 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAgentBoard: Benchmarking Multi-Agent Collaboration with Conventional Methods for Diverse Medical Tasks
May 18, 2025The rapid advancement of Large Language Models (LLMs) has stimulated interest in multi-agent collaboration for addressing complex medical tasks. However, the practical advantages of multi-agent collaboration approaches remain insufficiently understood. Existing evaluations often lack generalizability, failing to cover diverse tasks reflective of real-world clinical practice, and frequently omit rigorous comparisons against both single-LLM-based and established conventional methods. To address this critical gap, we introduce MedAgentBoard, a comprehensive benchmark for the systematic evaluation of multi-agent collaboration, single-LLM, and conventional approaches. MedAgentBoard encompasses four diverse medical task categories: (1) medical (visual) question answering, (2) lay summary generation, (3) structured Electronic Health Record (EHR) predictive modeling, and (4) clinical workflow automation, across text, medical images, and structured EHR data. Our extensive experiments reveal a nuanced landscape: while multi-agent collaboration demonstrates benefits in specific scenarios, such as enhancing task completeness in clinical workflow automation, it does not consistently outperform advanced single LLMs (e.g., in textual medical QA) or, critically, specialized conventional methods that generally maintain better performance in tasks like medical VQA and EHR-based prediction. MedAgentBoard offers a vital resource and actionable insights, emphasizing the necessity of a task-specific, evidence-based approach to selecting and developing AI solutions in medicine. It underscores that the inherent complexity and overhead of multi-agent collaboration must be carefully weighed against tangible performance gains. All code, datasets, detailed prompts, and experimental results are open-sourced at https://medagentboard.netlify.app/.
TAMER: A Test-Time Adaptive MoE-Driven Framework for EHR Representation Learning
Jan 10, 2025



We propose TAMER, a Test-time Adaptive MoE-driven framework for EHR Representation learning. TAMER combines a Mixture-of-Experts (MoE) with Test-Time Adaptation (TTA) to address two critical challenges in EHR modeling: patient population heterogeneity and distribution shifts. The MoE component handles diverse patient subgroups, while TTA enables real-time adaptation to evolving health status distributions when new patient samples are introduced. Extensive experiments across four real-world EHR datasets demonstrate that TAMER consistently improves predictive performance for both mortality and readmission risk tasks when combined with diverse EHR modeling backbones. TAMER offers a promising approach for dynamic and personalized EHR-based predictions in practical clinical settings. Code is publicly available at https://github.com/yhzhu99/TAMER.
ColaCare: Enhancing Electronic Health Record Modeling through Large Language Model-Driven Multi-Agent Collaboration
Oct 03, 2024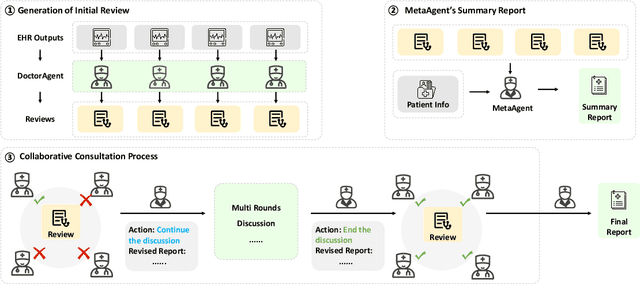
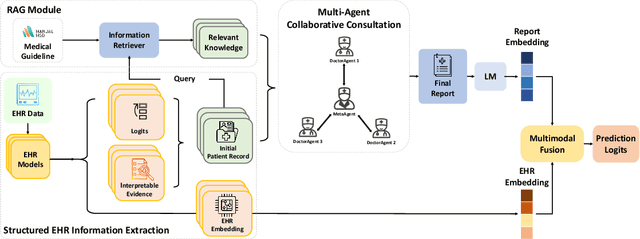

We introduce ColaCare, a framework that enhances Electronic Health Record (EHR) modeling through multi-agent collaboration driven by Large Language Models (LLMs). Our approach seamlessly integrates domain-specific expert models with LLMs to bridge the gap between structured EHR data and text-based reasoning. Inspired by clinical consultations, ColaCare employs two types of agents: DoctorAgent and MetaAgent, which collaboratively analyze patient data. Expert models process and generate predictions from numerical EHR data, while LLM agents produce reasoning references and decision-making reports within the collaborative consultation framework. We additionally incorporate the Merck Manual of Diagnosis and Therapy (MSD) medical guideline within a retrieval-augmented generation (RAG) module for authoritative evidence support. Extensive experiments conducted on four distinct EHR datasets demonstrate ColaCare's superior performance in mortality prediction tasks, underscoring its potential to revolutionize clinical decision support systems and advance personalized precision medicine. The code, complete prompt templates, more case studies, etc. are publicly available at the anonymous link: https://colacare.netlify.app.
Is larger always better? Evaluating and prompting large language models for non-generative medical tasks
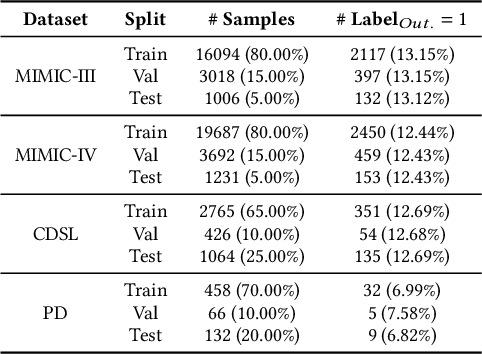
Jul 26, 2024The use of Large Language Models (LLMs) in medicine is growing, but their ability to handle both structured Electronic Health Record (EHR) data and unstructured clinical notes is not well-studied. This study benchmarks various models, including GPT-based LLMs, BERT-based models, and traditional clinical predictive models, for non-generative medical tasks utilizing renowned datasets. We assessed 14 language models (9 GPT-based and 5 BERT-based) and 7 traditional predictive models using the MIMIC dataset (ICU patient records) and the TJH dataset (early COVID-19 EHR data), focusing on tasks such as mortality and readmission prediction, disease hierarchy reconstruction, and biomedical sentence matching, comparing both zero-shot and finetuned performance. Results indicated that LLMs exhibited robust zero-shot predictive capabilities on structured EHR data when using well-designed prompting strategies, frequently surpassing traditional models. However, for unstructured medical texts, LLMs did not outperform finetuned BERT models, which excelled in both supervised and unsupervised tasks. Consequently, while LLMs are effective for zero-shot learning on structured data, finetuned BERT models are more suitable for unstructured texts, underscoring the importance of selecting models based on specific task requirements and data characteristics to optimize the application of NLP technology in healthcare.
EMERGE: Integrating RAG for Improved Multimodal EHR Predictive Modeling
May 27, 2024



The integration of multimodal Electronic Health Records (EHR) data has notably advanced clinical predictive capabilities. However, current models that utilize clinical notes and multivariate time-series EHR data often lack the necessary medical context for precise clinical tasks. Previous methods using knowledge graphs (KGs) primarily focus on structured knowledge extraction. To address this, we propose EMERGE, a Retrieval-Augmented Generation (RAG) driven framework aimed at enhancing multimodal EHR predictive modeling. Our approach extracts entities from both time-series data and clinical notes by prompting Large Language Models (LLMs) and aligns them with professional PrimeKG to ensure consistency. Beyond triplet relationships, we include entities' definitions and descriptions to provide richer semantics. The extracted knowledge is then used to generate task-relevant summaries of patients' health statuses. These summaries are fused with other modalities utilizing an adaptive multimodal fusion network with cross-attention. Extensive experiments on the MIMIC-III and MIMIC-IV datasets for in-hospital mortality and 30-day readmission tasks demonstrate the superior performance of the EMERGE framework compared to baseline models. Comprehensive ablation studies and analyses underscore the efficacy of each designed module and the framework's robustness to data sparsity. EMERGE significantly enhances the use of multimodal EHR data in healthcare, bridging the gap with nuanced medical contexts crucial for informed clinical predictions.
Clustering of Disease Trajectories with Explainable Machine Learning: A Case Study on Postoperative Delirium Phenotypes
May 06, 2024



The identification of phenotypes within complex diseases or syndromes is a fundamental component of precision medicine, which aims to adapt healthcare to individual patient characteristics. Postoperative delirium (POD) is a complex neuropsychiatric condition with significant heterogeneity in its clinical manifestations and underlying pathophysiology. We hypothesize that POD comprises several distinct phenotypes, which cannot be directly observed in clinical practice. Identifying these phenotypes could enhance our understanding of POD pathogenesis and facilitate the development of targeted prevention and treatment strategies. In this paper, we propose an approach that combines supervised machine learning for personalized POD risk prediction with unsupervised clustering techniques to uncover potential POD phenotypes. We first demonstrate our approach using synthetic data, where we simulate patient cohorts with predefined phenotypes based on distinct sets of informative features. We aim to mimic any clinical disease with our synthetic data generation method. By training a predictive model and applying SHAP, we show that clustering patients in the SHAP feature importance space successfully recovers the true underlying phenotypes, outperforming clustering in the raw feature space. We then present a case study using real-world data from a cohort of elderly surgical patients. The results showcase the utility of our approach in uncovering clinically relevant subtypes of complex disorders like POD, paving the way for more precise and personalized treatment strategies.
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
May 04, 2024Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Dynamic Local Attention with Hierarchical Patching for Irregular Clinical Time Series
Nov 13, 2023



Irregular multivariate time series data is prevalent in the clinical and healthcare domains. It is characterized by time-wise and feature-wise irregularities, making it challenging for machine learning methods to work with. To solve this, we introduce a new model architecture composed of two modules: (1) DLA, a Dynamic Local Attention mechanism that uses learnable queries and feature-specific local windows when computing the self-attention operation. This results in aggregating irregular time steps raw input within each window to a harmonized regular latent space representation while taking into account the different features' sampling rates. (2) A hierarchical MLP mixer that processes the output of DLA through multi-scale patching to leverage information at various scales for the downstream tasks. Our approach outperforms state-of-the-art methods on three real-world datasets, including the latest clinical MIMIC IV dataset.
SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting
Mar 31, 2023



Contrastive learning methods have shown an impressive ability to learn meaningful representations for image or time series classification. However, these methods are less effective for time series forecasting, as optimization of instance discrimination is not directly applicable to predicting the future state from the history context. Moreover, the construction of positive and negative pairs in current technologies strongly relies on specific time series characteristics, restricting their generalization across diverse types of time series data. To address these limitations, we propose SimTS, a simple representation learning approach for improving time series forecasting by learning to predict the future from the past in the latent space. SimTS does not rely on negative pairs or specific assumptions about the characteristics of the particular time series. Our extensive experiments on several benchmark time series forecasting datasets show that SimTS achieves competitive performance compared to existing contrastive learning methods. Furthermore, we show the shortcomings of the current contrastive learning framework used for time series forecasting through a detailed ablation study. Overall, our work suggests that SimTS is a promising alternative to other contrastive learning approaches for time series forecasting.
Rare Wildlife Recognition with Self-Supervised Representation Learning
Oct 29, 2022Automated animal censuses with aerial imagery are a vital ingredient towards wildlife conservation. Recent models are generally based on supervised learning and thus require vast amounts of training data. Due to their scarcity and minuscule size, annotating animals in aerial imagery is a highly tedious process. In this project, we present a methodology to reduce the amount of required training data by resorting to self-supervised pretraining. In detail, we examine a combination of recent contrastive learning methodologies like Momentum Contrast (MoCo) and Cross-Level Instance-Group Discrimination (CLD) to condition our model on the aerial images without the requirement for labels. We show that a combination of MoCo, CLD, and geometric augmentations outperforms conventional models pretrained on ImageNet by a large margin. Meanwhile, strategies for smoothing label or prediction distribution in supervised learning have been proven useful in preventing the model from overfitting. We combine the self-supervised contrastive models with image mixup strategies and find that it is useful for learning more robust visual representations. Crucially, our methods still yield favorable results even if we reduce the number of training animals to just 10%, at which point our best model scores double the recall of the baseline at similar precision. This effectively allows reducing the number of required annotations to a fraction while still being able to train high-accuracy models in such highly challenging settings.