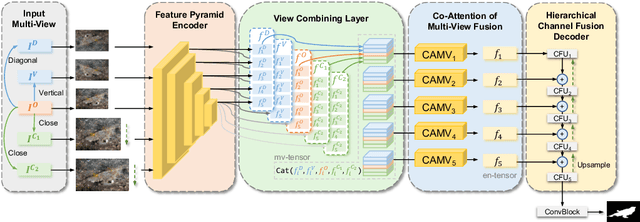

Recent research about camouflaged object detection (COD) aims to segment highly concealed objects hidden in complex surroundings. The tiny, fuzzy camouflaged objects result in visually indistinguishable properties. However, current single-view COD detectors are sensitive to background distractors. Therefore, blurred boundaries and variable shapes of the camouflaged objects are challenging to be fully captured with a single-view detector. To overcome these obstacles, we propose a behavior-inspired framework, called Multi-view Feature Fusion Network (MFFN), which mimics the human behaviors of finding indistinct objects in images, i.e., observing from multiple angles, distances, perspectives. Specifically, the key idea behind it is to generate multiple ways of observation (multi-view) by data augmentation and apply them as inputs. MFFN captures critical boundary and semantic information by comparing and fusing extracted multi-view features. In addition, our MFFN exploits the dependence and interaction between views and channels. Specifically, our methods leverage the complementary information between different views through a two-stage attention module called Co-attention of Multi-view (CAMV). And we design a local-overall module called Channel Fusion Unit (CFU) to explore the channel-wise contextual clues of diverse feature maps in an iterative manner. The experiment results show that our method performs favorably against existing state-of-the-art methods via training with the same data. The code will be available at https://github.com/dwardzheng/MFFN_COD.