 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagical: Medical Lay Language Generation via Semantic Invariance and Layperson-tailored Adaptation
Aug 12, 2025
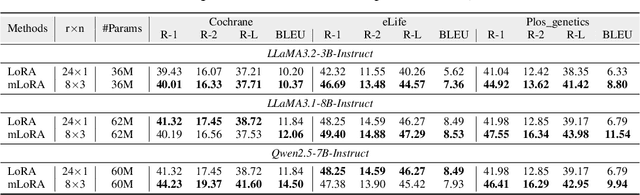
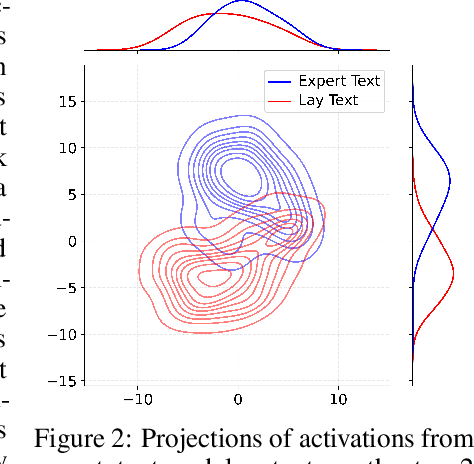
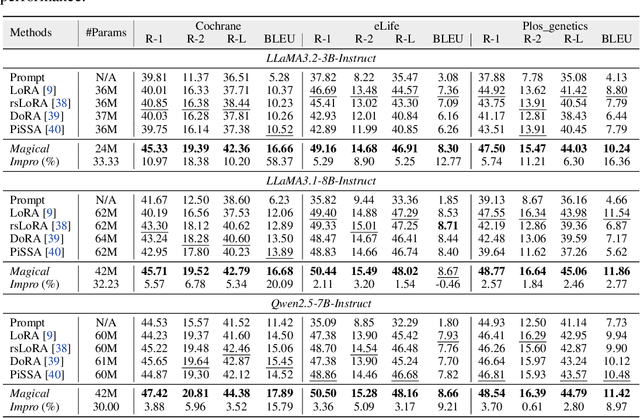
Medical Lay Language Generation (MLLG) plays a vital role in improving the accessibility of complex scientific content for broader audiences. Recent literature to MLLG commonly employ parameter-efficient fine-tuning methods such as Low-Rank Adaptation (LoRA) to fine-tuning large language models (LLMs) using paired expert-lay language datasets. However, LoRA struggles with the challenges posed by multi-source heterogeneous MLLG datasets. Specifically, through a series of exploratory experiments, we reveal that standard LoRA fail to meet the requirement for semantic fidelity and diverse lay-style generation in MLLG task. To address these limitations, we propose Magical, an asymmetric LoRA architecture tailored for MLLG under heterogeneous data scenarios. Magical employs a shared matrix $A$ for abstractive summarization, along with multiple isolated matrices $B$ for diverse lay-style generation. To preserve semantic fidelity during the lay language generation process, Magical introduces a Semantic Invariance Constraint to mitigate semantic subspace shifts on matrix $A$. Furthermore, to better adapt to diverse lay-style generation, Magical incorporates the Recommendation-guided Switch, an externally interface to prompt the LLM to switch between different matrices $B$. Experimental results on three real-world lay language generation datasets demonstrate that Magical consistently outperforms prompt-based methods, vanilla LoRA, and its recent variants, while also reducing trainable parameters by 31.66%.
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
Jan 24, 2025We introduce DRESS, a novel approach for generating stylized large language model (LLM) responses through representation editing. Existing methods like prompting and fine-tuning are either insufficient for complex style adaptation or computationally expensive, particularly in tasks like NPC creation or character role-playing. Our approach leverages the over-parameterized nature of LLMs to disentangle a style-relevant subspace within the model's representation space to conduct representation editing, ensuring a minimal impact on the original semantics. By applying adaptive editing strengths, we dynamically adjust the steering vectors in the style subspace to maintain both stylistic fidelity and semantic integrity. We develop two stylized QA benchmark datasets to validate the effectiveness of DRESS, and the results demonstrate significant improvements compared to baseline methods such as prompting and ITI. In short, DRESS is a lightweight, train-free solution for enhancing LLMs with flexible and effective style control, making it particularly useful for developing stylized conversational agents. Codes and benchmark datasets are available at https://github.com/ArthurLeoM/DRESS-LLM.
ColaCare: Enhancing Electronic Health Record Modeling through Large Language Model-Driven Multi-Agent Collaboration
Oct 03, 2024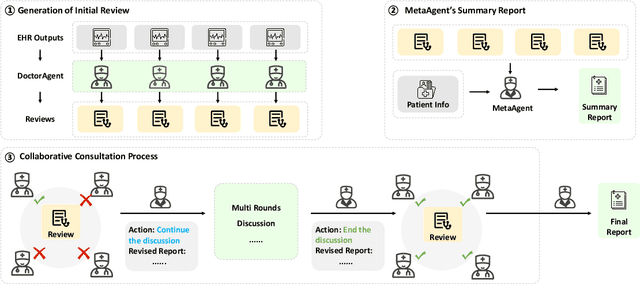
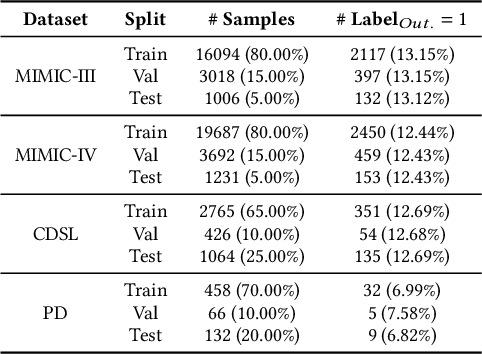
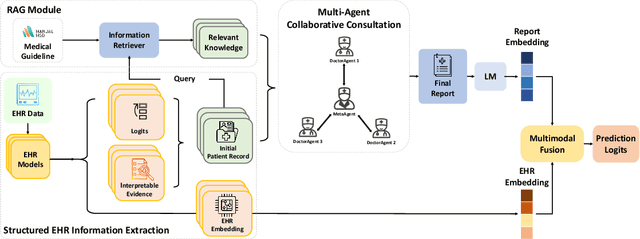

We introduce ColaCare, a framework that enhances Electronic Health Record (EHR) modeling through multi-agent collaboration driven by Large Language Models (LLMs). Our approach seamlessly integrates domain-specific expert models with LLMs to bridge the gap between structured EHR data and text-based reasoning. Inspired by clinical consultations, ColaCare employs two types of agents: DoctorAgent and MetaAgent, which collaboratively analyze patient data. Expert models process and generate predictions from numerical EHR data, while LLM agents produce reasoning references and decision-making reports within the collaborative consultation framework. We additionally incorporate the Merck Manual of Diagnosis and Therapy (MSD) medical guideline within a retrieval-augmented generation (RAG) module for authoritative evidence support. Extensive experiments conducted on four distinct EHR datasets demonstrate ColaCare's superior performance in mortality prediction tasks, underscoring its potential to revolutionize clinical decision support systems and advance personalized precision medicine. The code, complete prompt templates, more case studies, etc. are publicly available at the anonymous link: https://colacare.netlify.app.
CPL: Critical Planning Step Learning Boosts LLM Generalization in Reasoning Tasks
Sep 13, 2024



Post-training large language models (LLMs) to develop reasoning capabilities has proven effective across diverse domains, such as mathematical reasoning and code generation. However, existing methods primarily focus on improving task-specific reasoning but have not adequately addressed the model's generalization capabilities across a broader range of reasoning tasks. To tackle this challenge, we introduce Critical Planning Step Learning (CPL), which leverages Monte Carlo Tree Search (MCTS) to explore diverse planning steps in multi-step reasoning tasks. Based on long-term outcomes, CPL learns step-level planning preferences to improve the model's planning capabilities and, consequently, its general reasoning capabilities. Furthermore, while effective in many scenarios for aligning LLMs, existing preference learning approaches like Direct Preference Optimization (DPO) struggle with complex multi-step reasoning tasks due to their inability to capture fine-grained supervision at each step. We propose Step-level Advantage Preference Optimization (Step-APO), which integrates an advantage estimate for step-level preference pairs obtained via MCTS into the DPO. This enables the model to more effectively learn critical intermediate planning steps, thereby further improving its generalization in reasoning tasks. Experimental results demonstrate that our method, trained exclusively on GSM8K and MATH, not only significantly improves performance on GSM8K (+10.5%) and MATH (+6.5%), but also enhances out-of-domain reasoning benchmarks, such as ARC-C (+4.0%), BBH (+1.8%), MMLU-STEM (+2.2%), and MMLU (+0.9%).
Adaptive Activation Steering: A Tuning-Free LLM Truthfulness Improvement Method for Diverse Hallucinations Categories
May 26, 2024Recent studies have indicated that Large Language Models (LLMs) harbor an inherent understanding of truthfulness, yet often fail to express fully and generate false statements. This gap between "knowing" and "telling" poses a challenge for ensuring the truthfulness of generated content. To address this, we introduce Adaptive Activation Steering (ACT), a tuning-free method that adaptively shift LLM's activations in "truthful" direction during inference. ACT addresses diverse categories of hallucinations by utilizing diverse steering vectors and adjusting the steering intensity adaptively. Applied as an add-on across various models, ACT significantly improves truthfulness in LLaMA ($\uparrow$ 142\%), LLaMA2 ($\uparrow$ 24\%), Alpaca ($\uparrow$ 36\%), Vicuna ($\uparrow$ 28\%), and LLaMA2-Chat ($\uparrow$ 19\%). Furthermore, we verify ACT's scalability across larger models (13B, 33B, 65B), underscoring the adaptability of ACT to large-scale language models.
A Transfer-Learning-Based Prognosis Prediction Paradigm that Bridges Data Distribution Shift across EMR Datasets
Oct 11, 2023Due to the limited information about emerging diseases, symptoms are hard to be noticed and recognized, so that the window for clinical intervention could be ignored. An effective prognostic model is expected to assist doctors in making right diagnosis and designing personalized treatment plan, so to promptly prevent unfavorable outcomes. However, in the early stage of a disease, limited data collection and clinical experiences, plus the concern out of privacy and ethics, may result in restricted data availability for reference, to the extent that even data labels are difficult to mark correctly. In addition, Electronic Medical Record (EMR) data of different diseases or of different sources of the same disease can prove to be having serious cross-dataset feature misalignment problems, greatly mutilating the efficiency of deep learning models. This article introduces a transfer learning method to build a transition model from source dataset to target dataset. By way of constraining the distribution shift of features generated in disparate domains, domain-invariant features that are exclusively relative to downstream tasks are captured, so to cultivate a unified domain-invariant encoder across various task domains to achieve better feature representation. Experimental results of several target tasks demonstrate that our proposed model outperforms competing baseline methods and has higher rate of training convergence, especially in dealing with limited data amount. A multitude of experiences have proven the efficacy of our method to provide more accurate predictions concerning newly emergent pandemics and other diseases.